Het leren bij machine learning gebeurt aan de hand van een bepaald leeralgoritme mits blootstelling aan voldoende data. Er zijn drie grote families leeralgoritmes afhankelijk van de soort blootstelling of manier waarop er ervaring kan opgedaan worden: supervised, unsupervised en reinforcement learning. Ze verschillen specifiek van elkaar naargelang de manier waarop de zoektocht naar optimale parameterwaarden gestuurd wordt.
Supervised learning¶
Bij supervised learning is het de bedoeling dat het model leert om, bij een gegeven input, een specifieke output te geven die vooraf vastligt. In de training data zijn zogenaamde ground truth waarden of targetwaarden aanwezig. Die geven voor iedere input aan wat de gewenste (target) output is. Supervised learning is veruit het meest gebruikte type leeralgoritme. Het is vaak heel efficiënt omdat, tijdens het trainen, aan iedere individuele output een score toegekend kan worden van waaruit een “richting” kan worden afgeleid in de zoektocht naar optimale parameterwaarden. Meer algemeen gesteld, kan er dus rechtstreeks geleerd (of ervaring opgedaan) worden over wat de gewenste model output moet zijn bij een bepaalde input.
In de context van beeldherkenning, is supervised learning lange tijd de gouden standaard geweest. Het bekomen van ground truth waarden is hier ook lange tijd een kwestie geweest van 100% manuele inspanningen. Het proces om ground truth of targetwaarden te voorzien voor supervised learning heet algemeen: data-annotatie.
Self-supervised learning¶
Dit is een variant van supervised learning waarbij de targetwaarde of ground truth in de data zelf vervat zit. Dit is een standaard bij taalmodellen die next word prediction doen. Het model doet een voorspelling voor het volgende woord en die voorspelling kan dan direct vergeleken worden met het effectieve volgende woord in de trainingsdata.
Source
import matplotlib.pyplot as plt
import numpy as np
import torch
import torchvision
from torchvision import transformsSource
transform = transforms.Compose(
[transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]
)
batch_size = 4
trainset = torchvision.datasets.CIFAR10(
root="./data", train=True, download=True, transform=transform
)
trainloader = torch.utils.data.DataLoader(
trainset, batch_size=batch_size, shuffle=True, num_workers=2
)
testset = torchvision.datasets.CIFAR10(
root="./data", train=False, download=True, transform=transform
)
testloader = torch.utils.data.DataLoader(
testset, batch_size=batch_size, shuffle=False, num_workers=2
)
classes = ("plane", "car", "bird", "cat", "deer", "dog", "frog", "horse", "ship", "truck")
def imshow(img):
"""
Display an image tensor after unnormalizing it.
Args:
img (torch.Tensor): Image tensor to display.
"""
img = img / 2 + 0.5 # unnormalize
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
# get some random training images
dataiter = iter(trainloader)
images, labels = next(dataiter)
# show images
imshow(torchvision.utils.make_grid(images))
# print labels
print(" ".join(f"{classes[labels[j]]:5s}" for j in range(batch_size)))100%|██████████| 170M/170M [00:45<00:00, 3.77MB/s]

truck frog dog deer
Unsupervised learning¶
Bij unsupervised learning is ervaring gebaseerd op pure blootstelling aan data. In tegenstelling tot supervised learning, is er op voorhand géén informatie beschikbaar over de gewenste output bij een gegeven input. Het leerobjectief bestaat eruit om data volgens bepaalde principes te structureren.
Een populair voorbeeld is K-means clustering waarbij parameters worden gezocht om data volgens bepaalde principes van gelijkenis in een vooraf bepaald aantal clusters in te delen.
Source
from sklearn.cluster import KMeans
from sklearn.datasets import load_iris
# Laad de iris dataset (zonder labels te gebruiken)
iris = load_iris()
X = iris.data[:, 2:] # gebruik alleen petal length en petal width
# K-means met 3 clusters
kmeans = KMeans(n_clusters=3, random_state=42, n_init=10)
kmeans.fit(X)
# Visualiseer de clusters
plt.figure(figsize=(8, 6))
plt.scatter(X[:, 0], X[:, 1], c=kmeans.labels_, cmap="viridis", alpha=0.6)
plt.scatter(
kmeans.cluster_centers_[:, 0],
kmeans.cluster_centers_[:, 1],
c="red",
marker="X",
s=200,
edgecolors="black",
label="Centroids",
)
plt.xlabel("Petal Length (cm)")
plt.ylabel("Petal Width (cm)")
plt.title("K-means Clustering | Iris Dataset")
plt.legend()
plt.show()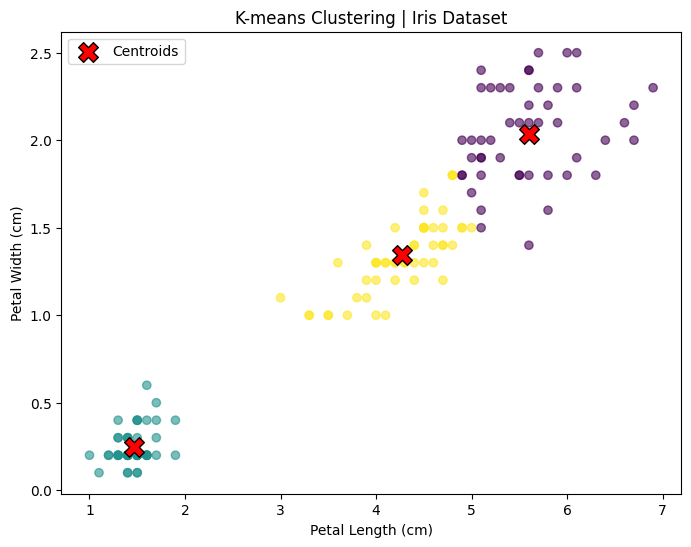
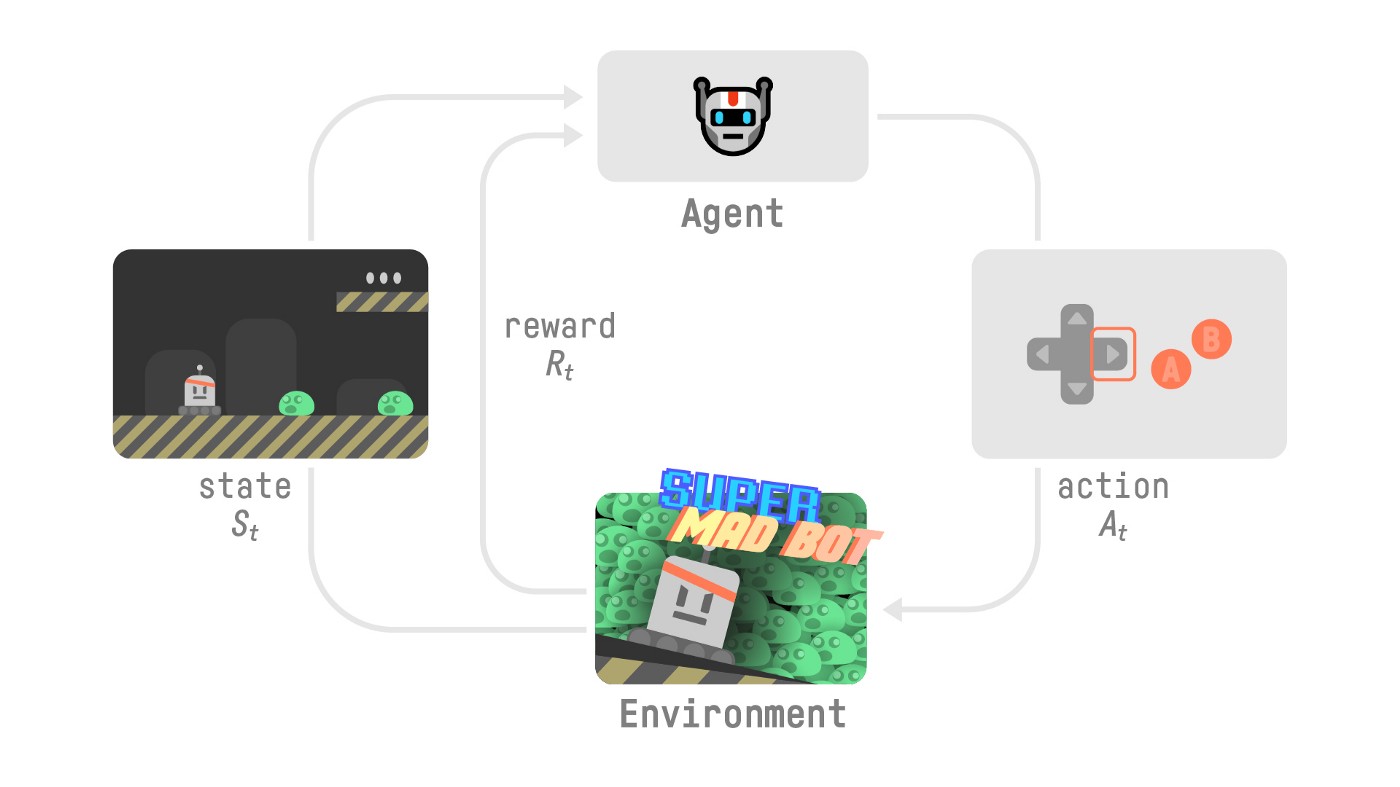
Reinforcement learning¶
Bij reinforcement learning is er tijdens het leren een interactie met een omgeving. Er is een feedback loop tussen het model en de ervaring die het kan opdoen. Zoals bij unsupervised learning is er geen rechtstreekse informatie over de juistheid van individuele model outputs. Er is echter wel een onrechtstreekse inschatting van de wenselijkheid van een individuele output onder de vorm van een zgn. reward functie. Deze familie van leeralgoritmes wordt gebruikt in de context van actie-planning taken toepassingen waarbij model outputs de vorm hebben van sequentiële acties binnen een al dan niet gesimuleerde omgeving. Er wordt geen rechtstreekse evaluatie gedaan van actie-sequenties ten op zichtte van overeenkomstige targets, maar de uitkomst van actie-sequenties wordt wel gescoord ten op zichtte van vooraf gedefinieerde doelstellingen binnen de omgeving.