Wanneer een machine learning model getraind wordt, is het cruciaal om de uiteindelijke model-performantie na te gaan. Dat houdt specifiek de vraag in of het model er al dan niet in slaagt om bruikbare taak-outputs te genereren bij nieuwe data. Dit is het domein van modelevaluatie. Bij die evaluatie worden de prestaties van een model geëvalueerd op basis van performantiematen; beter bekend als scoring metrics.
Als er een loss functie gebruikt wordt tijdens het trainen, geeft de waarde daarvan een eerste indicatie van de model-performantie. De loss functie geeft echter niet noodzakelijk rechtstreeks een zicht op taakprestaties. Daarom worden tal van andere _ scoring metrics_ gebruikt, afhankelijk van de specifieke taak.
We zullen zien dat er verschillende metrics gangbaar zijn, afhankelijk van de taakcontext (bv. klassificatie, regressie, enz.) en het specifieke domein (bv. computervisie, NLP, enz.; zie scikit-learn metrics module en scikit-learn scoring guide).
Precision & Recall
In de context van klassificatie, kijken we in de eerste plaats naar de accuracy score; het percentage juist voorspelde categorieën.
In onderstaande confusion matrix is de accuracy
Voorspeld
Kat Hond Vogel
Werkelijk Kat 45 3 2
Hond 2 38 1
Vogel 1 4 35Daarnaast wordt bij binaire klassificatie (bv. Kat|hond) ook gekeken naar de verdeling van het aantal true positives (TP), false positives (FP), true negatives (TN) en false negatives (FN).
Voorspeld
Kat(+) Hond(-)
Werkelijk Kat(+) 45 3
Hond(-) 2 38, , en
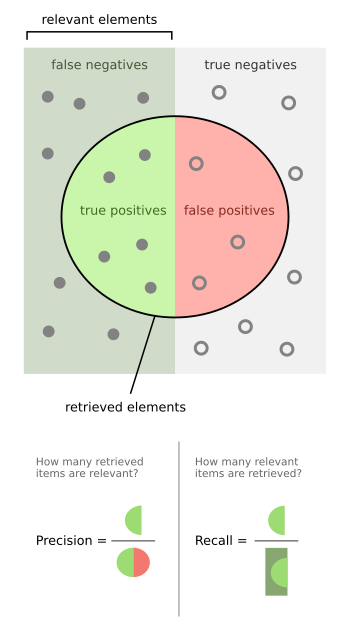
Hieraan worden drie metrics gekoppeld:
Precision: Fractie van positieve voorspellingen die correct zijn
Recall: Fractie van positieve instances die correct geïdentificeerd zijn
-score: Harmonisch gemiddelde van precision en recall. De score groeit symmetrisch met toenemende precision of recall.
Een algemenere maat is de waarbij een gewicht wordt toegekend om precision meer of minder belang te geven ten opzichte van recall.
Training, validatie en testing¶
Om zeker te zijn dat een model patronen leert te herkennen en niet gewoon de trainingsdata van buiten leert, is het cruciaal om de prestaties te evalueren op ongeziene data. De capaciteit om juiste voorspellingen te maken met nieuwe data wordt algemeen de generalisatie capaciteit van het model genoemd. Er wordt in die context standaard een onderscheid gemaakt tussen drie groepen data:
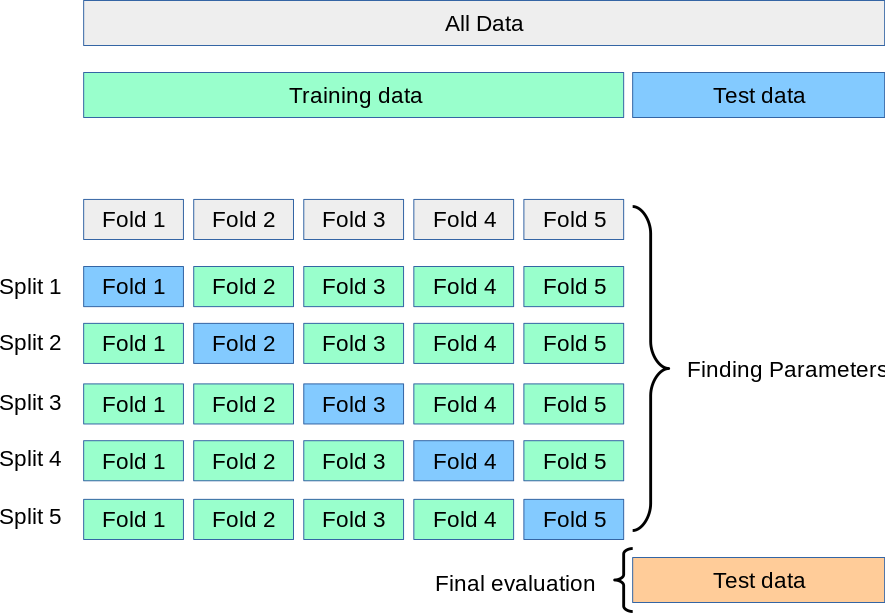
Trainingsdata: dit is de bulk van de data (bv. 70%) waarmee we ons leeralgoritme effectief laten werken om de optimale modelparameters te vinden.
Validatiedata: dit is een kleiner stuk van de data (bv.20%) waarmee we tijdens de training en hyper parameter tuning evalueren hoe het model presteert op ongeziene data.
Testdata: dit is een (meestal nog) kleiner stuk van de data (bv. 10%) dat volledig opzij gehouden wordt. Het model kan nooit (rechtstreeks of onrechtstreeks) beïnvloed worden door deze data tijdens de training. Ze dienen om de generalisatie capaciteit van het model finaal te kwantificeren.
Vaak wordt met een meer geavanceerde vorm van validatie gewerkt: zogenaamde K-Fold Cross-validatie. In plaats van één stuk data opzij te houden als validatie data, wordt de trainingsdata in K gelijke delen op gesplitst. Het model wordt dan bij iedere tussenstap K keer getraind met K-1 delen en gevalideerd met het overige deel.
Explainability¶
Bij de evaluatie van modellen is het zaak om ook inzicht te krijgen in de effectieve patronen die geleerd zijn en hoe een model, gegeven concrete inputs, tot bepaalde voorspellingen komt. Dit is bij bepaalde toepassingen (bv. medische diagnostiek) cruciaal. Zoals we zullen zien in de secties over concrete toepassingsdomeinen, is dit, afhankelijk van het type model, niet altijd even evident.