Lineaire regressie is een centraal model binnen Machine Learning. Om de wiskunde van ML te begrijpen is het een absolute must om dit model - en vooral ook de geassocieerde leeralgoritmes - ten volle te doorgronden. Het model komt uit de statistiek en veronderstelt dat bepaalde target data (“responsvariabele(n)” genoemd in de statistiek) in lineair verband staan met één of meerdere features (ook wel “predictoren” genoemd in de de statistiek).
Data simulatie¶
We beginnen met de simulatie van een simpele situatie. Stel dat er in een ideale wereld (voor koffiehuizen) een lineaire relatie bestaat tussen de grootte van een bestelling en de fooi die klanten erbovenop betalen:
waarbij de grootte van de fooi is, een basis fooi en een multiplicatie factor voor de prijs van de aankoop.
Het probleem dat we willen oplossen is het achterhalen van en .
We verzamelen daarvoor data van 50 aankopen en houden er rekening mee dat er een meetfout zal zijn: de lineaire relatie zal niet altijd perfect zijn.
Ons model voor de data is het volgende:
met
We gaan ervan uit dat ieder data punt een additieve ruis component heeft:
met als verwachtte waarde 0 bij een oneindig aantal observaties:
Wat impliceert:
Om data te simuleren gebruikten we de volgende waarden voor de modelparameters:
De ruis simuleren we door steekproeven te nemen uit een normale (Gauss) verdeling met gemiddelde 0 en standaardafwijking [1]:
Voor de grootte van de orders te simuleren, trekken we 50 samples uit een uniforme verdeling[1] met de volgende parameters.
Source
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import plotly.express as px
from ml_courses.sim.linear_regression_sse_viz import LinearRegressionSSEVisualizerSource
rng = np.random.default_rng(42) # Create a random number generator
# Set style for prettier plots
plt.style.use("seaborn-v0_8")
# Simulate realistic coffee shop data
n_customers = 50
# True relationship: people generally tip ~15% plus a small base amount
true_tip_rate = 0.15 # 15% of order total
true_base_tip = 0.50 # $0.50 base tip regardless of order size
tip_noise_std = 0.30 # Some randomness in tipping behavior
# Generate realistic order totals ($3 to $25)
order_totals = rng.uniform(3, 25, n_customers)
order_totals = np.sort(order_totals) # Sort for nicer visualization
# Generate corresponding tip amounts with realistic noise
true_tips = true_tip_rate * order_totals + true_base_tip
tip_noise = rng.normal(0, tip_noise_std, n_customers)
observed_tips = np.maximum(0, true_tips + tip_noise) # Tips can't be negative
print("☕ COFFEE SHOP TIPPING ANALYSIS")
print(f"True relationship: Tip = ${true_base_tip:.2f} + {true_tip_rate:.1%} × Order Total")
print(f"We collected data from {n_customers} customers")
print(f"Order range: ${order_totals.min():.2f} - ${order_totals.max():.2f}")
print(f"Tip range: ${observed_tips.min():.2f} - ${observed_tips.max():.2f}")
# Plot the coffee shop data
plt.figure(figsize=(10, 6))
plt.scatter(
order_totals,
observed_tips,
alpha=0.7,
color="saddlebrown",
s=60,
edgecolor="white",
linewidth=0.5,
label="Customer tips",
)
plt.plot(
order_totals,
true_tips,
"r--",
linewidth=2,
label=f"True relationship (${true_base_tip:.2f} + {true_tip_rate:.1%} × order)",
)
plt.xlabel("Order Total ($)")
plt.ylabel("Tip Amount ($)")
plt.title("☕ Order Size vs Tips")
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
# Quick stats for context
avg_tip_percent = np.mean(observed_tips / order_totals) * 100
print("\n📊 Quick stats:")
print(f"Average tip percentage: {avg_tip_percent:.1f}%")
print(
f"Most generous tip: ${observed_tips.max():.2f} (on ${order_totals[np.argmax(observed_tips)]:.2f} order)"
)
print(
f"Most modest tip: ${observed_tips.min():.2f} (on ${order_totals[np.argmin(observed_tips)]:.2f} order)"
)☕ COFFEE SHOP TIPPING ANALYSIS
True relationship: Tip = $0.50 + 15.0% × Order Total
We collected data from 50 customers
Order range: $3.96 - $24.46
Tip range: $0.94 - $3.90
/opt/venv/lib/python3.10/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 9749 (\N{HOT BEVERAGE}) missing from font(s) Liberation Sans.
fig.canvas.print_figure(bytes_io, **kw)
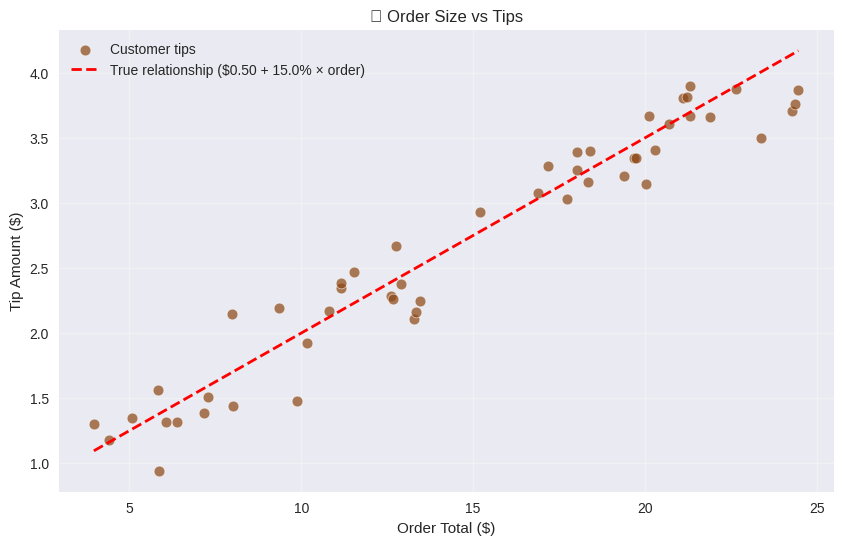
📊 Quick stats:
Average tip percentage: 19.1%
Most generous tip: $3.90 (on $21.31 order)
Most modest tip: $0.94 (on $5.86 order)
Loss functie: ¶
Definitie
De Loss functie is de wiskundige functie die de sub-optimaliteit uitdrukt van parameterschattingen in een bepaalde context. Het doel van het optimalisatie-algorithme is om de output van die functie te minimaliseren.[2]
Om het leeralgoritme sturen, kiezen we hier voor de Sum of Squared Errors () functie[2]:
waarbij
De vector -hoedje () staat voor onze voorspelde waarden voor de eigenlijke fooien op basis van onze schattingen voor de parameters (de argumenten van de functie ) op een bepaald moment in het leerproces.
Squared loss
Merk op dat we de loss kunnen schrijven als:
als we het verschil tussen geobserveerde fooi en geschatte fooi aanduiden met , krijgen we:
Terugkijkend naar de definitie van de Euclidische norm (; ), volgt dat de loss overeenkomt met het kwadraat van de norm van de vector van verschillen tussen geobserveerde waarden en geschatte waarden .
Mean Squared Error () loss
In de praktijk wordt vaak met het gemiddelde van de gekwadrateerde verschillen gewerkt, de zogeheten Mean Squared Error () loss:
of
is dus identiek aan , op de factor na. Bij de wiskundige uiteenzettingen gebruiken we omwille van eenvoud in notatie. In de praktijk verkiezen we wegens het risico op overflow error bij .
De bedoeling van het leeralgoritme is dus om op zoek te gaan naar waarden voor de model parameters die minimaliseren.
Source
def calculate_loss(b1, b2, x, y):
"""
Calculate how badly our guessed relationship predicts actual tips.
Parameters
----------
b1 : float
The base tip amount in dollars
b2 : float
The percentage rate (e.g., 0.15 for 15%)
x : array
Customer order amounts
y : array
Actual tips customers left
Returns
-------
float : sum of squared prediction errors (lower = better)
"""
y_hat = b1 + b2 * x
d = y - y_hat
loss = np.sum(d**2) # Sum of squared errors
return lossSource
# Define the guessed parameters
b1_guess = 1.5 # Base tip guess
b2_guess = 0.05 # Tip rate guess
# Calculate predicted values using the guessed parameters
predicted_tips = b1_guess + b2_guess * order_totals
# Calculate the SSE loss for these parameters
guess_loss = calculate_loss(b1_guess, b2_guess, order_totals, observed_tips)
# Create the visualization
plt.figure(figsize=(10, 6))
# Plot the observed data points
plt.scatter(
order_totals,
observed_tips,
alpha=0.7,
color="saddlebrown",
s=60,
edgecolor="white",
linewidth=0.5,
label="Customer tips",
)
# Plot true relationship
plt.plot(
order_totals,
true_tips,
"r--",
linewidth=2,
label=f"True relationship (${true_base_tip:.2f} + {true_tip_rate:.1%} × order)",
)
# Plot the guessed relationship line (green)
plt.plot(
order_totals,
predicted_tips,
"g-",
linewidth=2,
label=f"Guessed relationship (${b1_guess:.2f} + {b2_guess:.1f} × order)",
)
# Add error lines from each point to the green line
for i in range(len(order_totals)):
plt.plot(
[order_totals[i], order_totals[i]],
[observed_tips[i], predicted_tips[i]],
"r--",
alpha=0.6,
linewidth=1,
)
# Formatting
plt.xlabel("Order Total ($)")
plt.ylabel("Tip Amount ($)")
plt.title("☕ Order Size vs Tips - Showing Prediction Errors")
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
# Print the loss value
print(
f"📊 SSE Loss with guessed parameters (b1=${b1_guess:.2f}, b2={b2_guess:.1f}): {guess_loss:.2f}"
)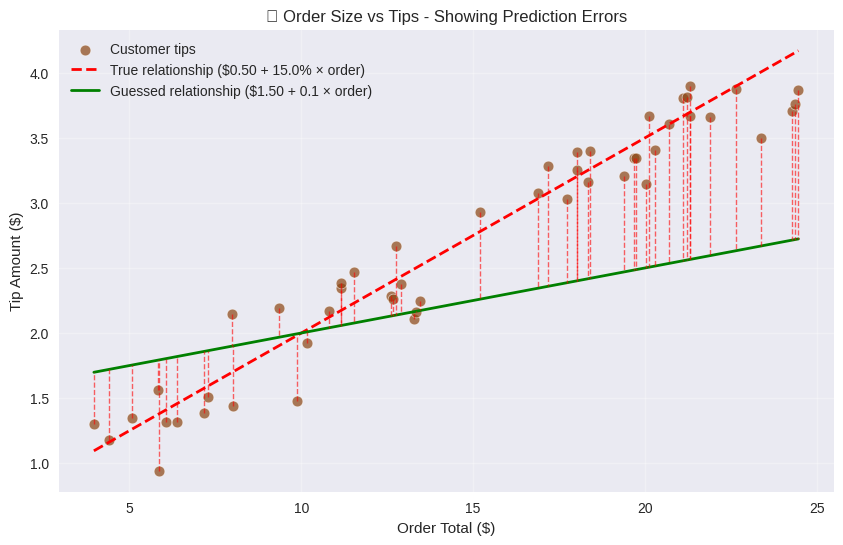
📊 SSE Loss with guessed parameters (b1=$1.50, b2=0.1): 27.65
Visualisatie van het oppervlak¶
We kunnen in deze éénvoudige simulatie met 2 parameters ( en ), de loss functie voorstellen als een 3D oppervlak: . We maken:
een grid van coördinaten ,
berekenen de overeenkomstige (als -coördinaat) en
stellen de resulterende 3D coördinaten voor als een oppervlak.
Source
viz = LinearRegressionSSEVisualizer(
x_data=order_totals,
y_data=observed_tips,
true_bias=true_base_tip,
true_slope=true_tip_rate,
)
fig = viz.create_3d_surface_plot(resolution=40)
fig.show()# Standardize the data
order_totals_mean = np.mean(order_totals)
order_totals_std = np.std(order_totals)
order_totals_scaled = (order_totals - order_totals_mean) / order_totals_std
observed_tips_mean = np.mean(observed_tips)
observed_tips_std = np.std(observed_tips)
observed_tips_scaled = (observed_tips - observed_tips_mean) / observed_tips_stdSource
# Visualize standardization
px.histogram(
pd.DataFrame(
{
"Scaled": np.concat(
(np.full(observed_tips.shape, False), np.full(observed_tips.shape, True))
),
"Order Total": np.concatenate((order_totals, order_totals_scaled)),
}
),
x="Order Total",
color="Scaled",
title="Distribution of Order Totals: Original vs Standardized",
nbins=50,
marginal="rug",
width=800,
)Source
viz = LinearRegressionSSEVisualizer(
x_data=order_totals,
y_data=observed_tips,
true_bias=true_base_tip,
true_slope=true_tip_rate,
standardize=True,
)
fig = viz.create_3d_surface_plot(resolution=40)
fig.show()Grid parameter search¶
In de visualisatie is het coördinaat waar de het kleinst is in het groen aangeduid. Zeker in de geschaalde versie kan je zien dat de langs alle zijden van dit punt oploopt. Er is één absoluut minimum en geen lokale minima. Een oppervlak met dergelijke eigenschappen wordt een convexe oppervlakte genoemd. Het minimum komt hier overeen met en . Dit ligt in de buurt van onze simulatie parameters (, ). De enige afwijking is te wijten aan onze keuze van spacing in het grid. Deze brute force methode om aan de hand van een -D parameter grid het minimum van de loss functie te zoeken is op zich een leeralgoritme en wordt grid search genoemd.
Voordeel¶
Geen complexe wiskunde nodig.
Nadeel¶
We weten normaal niet op voorhand in welke range we moeten werken voor een bepaalde parameter. Zeker wanneer het aantal parameters stijgt, wordt het snel een onmogelijke opdracht om grid search toe te passen - ook vanuit computationeel perspectief. Je komt de techniek het vaakst tegen bij hyper parameter tuning als het aantal hyper parameters en mogelijke hyper parameter waarden beperkt is.