In deze sectie concentreren we ons eerst op de S S E SSE SSE intercept (b = [ b 1 ] T \pmb{b} = [b_1]^T b b = [ b 1 ] T predictoren b = [ b 1 , b 2 , … ] T \pmb{b} = [b_1, b_2, \ldots]^T b b = [ b 1 , b 2 , … ] T
from ml_courses.sim.derivative_viz import DerivativeVisualization
dv = DerivativeVisualization()
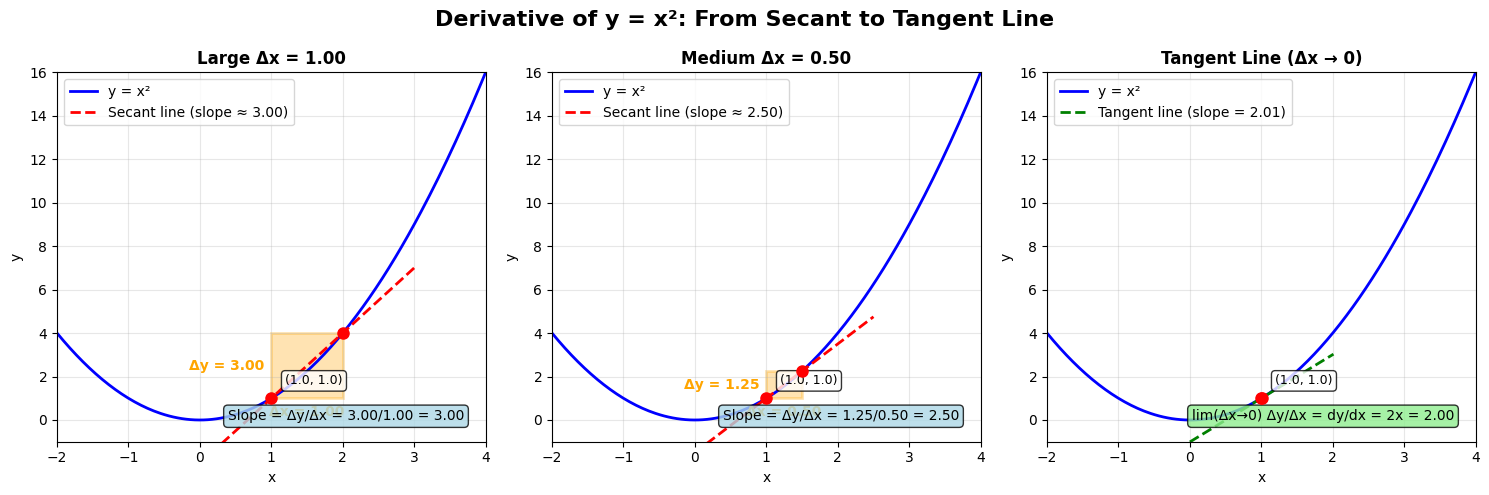
dv.plot()Bij de Monte Carlo sampling leveren we ons over aan het willekeurig aftasten van de S S E SSE SSE stapje naar beneden konden zetten. Het is echter wiskundig perfect mogelijk om op ieder punt te bepalen in welke richting de daling het grootst zal zijn. Dit brengt ons bij het concept van een raak- of tangentlijn op een bepaald punt van een functie waarvan de richtingscoëfficient (of slope ) de “afgeleide ” van die functie in dat punt wordt genoemdf f f x x x lokale lineaire benadering van die functie in dat punthet differentiëren van functies .
Afgeleide van een kwadratische functie ¶ De illustratie hierboven toont het principe van een afgeleide in het geval van een enkelvoudige kwadratische functie:
We beginnen met een rechte die de kwadratische functie op twee punten snijdt : ( x 1 , y 1 ) (x_1, y_1) ( x 1 , y 1 ) ( x 2 , y 2 ) (x_2, y_2) ( x 2 , y 2 ) y y y Δ y = y 2 − y 1 \Delta y = y_2 - y_1 Δ y = y 2 − y 1 x x x Δ x = x 2 − x 1 \Delta x = x_2 - x_1 Δ x = x 2 − x 1
Δ y Δ x = y 2 − y 1 Δ x = f ( x 1 + Δ x ) − f ( x 1 ) Δ x = ( x 1 + Δ x ) 2 − x 1 2 Δ x = x 1 2 + 2 x 1 Δ x + Δ x 2 − x 1 2 Δ x = 2 x 1 Δ x + Δ x 2 Δ x = 2 x 1 + Δ x \begin{aligned}
\frac{\Delta y}{\Delta x}
&= \frac{y_2 - y_1}{\Delta x} \cr
&= \frac{f(x_1 + \Delta x) - f(x_1)}{\Delta x} \cr
&= \frac{(x_1 + \Delta x)^2 - x_1^2}{\Delta x} \cr
&= \frac{x_1^2 + 2x_1\Delta x + \Delta x^2 - x_1^2}{\Delta x} \cr
&= \frac{2x_1\Delta x + \Delta x^2}{\Delta x} \cr
&= 2x_1 + \Delta x
\end{aligned} Δ x Δ y = Δ x y 2 − y 1 = Δ x f ( x 1 + Δ x ) − f ( x 1 ) = Δ x ( x 1 + Δ x ) 2 − x 1 2 = Δ x x 1 2 + 2 x 1 Δ x + Δ x 2 − x 1 2 = Δ x 2 x 1 Δ x + Δ x 2 = 2 x 1 + Δ x Dit geeft al een eerste idee van de richting waarin de kwadratische functie daalt. We kunnen een preciezere richting krijgen door het interval kleiner en kleiner te maken. In het theoretisch kleinste interval (lim Δ x → 0 \lim_{\Delta x\to 0} lim Δ x → 0 afgeleide ” van de functie in dat punt . Als we in het bovenstaande geval Δ x \Delta x Δ x
lim Δ x → 0 Δ y Δ x = ∂ y ∂ x = 2 x \begin{aligned}
\lim_{\Delta x\to 0} \frac{\Delta y}{\Delta x} &= \frac{\partial y}{\partial x} \cr
&= 2x
\end{aligned} Δ x → 0 lim Δ x Δ y = ∂ x ∂ y = 2 x Afgeleide van de S S E SSE SSE b = [ b 1 ] T \pmb{b} = [b_1]^T b b = [ b 1 ] T ¶ Bij de S S E SSE SSE som M M M
f ( y i − y i ^ ) = ( y i − y i ^ ) 2 f(y_i - \hat{y_i}) = (y_i - \hat{y_i})^2 f ( y i − y i ^ ) = ( y i − y i ^ ) 2 of
f ( d i ) = d i 2 f(d_i) = {d_i}^2 f ( d i ) = d i 2 waarbij d i d_i d i y i ^ \hat{y_i} y i ^ y i y_i y i 2 d i 2d_i 2 d i 2 ( y i − y i ^ ) 2(y_i - \hat{y_i}) 2 ( y i − y i ^ )
Maar we hebben bij de S S E SSE SSE som van alle verschillen tussen model outputs en target values in onze training data:
L S S E ( f ( x ) ; y ) = ∑ i = 1 M ( y i − f ( x i ) ) 2 = ∑ i = 1 M ( y i − y i ^ ) 2 = ( y 1 − y 1 ^ ) 2 + ( y 2 − y 2 ^ ) 2 + … + ( y m − y m ^ ) 2 = d 1 2 + d 2 2 + … + d m 2 \begin{aligned}
\mathcal{L}_{SSE}(f(\pmb{x}); \pmb{y}) &= \sum_{i=1}^M(y_i-f(x_i))^2 \cr
&= \sum_{i=1}^M(y_i-\hat{y_i})^2 \cr
&= (y_1 - \hat{y_1})^2 + (y_2 - \hat{y_2})^2 + \ldots + (y_m - \hat{y_m})^2 \cr
&= {d_1}^2 + {d_2}^2 + \ldots + {d_m}^2
\end{aligned} L SSE ( f ( x x ) ; y y ) = i = 1 ∑ M ( y i − f ( x i ) ) 2 = i = 1 ∑ M ( y i − y i ^ ) 2 = ( y 1 − y 1 ^ ) 2 + ( y 2 − y 2 ^ ) 2 + … + ( y m − y m ^ ) 2 = d 1 2 + d 2 2 + … + d m 2 De som-regel ¶ De som-regel houdt in dat voor iedere functie g g g h h h g + h g + h g + h g ′ g' g ′ h ′ h' h ′ :
als
dan
f ′ = g ′ + h ′ f' = g' + h' f ′ = g ′ + h ′ We krijgen dus
L S S E ( f ( x ) ; y ) ′ = 2 d 1 + 2 d 2 + … + 2 d m \mathcal{L}_{SSE}(f(\pmb{x}); \pmb{y})' = 2d_1 + 2d_2 + \ldots + 2d_m L SSE ( f ( x x ) ; y y ) ′ = 2 d 1 + 2 d 2 + … + 2 d m In het geval van een model met enkel een intercept (b = [ b 1 ] T \pmb{b} = [b_1]^T b b = [ b 1 ] T
L S S E ( f ( x ) ; y ) ′ = ∂ L S S E ∂ b 1 = 2 ∑ i = 1 M ( y i − b 1 ) \mathcal{L}_{SSE}(f(\pmb{x}); \pmb{y})' = \frac{\partial \mathcal{L}_{SSE}}{\partial b_1} = 2\sum_{i=1}^M(y_i-b_1) L SSE ( f ( x x ) ; y y ) ′ = ∂ b 1 ∂ L SSE = 2 i = 1 ∑ M ( y i − b 1 ) Wanneer we de ideale waarde voor b 1 b_1 b 1 → \to →
0 = 2 ∑ i = 1 M ( y i − b 1 ^ ) 0 = ∑ i = 1 M ( y i − b 1 ^ ) 0 = ( ∑ i = 1 M y i ) − M b 1 ^ M b 1 ^ = ∑ i = 1 M y i b 1 ^ = ∑ i = 1 M y i M \begin{align}
0 &= 2\sum_{i=1}^M(y_i-\hat{b_1}) \cr
0 &= \sum_{i=1}^M(y_i-\hat{b_1}) \cr
0 &= (\sum_{i=1}^My_i) - M\hat{b_1} \cr
M\hat{b_1} &= \sum_{i=1}^My_i \cr
\hat{b_1} &= \frac{\sum_{i=1}^My_i}{M}
\end{align} 0 0 0 M b 1 ^ b 1 ^ = 2 i = 1 ∑ M ( y i − b 1 ^ ) = i = 1 ∑ M ( y i − b 1 ^ ) = ( i = 1 ∑ M y i ) − M b 1 ^ = i = 1 ∑ M y i = M ∑ i = 1 M y i De beste estimate is met andere woorden gelijk aan het gemiddelde van alle trainingsdata y i y_i y i
Gradiënt van de S S E SSE SSE b = [ b 1 , b 2 ] T \pmb{b} = [b_1, b_2]^T b b = [ b 1 , b 2 ] T ¶ In het geval van b = [ b 1 , b 2 ] T \pmb{b} = [b_1, b_2]^T b b = [ b 1 , b 2 ] T S S E SSE SSE
L S S E ( f ( x ) ; y ) ′ = ∇ L S S E = [ ∂ L S S E ∂ b 1 ∂ L S S E ∂ b 2 ] \mathcal{L}_{SSE}(f(\pmb{x}); \pmb{y})' = \nabla{\mathcal{L}_{SSE}} = \begin{bmatrix}
\frac{\partial \mathcal{L}_{SSE}}{\partial b_1} \cr
\frac{\partial \mathcal{L}_{SSE}}{\partial b_2}
\end{bmatrix} L SSE ( f ( x x ) ; y y ) ′ = ∇ L SSE = [ ∂ b 1 ∂ L SSE ∂ b 2 ∂ L SSE ] De elementen ∂ L S S E ∂ b 1 \frac{\partial \mathcal{L}_{SSE}}{\partial b_1} ∂ b 1 ∂ L SSE ∂ L S S E ∂ b 2 \frac{\partial \mathcal{L}_{SSE}}{\partial b_2} ∂ b 2 ∂ L SSE partiële afgeleiden van de S S E SSE SSE gradiënt van de S S E SSE SSE ∇ L S S E \nabla{\mathcal{L}_{SSE}} ∇ L SSE De gradiënt verbreedt met andere woorden het concept van de afgeleide naar het geval van meerdere onbekenden.
Om een ideale oplossing voor [ b 1 , b 2 ] T [b_1, b_2]^T [ b 1 , b 2 ] T S S E SSE SSE 0 \pmb{0} 0 0
∇ L S S E = 0 = [ 0 0 ] \nabla{\mathcal{L}_{SSE}} = \pmb{0} = \begin{bmatrix}
0 \cr
0
\end{bmatrix} ∇ L SSE = 0 0 = [ 0 0 ] Daarvoor moeten we eerst de partiële afgeleiden uitwerken.
De partiële afgeleide ∂ S S E ∂ b 1 \frac{\partial SSE}{\partial b_1} ∂ b 1 ∂ SSE S S E SSE SSE b 1 b_1 b 1 b 2 b_2 b 2 .
∂ L S S E ∂ b 1 = ∂ ∂ b 1 [ ∑ i = 1 M ( y i − y i ^ ) 2 ] = ∂ ∂ b 1 [ ∑ i = 1 M ( y i − b 1 − b 2 x i ) 2 ] \begin{aligned}
\frac{\partial \mathcal{L}_{SSE}}{\partial b_1} &= \frac{\partial}{\partial b_1}\begin{bmatrix}
\sum_{i=1}^M(y_i - \hat{y_i})^2
\end{bmatrix} \cr
&= \frac{\partial}{\partial b_1}\begin{bmatrix}
\sum_{i=1}^M(y_i - b_1 - b_2x_i)^2
\end{bmatrix}
\end{aligned} ∂ b 1 ∂ L SSE = ∂ b 1 ∂ [ ∑ i = 1 M ( y i − y i ^ ) 2 ] = ∂ b 1 ∂ [ ∑ i = 1 M ( y i − b 1 − b 2 x i ) 2 ] Gegeven de som-regel krijgen we
∂ L S S E ∂ b 1 = ∑ i = 1 M ∂ ∂ b 1 ( y i − b 1 − b 2 x i ) 2 \begin{aligned}
\frac{\partial \mathcal{L}_{SSE}}{\partial b_1} &=
\sum_{i=1}^M\frac{\partial}{\partial b_1}(y_i - b_1 - b_2x_i)^2
\end{aligned} ∂ b 1 ∂ L SSE = i = 1 ∑ M ∂ b 1 ∂ ( y i − b 1 − b 2 x i ) 2 De ketting-regel ¶ We krijgen hier te maken met twee geneste functies :
h ( b 1 , b 2 ) = y i − b 1 − b 2 x i h(b_1, b_2) = y_i - b_1 - b_2x_i h ( b 1 , b 2 ) = y i − b 1 − b 2 x i en
g ( h ( b 1 , b 2 ) ) = h ( b 1 , b 2 ) 2 = ( y i − b 1 − b 2 x i ) 2 g(h(b_1, b_2)) = h(b_1, b_2)^2 = (y_i - b_1 - b_2x_i)^2 g ( h ( b 1 , b 2 )) = h ( b 1 , b 2 ) 2 = ( y i − b 1 − b 2 x i ) 2 De ketting-regel houdt in dat bij geneste functies g ( h ( x ) ) g(h(x)) g ( h ( x )) x x x
∂ ∂ x g ( h ( x ) ) = ∂ g ∂ h ∂ h ∂ x \frac{\partial}{\partial x}g(h(x)) = \frac{\partial g}{\partial h}\frac{\partial h}{\partial x} ∂ x ∂ g ( h ( x )) = ∂ h ∂ g ∂ x ∂ h Voor de afgeleide van de buitenste functie krijgen we (zie afgeleide van kwadratische functie):
∂ g ∂ h = 2 ( y i − b 1 − b 2 x i ) \frac{\partial g}{\partial h} = 2(y_i - b_1 - b_2x_i) ∂ h ∂ g = 2 ( y i − b 1 − b 2 x i ) Voor de binnenste afgeleide kunnen we de functie y i − b 1 − b 2 x i y_i - b_1 - b_2x_i y i − b 1 − b 2 x i c − b 1 c - b_1 c − b 1 y i y_i y i x i x_i x i b 2 b_2 b 2 y i − b 2 x i y_i - b_2x_i y i − b 2 x i c c c
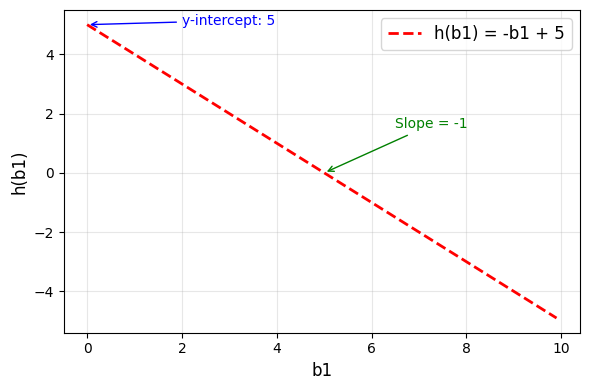
∂ h ∂ x = ∂ ∂ b 1 ( c − b 1 ) = − 1 \begin{align}
\frac{\partial h}{\partial x} &= \frac{\partial}{\partial b_1}(c - b_1) \cr
&= -1
\end{align} ∂ x ∂ h = ∂ b 1 ∂ ( c − b 1 ) = − 1 Als we c − b 1 c - b_1 c − b 1
import matplotlib.pyplot as plt
import numpy as np
b1 = np.arange(0, 10, 0.1)
c = 5
h_b1 = -b1 + c
fig, ax = plt.subplots(figsize=(6, 4))
ax.plot(b1, h_b1, "r--", linewidth=2, label=f"h(b1) = -b1 + {c}")
# Add grid for better readability
ax.grid(True, alpha=0.3)
# Set labels and title
ax.set_xlabel("b1", fontsize=12)
ax.set_ylabel("h(b1)", fontsize=12)
# Add legend
ax.legend(fontsize=12)
# Add annotations to highlight key features
ax.annotate(
f"y-intercept: {c}",
xy=(0, c),
xytext=(2, c),
arrowprops={"arrowstyle": "->", "color": "blue"},
fontsize=10,
color="blue",
)
ax.annotate(
"Slope = -1",
xy=(5, 0),
xytext=(6.5, 1.5),
arrowprops={"arrowstyle": "->", "color": "green"},
fontsize=10,
color="green",
)
plt.tight_layout()
plt.show()Als we de ketting regel (dus het product van ∂ g ∂ h \frac{\partial g}{\partial h} ∂ h ∂ g ∂ h ∂ x \frac{\partial h}{\partial x} ∂ x ∂ h
∂ L S S E ∂ b 1 = ∑ i = 1 M 2 ( y i − b 1 − b 2 x i ) ( − 1 ) = ∑ i = 1 M − 2 ( y i − b 1 − b 2 x i ) = − 2 ∑ i = 1 M ( y i − b 1 − b 2 x i ) \begin{aligned}
\frac{\partial \mathcal{L}_{SSE}}{\partial b_1} &=
\sum_{i=1}^M2(y_i - b_1 - b_2x_i)(-1) \cr
&=
\sum_{i=1}^M-2(y_i - b_1 - b_2x_i) \cr
&=
-2\sum_{i=1}^M(y_i - b_1 - b_2x_i)
\end{aligned} ∂ b 1 ∂ L SSE = i = 1 ∑ M 2 ( y i − b 1 − b 2 x i ) ( − 1 ) = i = 1 ∑ M − 2 ( y i − b 1 − b 2 x i ) = − 2 i = 1 ∑ M ( y i − b 1 − b 2 x i ) De partiële afgeleide ∂ L S S E ∂ b 2 \frac{\partial \mathcal{L}_{SSE}}{\partial b_2} ∂ b 2 ∂ L SSE S S E SSE SSE b 2 b_2 b 2 b 1 b_1 b 1 .
∂ L S S E ∂ b 2 = ∑ i = 1 M ∂ ∂ b 2 ( y i − b 1 − b 2 x i ) 2 \begin{aligned}
\frac{\partial \mathcal{L}_{SSE}}{\partial b_2} &=
\sum_{i=1}^M\frac{\partial}{\partial b_2}(y_i - b_1 - b_2x_i)^2
\end{aligned} ∂ b 2 ∂ L SSE = i = 1 ∑ M ∂ b 2 ∂ ( y i − b 1 − b 2 x i ) 2 Gezien de ketting-regel krijgen we hier:
∂ L S S E ∂ b 2 = ∑ i = 1 M 2 ( y i − b 1 − b 2 x i ) ( − x i ) = − 2 ∑ i = 1 M ( y i − b 1 − b 2 x i ) x i \begin{aligned}
\frac{\partial \mathcal{L}_{SSE}}{\partial b_2} &=
\sum_{i=1}^M2(y_i - b_1 - b_2x_i)(-x_i) \cr
&=
-2\sum_{i=1}^M(y_i - b_1 - b_2x_i)x_i
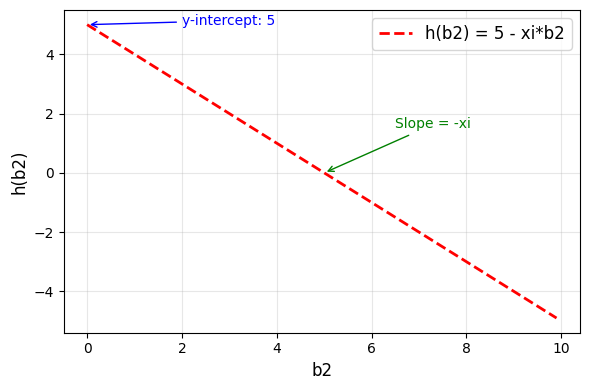
\end{aligned} ∂ b 2 ∂ L SSE = i = 1 ∑ M 2 ( y i − b 1 − b 2 x i ) ( − x i ) = − 2 i = 1 ∑ M ( y i − b 1 − b 2 x i ) x i De term ( − x i ) (-x_i) ( − x i ) y i − b 1 − b 2 x i y_i - b_1 - b_2x_i y i − b 1 − b 2 x i b 2 b_2 b 2 b 1 b_1 b 1 y i y_i y i x i x_i x i h ( b 2 ) = c − x i b 2 h(b_2) = c - x_ib_2 h ( b 2 ) = c − x i b 2 slope − x i -x_i − x i
b2 = np.arange(0, 10, 0.1)
c = 5
xi = 10
h_b2 = c + -xi * b1
fig, ax = plt.subplots(figsize=(6, 4))
ax.plot(b1, h_b1, "r--", linewidth=2, label=f"h(b2) = {c} - xi*b2")
# Add grid for better readability
ax.grid(True, alpha=0.3)
# Set labels and title
ax.set_xlabel("b2", fontsize=12)
ax.set_ylabel("h(b2)", fontsize=12)
# Add legend
ax.legend(fontsize=12)
# Add annotations to highlight key features
ax.annotate(
f"y-intercept: {c}",
xy=(0, c),
xytext=(2, c),
arrowprops={"arrowstyle": "->", "color": "blue"},
fontsize=10,
color="blue",
)
ax.annotate(
"Slope = -xi",
xy=(5, 0),
xytext=(6.5, 1.5),
arrowprops={"arrowstyle": "->", "color": "green"},
fontsize=10,
color="green",
)
plt.tight_layout()
plt.show()Uiteindelijk krijgen we dus:
∇ L S S E = [ − 2 ∑ i = 1 M ( y i − b 1 − b 2 x i ) − 2 ∑ i = 1 M ( y i − b 1 − b 2 x i ) x i ] \nabla{\mathcal{L}_{SSE}} = \begin{bmatrix}
-2\sum_{i=1}^M(y_i - b_1 - b_2x_i) \cr
-2\sum_{i=1}^M(y_i - b_1 - b_2x_i)x_i
\end{bmatrix} ∇ L SSE = [ − 2 ∑ i = 1 M ( y i − b 1 − b 2 x i ) − 2 ∑ i = 1 M ( y i − b 1 − b 2 x i ) x i ] en zoeken we de oplossing voor de waarden b 1 b_1 b 1 b 2 b_2 b 2 0 \pmb{0} 0 0
[ 0 0 ] = [ − 2 ∑ i = 1 M ( y i − b 1 ^ − b 2 ^ x i ) − 2 ∑ i = 1 M ( y i − b 1 ^ − b 2 ^ x i ) x i ] \begin{bmatrix}
0 \cr
0
\end{bmatrix} = \begin{bmatrix}
-2\sum_{i=1}^M(y_i - \hat{b_1} - \hat{b_2}x_i) \cr
-2\sum_{i=1}^M(y_i - \hat{b_1} - \hat{b_2}x_i)x_i
\end{bmatrix} [ 0 0 ] = [ − 2 ∑ i = 1 M ( y i − b 1 ^ − b 2 ^ x i ) − 2 ∑ i = 1 M ( y i − b 1 ^ − b 2 ^ x i ) x i ] Gradiënt van de S S E SSE SSE b = [ b 1 , b 2 , . . . ] T \pmb{b} = [b_1, b_2, ...]^T b b = [ b 1 , b 2 , ... ] T ¶ In het algemene geval van een S S E SSE SSE N N N N N N S S E SSE SSE hypersurface . Voor de gradiënt krijgen we:
∇ L S S E = [ − 2 ∑ i = 1 M ( y i − ∑ j = 1 N x i j b j ) ( x i , 1 ) − 2 ∑ i = 1 M ( y i − ∑ j = 1 N x i j b j ) ( x i , 2 ) ⋮ − 2 ∑ i = 1 M ( y i − ∑ j = 1 N x i j b j ) ( x i , n ) ] \nabla{\mathcal{L}_{SSE}} = \begin{bmatrix}
-2\sum_{i=1}^M(y_i - \sum_{j=1}^Nx_{ij}b_j)(x_{i,1}) \cr
-2\sum_{i=1}^M(y_i - \sum_{j=1}^Nx_{ij}b_j)(x_{i,2}) \cr
\vdots \cr
-2\sum_{i=1}^M(y_i - \sum_{j=1}^Nx_{ij}b_j)(x_{i,n})
\end{bmatrix} ∇ L SSE = ⎣ ⎡ − 2 ∑ i = 1 M ( y i − ∑ j = 1 N x ij b j ) ( x i , 1 ) − 2 ∑ i = 1 M ( y i − ∑ j = 1 N x ij b j ) ( x i , 2 ) ⋮ − 2 ∑ i = 1 M ( y i − ∑ j = 1 N x ij b j ) ( x i , n ) ⎦ ⎤ en zoeken we een oplossing voor:
[ 0 0 ⋮ 0 ] = [ − 2 ∑ i = 1 M ( y i − ∑ j = 1 N x i j b j ^ ) ( x i , 1 ) − 2 ∑ i = 1 M ( y i − ∑ j = 1 N x i j b j ^ ) ( x i , 2 ) ⋮ − 2 ∑ i = 1 M ( y i − ∑ j = 1 N x i j b j ^ ) ( x i , n ) ] \begin{bmatrix}
0 \cr
0 \cr
\vdots \cr
0
\end{bmatrix} = \begin{bmatrix}
-2\sum_{i=1}^M(y_i - \sum_{j=1}^Nx_{ij}\hat{b_j})(x_{i,1}) \cr
-2\sum_{i=1}^M(y_i - \sum_{j=1}^Nx_{ij}\hat{b_j})(x_{i,2}) \cr
\vdots \cr
-2\sum_{i=1}^M(y_i - \sum_{j=1}^Nx_{ij}\hat{b_j})(x_{i,n})
\end{bmatrix} ⎣ ⎡ 0 0 ⋮ 0 ⎦ ⎤ = ⎣ ⎡ − 2 ∑ i = 1 M ( y i − ∑ j = 1 N x ij b j ^ ) ( x i , 1 ) − 2 ∑ i = 1 M ( y i − ∑ j = 1 N x ij b j ^ ) ( x i , 2 ) ⋮ − 2 ∑ i = 1 M ( y i − ∑ j = 1 N x ij b j ^ ) ( x i , n ) ⎦ ⎤ Als we dit herordenen krijgen we voor iedere b k ^ \hat{b_k} b k ^
∑ i = 1 M ∑ j = 1 N x i k x i j b j ^ = ∑ i = 1 M x i k y i \sum_{i=1}^M\sum_{j=1}^Nx_{ik}x_{ij}\hat{b_j} = \sum_{i=1}^Mx_{ik}y_i i = 1 ∑ M j = 1 ∑ N x ik x ij b j ^ = i = 1 ∑ M x ik y i met
k = 1 , 2 , … , n k = 1, 2, \ldots, n k = 1 , 2 , … , n Deze vergelijkingen worden de normal equations genoemd en kunnen als volgt in compacte matrixvorm geschreven worden:
( X T X ) b ^ = X T y (\pmb{X}^T\pmb{X})\hat{\pmb{b}} = \pmb{X}^T\pmb{y} ( X X T X X ) b b ^ = X X T y y De oplossing voor b ^ \hat{\pmb{b}} b b ^
b ^ = ( X T X ) − 1 X T y \hat{\pmb{b}} = (\pmb{X}^T\pmb{X})^{-1}\pmb{X}^T\pmb{y} b b ^ = ( X X T X X ) − 1 X X T y y