Modellen geven zoals gezegd, een wiskundige beschrijving van de manier waarop data in een bepaalde context (volgens ons) tot stand komen. Die beschrijving bestaat concreet uit een verzameling van
wiskundige functies () en
argumenten () voor die functies
We maken in machine learning een onderscheid tussen twee types argumenten:
gekende waarden van inputvariabelen
onbekende parameters
Het objectief van machine learning is om de onbekende parameters te achterhalen. Parameters bepalen namelijk het numerieke patroon dat achter de datageneratie zit. Dat patroon willen we te weten komen om voorspellingen over nieuwe data te kunnen maken. Dat gebeurt aan de hand van een bepaald leeralgoritme dat op zoek gaat naar de optimale oplossing voor de parameters.
Parameters zijn onbekende functie-argumenten in de wiskundige beschrijving van de data die door ons model wordt gegeven.
Model parameters zijn het geheel van onbekende functie-argumenten in het model die afgeleid/geschat/geleerd dienen te worden uit de data.
We achterhalen de optimale waarden voor model parameters aan de hand van een bepaald leeralgoritme.
Model parameters bepalen de numerieke patronen die achter de datageneratie zit.
De hoeveelheid parameters in een model bepaalt de modelcomplexiteit.

Deze bekende uitspraak verwijst naar het feit dat we nooit in staat zijn om een volledig juiste theorie te hebben over hoe data tot stand zijn gekomen. En als we die al zouden hebben, zou die zoveel parameters bevatten dat we nooit voldoende data kunnen verzamelen om die allemaal voldoende betrouwbaar te schatten via ons leeralgoritme.
Hoe complex we ons model kunnen maken, hangt af van de hoeveelheid beschikbare data/informatie.
Het kan zijn dat bepaalde informatie gewoonweg niet beschikbaar is.
Anderzijds, kan het zijn dat we gewoonweg over te weinig observaties of metingen beschikken om een betrouwbare schatting te maken. Zie illustratie van de Law of large numbers.
Hoe complex we ons model willen maken, hangt af van de use case. Zeker in een product-context, is het algemeen aangeraden om zuinig te zijn met parameters:
Je moet meer data verzamelen vooraleer je kan beginnen leren (trainen)
Het leerproces (training) wordt complexer en onstabieler
Source
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
from scipy import stats
# Set style for better-looking plots
plt.style.use("seaborn-v0_8")
sns.set_palette("husl")Source
# Parameters for the Gaussian distribution
mu = 0 # Population mean
sigma = 1 # Population standard deviation
n_samples = 2000 # Number of samples to draw
# Set random seed for reproducibility using np.random.Generator
rng = np.random.default_rng(123)
# Generate random samples from the Gaussian distribution
samples = rng.normal(mu, sigma, n_samples)
# Calculate cumulative mean
cumulative_mean = np.cumsum(samples) / np.arange(1, n_samples + 1)
# Create the visualization
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(14, 6), gridspec_kw={"width_ratios": [1, 3]})
# Left panel: Show the source distribution (rotated)
y_range = np.linspace(-4, 4, 1000)
pdf_values = stats.norm.pdf(y_range, mu, sigma)
ax1.plot(pdf_values, y_range, "b-", linewidth=2, label=f"N({mu}, {sigma}²)")
ax1.fill_betweenx(y_range, 0, pdf_values, alpha=0.3, color="blue")
ax1.axhline(y=mu, color="red", linestyle="--", linewidth=2, label=f"μ = {mu}")
ax1.set_xlabel("Probability Density")
ax1.set_ylabel("Value")
ax1.set_title("Source Distribution\n(Gaussian)")
ax1.legend()
ax1.grid(True, alpha=0.3)
# Right panel: Show convergence of sample mean
sample_numbers = np.arange(1, n_samples + 1)
ax2.plot(
sample_numbers, cumulative_mean, "g-", linewidth=1.5, label="Cumulative Sample Mean", alpha=0.8
)
ax2.axhline(
y=mu, color="red", linestyle="--", linewidth=2, label=f"True Population Mean (μ = {mu})"
)
# Add confidence bands (theoretical standard error)
theoretical_se = sigma / np.sqrt(sample_numbers)
ax2.fill_between(
sample_numbers,
mu - 1.96 * theoretical_se,
mu + 1.96 * theoretical_se,
alpha=0.2,
color="red",
label="95% Confidence Band",
)
ax2.set_xlabel("Sample Number")
ax2.set_ylabel("Cumulative Mean")
ax2.set_title("Convergence to Population Mean\n(Law of Large Numbers)")
ax2.legend()
ax2.grid(True, alpha=0.3)
# Set y-axis limits to show convergence clearly
ax2.set_ylim(-0.5, 0.5)
plt.tight_layout()
plt.show()
# Print some statistics
print(f"📊 Statistics after {n_samples} samples:")
print(f" True population mean (μ): {mu}")
print(f" Final sample mean: {cumulative_mean[-1]:.4f}")
print(f" Difference from true mean: {abs(cumulative_mean[-1] - mu):.4f}")
print(f" Standard error: {sigma / np.sqrt(n_samples):.4f}")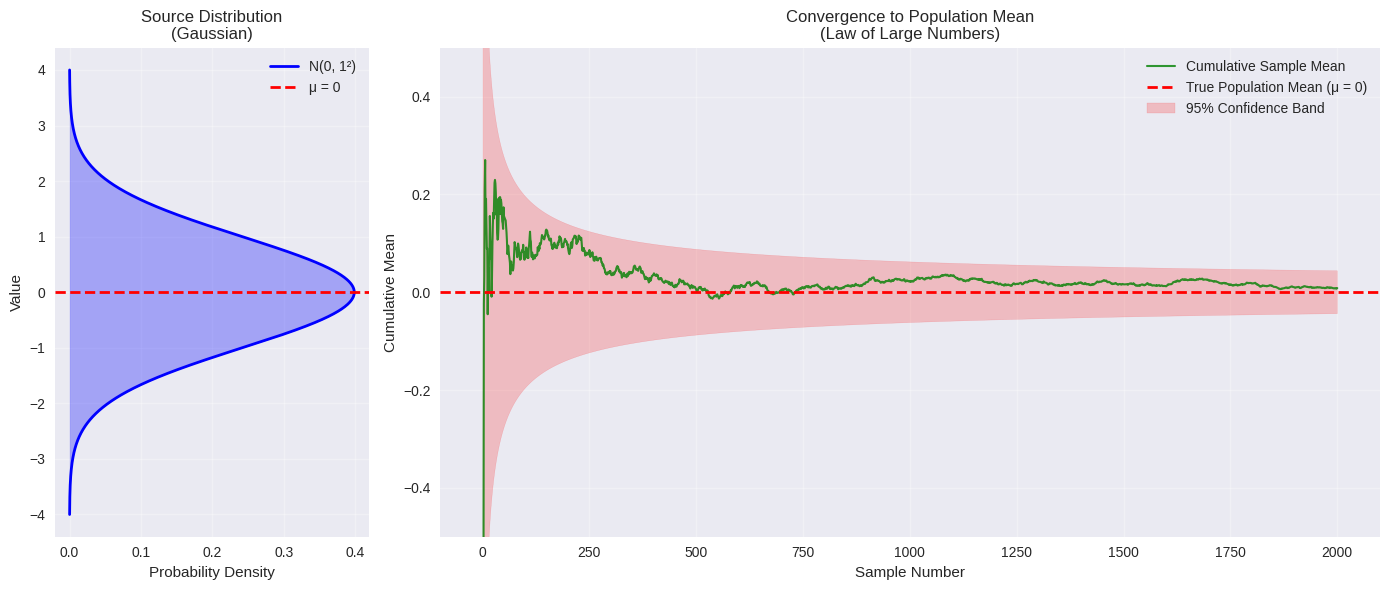
📊 Statistics after 2000 samples:
True population mean (μ): 0
Final sample mean: 0.0085
Difference from true mean: 0.0085
Standard error: 0.0224
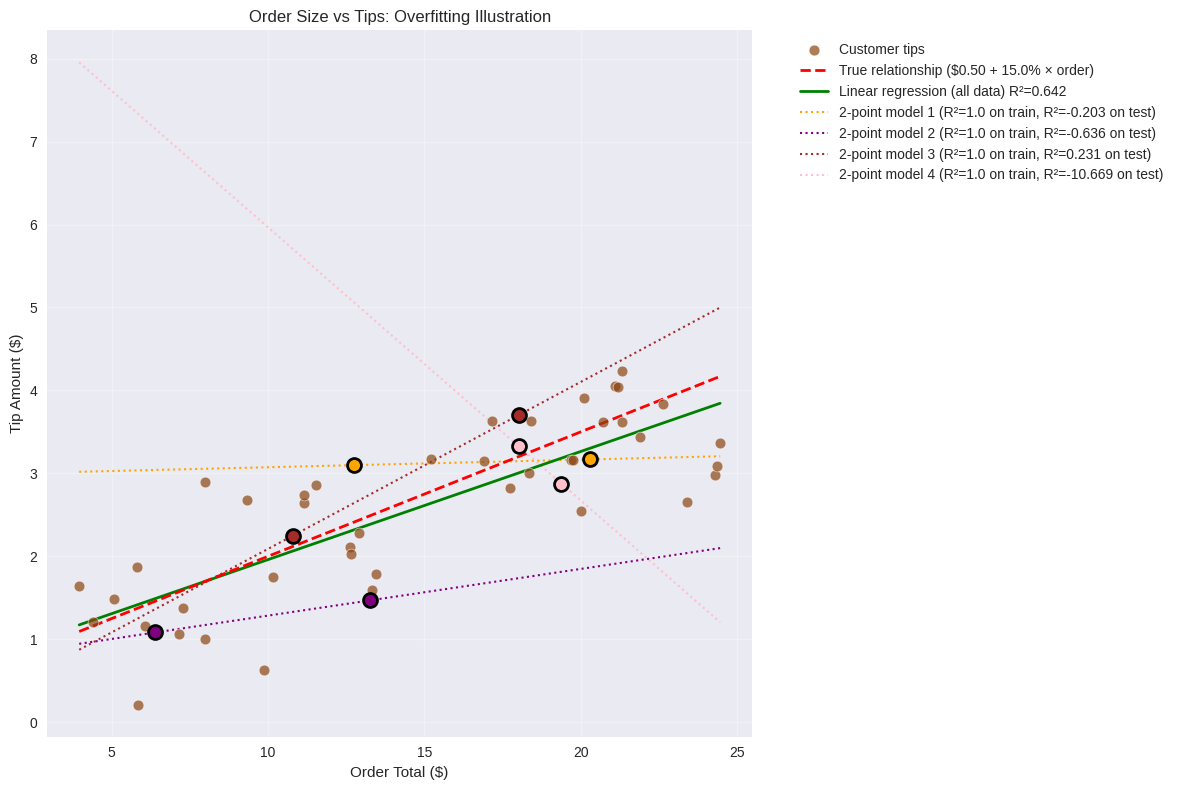
Over fitting¶
Als we meer parameters aan een model toevoegen, stellen we het in theorie in staat om steeds complexere patronen te leren. Maar het volume van de trainingsdata gelijk blijft, geven we het model bij elke nieuwe parameter een extra gelegenheid om de data in zijn geheel als patroon te leren. Als er in het extreme geval uiteindelijk evenveel of meer parameters zijn als trainingsdata, leert het model de trainingsdata 100% accuraat te voorspellen omdat het de data van buiten kent, maar wanneer het geconfronteerd wordt met nieuwe data, gaat het volledig de mist in omdat het ook enkel de trainingsdata kent.
Het fenomeen waarbij de verhouding tussen het aantal model parameters en de hoeveelheid trainingsdata te groot wordt, waardoor het model enkel goed presteert op eerder geziene data, heet over fitting.
Source
from sklearn.metrics import r2_score
from ml_courses.sim.monte_carlo_tips import MonteCarloTipsSimulation
sim = MonteCarloTipsSimulation(noise_std=0.8)
# Linear regression function
def linear_regression(x, y):
"""Calculate linear regression parameters using least squares."""
x_mean = np.mean(x)
y_mean = np.mean(y)
b2 = np.sum((x - x_mean) * (y - y_mean)) / np.sum((x - x_mean) ** 2)
b1 = y_mean - b2 * x_mean
return b1, b2
# Calculate R² for training and test data
def calculate_r2(y_true, y_pred):
"""Calculate R² coefficient of determination."""
return r2_score(y_true, y_pred)
# Plot the coffee shop data with overfitting illustration
plt.figure(figsize=(12, 8))
# Plot customer tips
plt.scatter(
sim.order_totals,
sim.observed_tips,
alpha=0.7,
color="saddlebrown",
s=60,
edgecolor="white",
linewidth=0.5,
label="Customer tips",
zorder=5,
)
# True relationship line
plt.plot(
sim.order_totals,
sim.true_tips,
"r--",
linewidth=2,
label=f"True relationship (${sim.true_b1:.2f} + {sim.true_b2:.1%} × order)",
zorder=4,
)
# Linear regression on all data
b1_all, b2_all = linear_regression(sim.order_totals, sim.observed_tips)
tips_pred_all = b1_all + b2_all * sim.order_totals
r2_all = calculate_r2(sim.observed_tips, tips_pred_all)
plt.plot(
sim.order_totals,
tips_pred_all,
"g-",
linewidth=2,
label=f"Linear regression (all data) R²={r2_all:.3f}",
zorder=3,
)
# Multiple 2-point regression lines to illustrate overfitting
rng = np.random.default_rng(67)
colors = ["orange", "purple", "brown", "pink"]
for i in range(4):
# Randomly select 2 points
indices = rng.choice(len(sim.order_totals), 2, replace=False)
x_train = sim.order_totals[indices]
y_train = sim.observed_tips[indices]
# Fit linear regression on 2 points
b1_2pt, b2_2pt = linear_regression(x_train, y_train)
# Calculate predictions on all data
tips_pred_2pt = b1_2pt + b2_2pt * sim.order_totals
# Calculate R² on training data (will be 1.0)
r2_train = calculate_r2(y_train, b1_2pt + b2_2pt * x_train)
# Calculate R² on all data (will be low)
r2_test = calculate_r2(sim.observed_tips, tips_pred_2pt)
# Plot the 2-point regression line
plt.plot(
sim.order_totals,
tips_pred_2pt,
linestyle=":",
color=colors[i],
linewidth=1.5,
label=f"2-point model {i + 1} (R²={r2_train:.1f} on train, R²={r2_test:.3f} on test)",
zorder=2,
)
# Highlight the training points
plt.scatter(x_train, y_train, color=colors[i], s=100, edgecolor="black", linewidth=2, zorder=6)
plt.xlabel("Order Total ($)")
plt.ylabel("Tip Amount ($)")
plt.title("Order Size vs Tips: Overfitting Illustration")
plt.legend(bbox_to_anchor=(1.05, 1), loc="upper left")
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()