Zoals eerder vermeld, zijn er twee basis stappen in machine learning:
Model training
Model inference
Op het moment dat we een model hebben gedefinieerd, willen we de parameters aan de hand van de beschikbare data schatten. Dat doen we door het gepaste leeralgoritme toe te passen. Dit noemen we model training. Een getraind model is een model waarvan de parameters geschat zijn met behulp van een wel bepaalde training dataset en optimalisatie-algoritme.
Pas als het model getraind is, kan het gebruikt worden om nieuwe data te voorspellen op basis van de geleerde patronen. Die stap heet model inference.
Leeralgoritme¶
Een leer- of optimalisatie-algoritme heeft als doel om de optimale waarde voor een parameter te vinden, gegeven ons model (van de datageneratie) en de beschikbare data. Bij het uitvoeren van het leeralgoritme gebeurt dus het eigenlijke leren in ML. Ook hier zijn vaak verschillende keuzes aan de orde. Daarbij moeten we (a) de effectiviteit om optimale parameterwaarden te vinden en (b) de computationele efficiëntie tegen elkaar afwegen.
De keuze van het algoritme hangt samen met het type model (lineair, neuraal netwerk, random forest, enz.) en, hoewel er voortdurend verder onderzoek gebeurt naar nieuwe technieken, zijn voor veel modellen geijkte keuzes beschikbaar.
Zoals we in de uitgebreidere voorbeelden ook zullen zien, zijn leeralgoritmes vaak zeer complex (denk alvast aan het backpropagation algoritme bij neurale netwerken).
In die complexiteit zit vaak ook nog het feit dat er verdere keuzes moeten gemaakt worden met betrekking tot de specifieke configuratie van het algoritme zelf.
Bij iteratieve methodes, bijvoorbeeld, waarin er stapsgewijs gezocht wordt naar een optimale waarde, moeten we een keuze maken over de grootte van die stappen (de zogenaamde learning rate).
Die configuratie kan een grote impact hebben op de kwaliteit van het uiteindelijke resultaat. Het is vaak op voorhand ook niet duidelijk welke de beste configuratie voor het optimalisatie-algoritme is, gegeven de specifieke situatie. Daarom wordt ook daar vaak op een (al dan niet principiële manier) iteratief gewerkt om tot optimale waarden te komen.
De numerieke configuratie parameters van een optimalisatie-algoritme worden hyper parameters genoemd. Het proces waarbij de hyper parameters worden geoptimaliseerd heet hyper parameter tuning.
Source
import matplotlib.pyplot as plt
from ml_courses.sim.airco import AircoSimulator
# Get the simulated preferences data
ac = AircoSimulator(seed=123)
df = ac.get_data()
y = df.beta.values
# Set the hyperparameters
b_0 = [18.0, 30.0] # Initial estimate
lr = [0.05, 0.3] # Learning rate
max_iter = 50 # Number of iterations
# Run the exponential smoothing algorithm for different configurations
n_sim = 0
for _b_0 in b_0:
for _lr in lr:
estimates = [_b_0]
for i, d in enumerate(y):
# stopping rule
if i + 2 > max_iter:
break
_b_i = estimates[-1] * (1 - _lr) + float(d) * _lr
estimates.append(_b_i)
# If we stopped early, fill the rest with the last estimate
estimates = estimates + [estimates[-1]] * (len(y) - max_iter)
df[f"sim{n_sim}"] = estimates
n_sim += 1
# Visualize the results
# Create labels for the different simulations
sim_labels = [
f"b0={b_0[0]}, lr={lr[0]}",
f"b0={b_0[0]}, lr={lr[1]}",
f"b0={b_0[1]}, lr={lr[0]}",
f"b0={b_0[1]}, lr={lr[1]}",
]
# Plot the true beta and the simulations
plt.figure(figsize=(12, 6))
plt.plot(df["beta"].iloc[:150], label="beta (true)")
for i, label in enumerate(sim_labels):
plt.plot(df[f"sim{i}"].iloc[:150], label=label)
plt.xlabel("Observation")
plt.ylabel("Estimate")
plt.title("Exponential Smoothing Simulations (first 150 observations)")
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()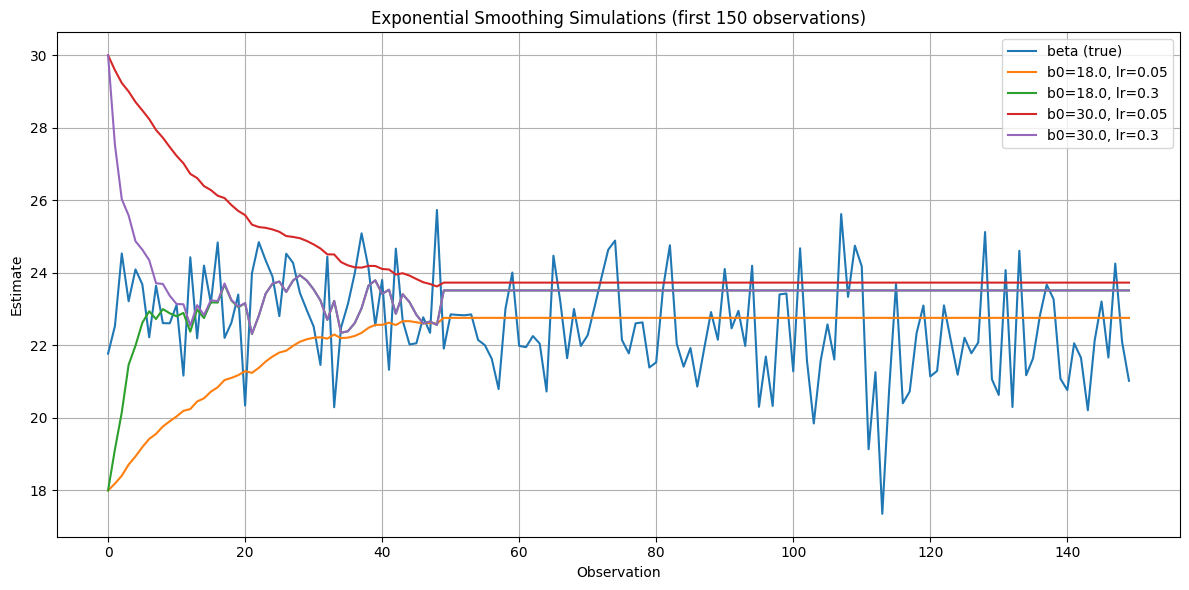
Loss functie¶
De Loss functie is ook gekend onder de namen Error functie en Cost functie. Er wordt in de domeinen van de wiskundige optimalisatie en beslissingstheorie ook soms gesproken over een objectieve functie. Die verwijst ofwel naar een verliesfunctie of zijn tegengestelde vorm. Dan wordt er bijvoorbeeld ook gesproken over een reward functie, profit functie, utility functie, fitness functie, enz.
Bij het zoeken naar de optimale waarden voor de parameters in ons model en/of om te evalueren of het leeralgoritme effectief tot leren leidt, moeten we wiskundig kunnen uitdrukken wat optimaliteit in een specifiek geval betekent om de goodness of fit van de oplossing te kunnen uitdrukken - met andere woorden, we moeten de optimaliteit van parameterschattingen op ieder moment in een cijfer kunnen uitdrukken (kwantificeren). We moeten dus een functie beschrijven die optimaliteit uitdrukt. Het doel van het leeralgoritme is om de output van die functie te maximaliseren.
❗Om wiskundige redenen, draaien we de logica echter om en beschrijven we een functie die de sub-optimaliteit uitdrukt. Die functie trachtten we dan te minimaliseren.
De Loss functie is de wiskundige functie die de sub-optimaliteit uitdrukt van parameterschattingen in een bepaalde context. Het doel van het leeralgoritme is om de output van die functie te minimaliseren. Zoals we nog zullen illustreren, betekent dit niet per se dat het leeralgoritme rechtstreeks gebruik maakt van de Loss functie.
Source
import matplotlib.pyplot as plt
import numpy as np
from ml_courses.sim.airco import AircoSimulator
ac = AircoSimulator()
df = ac.get_data()
d = df.beta.values
# SSE function
def sse(d, b_hat):
"""
Calculate the sum of squared errors (SSE) between observed values d and estimated values b_hat.
Parameters
----------
d : array-like
Observed values.
b_hat : float
Estimated value
Returns
-------
float
The sum of squared errors.
"""
return sum((d_i - b_hat) ** 2 for d_i in d)
# Range of b_hat values
b_hat_range = np.linspace(np.min(d), np.max(d), 200)
sse_values = [sse(d, b_hat) for b_hat in b_hat_range]
# Sample mean
sample_mean = np.mean(d)
plt.figure(figsize=(10, 6))
plt.plot(b_hat_range, sse_values, label="SSE")
plt.axvline(sample_mean, color="red", linestyle="--", label="Sample mean")
plt.xlabel(r"$\hat{b}$")
plt.ylabel("Sum of Squared Errors (SSE)")
plt.title("SSE as a function of $\hat{b}$")
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()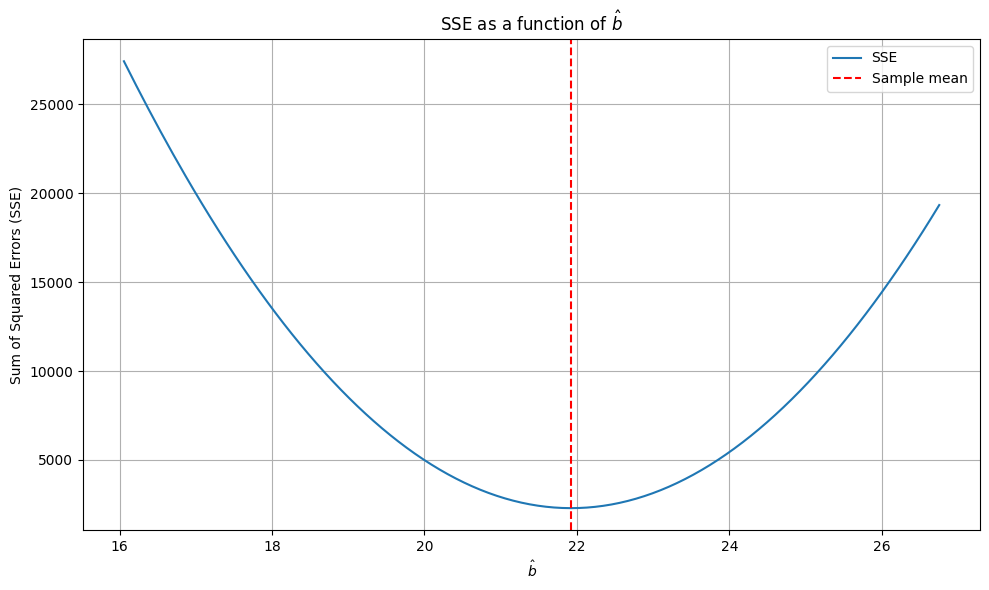
Trainingsdata voorbereiden¶
(On)gebalanceerde trainingsdata en bias¶
Ongebalanceerdheid van trainingsdata verwijst naar het fenomeen waarbij bepaalde categorieën (bv. hond/kat) of continue waarden (bv. leeftijden) over- of ondervertegenwoordigd zijn in de trainingsdata. Dit kan louter het gevolg zijn van natuurlijke scheefheid ofwel een gevolg van de specifieke manier van trainingsdataverzameling. Dit is een algemeen aandachtspunt bij trainingsdata die op natuurlijke wijze verkregen zijn (bv. verkooptransacties, server logs, enz.). Naargelang de ernst van ongebalanceerdheid, leidt het tot statistische bias. Dit verwijst naar het fenomeen waarbij getrainde modellen systematische predictiefouten maken en dus bepaalde voorkeuren hebben ontwikkeld.
Om ons in te dekken tegen ongebalanceerdheid is exploratieve data analyse een belangrijke tool. Het kan geremedieerd worden door extra data te verzamelen en/of door over-/ondersampling toe te passen op de trainingsdata.
Bij under sampling gaan we een random selectie (subsample) maken van overgerepresenteerde categorieën of waarden zodat er een betere balans ontstaat met de ondergerepresenteerde data. Modellen worden dan soms meerdere keren getraind, telkens met een andere subsample om zeker te zijn dat de ondersampling zelf geen artefacten teweeg brengt.
Bij over sampling worden nieuwe, meer gebalanceerde datasets gemaakt door random samples uit de ondergerepresenteerde categorieën of waarden toe te voegen. Dit houdt data duplicatie in, maar is in bepaalde gevallen een zeer effectieve strategie tegen bias.
- Welford, B. P. (1962). Note on a Method for Calculating Corrected Sums of Squares and Products. Technometrics, 4(3), 419–420. 10.1080/00401706.1962.10490022