Misschien wel de belangrijkste operatie in machine learning is het dot of inner product tussen 2 vectoren uit dezelfde ruimte (dus met een gelijk aantal elementen). De eerste vector is daarbij een rij-vector en de tweede een kolom-vector .
Het dot product tussen 2 vectoren uit een gegeven ruimte, is dus de som van de elementgewijze producten. Het resultaat is altijd een scalaire waarde.
import numpy as npa = np.array([1, 2, 3])
b = np.array([4, 5, 6])
print(f"Dot product result: {np.dot(a, b)}")Dot product result: 32
a[0] * b[0] + a[1] * b[1] + a[2] * b[2]np.int64(32)# alternative notation for np.dot
a @ bnp.int64(32)Merk op dat:
Het principe van het dot product kan uitgebreid worden naar het geval een matrix en een vector uit dezelfde ruimte: . Geometrisch moet de matrix hier gezien worden als een verzameling van punten in dezelfde ruimte als waar uit afkomstig is. heeft dus evenveel kolommen als er elementen in zijn.
Bij het dot product tussen een matrix en een vector, is resultaat altijd een vector met evenveel elementen als er rijen zijn in de matrix.
A = np.array([[1, 2, 3], [4, 5, 6]])
print(f"Matrix A shape: {A.shape}")
nrow, ncol = A.shape
print(f"Matrix A has {nrow} rows and {ncol} columns.")
print(f"Dot product result:\n{np.dot(A, b)}")Matrix A shape: (2, 3)
Matrix A has 2 rows and 3 columns.
Dot product result:
[32 77]
np.array(
[
A[0, 0] * b[0] + A[0, 1] * b[1] + A[0, 2] * b[2],
A[1, 0] * b[0] + A[1, 1] * b[1] + A[1, 2] * b[2],
]
)array([32, 77])# alternative notation for np.dot
A @ barray([32, 77])Tenslotte bespreken we ook nog het geval van de uitbreiding naar 2 matrices; het inner product . Geometrisch kunnen we beide matrices zien als verzamelingen van punten in dezelfde -dimensionele ruimte. Ze hebben hetzelfde aantal kolommen, maar niet per se hetzelfde aantal rijen. Meestal wordt direct gezien als een matrix met rijen en een bepaald aantal kolommen . Dan wordt de notatie simpelweg .
Bij het dot product van 2 matrices en , is resultaat altijd een matrix met evenveel rijen als er rijen zijn in en evenveel kolommen als er kolommen zijn in .
B = np.array([[7, 8, 9, 10], [11, 12, 13, 14], [15, 16, 17, 18]])
print(f"Matrix B shape: {B.shape}")
print(f"Dot product result:\n{np.dot(A, B)}") # Result is 2x4 matrixMatrix B shape: (3, 4)
Dot product result:
[[ 74 80 86 92]
[173 188 203 218]]
np.array(
[
[
A[0, 0] * B[0, 0] + A[0, 1] * B[1, 0] + A[0, 2] * B[2, 0],
A[0, 0] * B[0, 1] + A[0, 1] * B[1, 1] + A[0, 2] * B[2, 1],
A[0, 0] * B[0, 2] + A[0, 1] * B[1, 2] + A[0, 2] * B[2, 2],
A[0, 0] * B[0, 3] + A[0, 1] * B[1, 3] + A[0, 2] * B[2, 3],
],
[
A[1, 0] * B[0, 0] + A[1, 1] * B[1, 0] + A[1, 2] * B[2, 0],
A[1, 0] * B[0, 1] + A[1, 1] * B[1, 1] + A[1, 2] * B[2, 1],
A[1, 0] * B[0, 2] + A[1, 1] * B[1, 2] + A[1, 2] * B[2, 2],
A[1, 0] * B[0, 3] + A[1, 1] * B[1, 3] + A[1, 2] * B[2, 3],
],
]
)array([[ 74, 80, 86, 92],
[173, 188, 203, 218]])# alternative notation for np.dot
A @ Barray([[ 74, 80, 86, 92],
[173, 188, 203, 218]])Toepassingen¶
Lineaire gewichten¶
Zowel bij lineaire regressie als bij simpele neurale netwerken zoals perceptrons Rosenblatt (1958), worden input features vertaald naar model outputs door gewogen sommen te nemen. Deze operatie komt neer op het dot product tussen de input vector en een vector van gewichten : .
Gewogen gemiddeldes¶
Ieder arithmetisch gemiddelde van een reeks datapunten van een bepaald type, kan uitgedrukt worden aan de hand van een dot product tussen een vector van gewichten en de data-vector , waarbij de som van de elementen van exact 1 is.
Voor het algemene on-/gewogen gemiddelde krijgen we:
Voor een ongewogen gemiddelde krijgen we dan:
Euclidische norm¶
Vectoren hebben een grootte en een richting, zoals bijvoorbeeld de versnelling van een object in de ruimte . Vaak willen we de grootte uitdrukken in een scalaire waarde. Dat doen we aan de hand van een norm-functie die gedefiniëerd is als:
De norm van een vector in een bepaalde ruimte drukt de afstand uit tussen de oorsprong en het punt waar de vector betrekking op heeft.
In een Euclidische ruimte wordt die afstand gegeven door de norm. De norm van een vector bekomt men door het dot product te nemen van de vector met zichzelf, gevolgd door een vierkantswortel:
Cosine similarity¶
Vaak willen we ook de afstand tussen 2 vectoren uitdrukken in een scalaire waarde, bijvoobeeld in de context van similarity search. In Euclidische ruimtes wordt dan vaak gekeken naar de cosinus van de hoek tussen 2 vectoren . Dit heet dan de cosine similarity en wordt bekomen door het dot product te nemen en het te delen door de respectievelijke Euclidische normen:
Om dit te begrijpen hebben we de geometrische interpretatie van het dot-product nodig.
De scalaire projectie van vector op in de Euclidische ruimte is gegeven als:
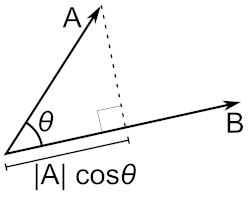
waarbij de hoek is tussen beide vectoren. We kunnen deze geometrische definitie herschrijven als
met de unit vector (dwz. vector met lengte 1) in de richting van :
Als we definities (10) en (11) aan elkaar gelijk stellen krijgen we:
Het dot product van en is dus het product van (i) de grootte van de scalare projectie van op en (ii) de grootte van . De uitkomst zal groter worden naargelang:
groter is
groter is
kleiner is
Als we terugkomen op de cosine similarity kunnen we direct zien waar de formulering vandaan komt:
- Rosenblatt, F. (1958). The perceptron: A probabilistic model for information storage and organization in the brain. Psychological Review, 65(6), 386–408. 10.1037/h0042519
- McCulloch, W. S., & Pitts, W. (1943). A logical calculus of the ideas immanent in nervous activity. The Bulletin of Mathematical Biophysics, 5(4), 115–133. 10.1007/bf02478259