Misschien wel de belangrijkste toepassing van probabiliteitstheorie in de context van ML is dat het ons toelaat om rekening te houden met sampling errors bij het ontwerpen van modellen. Daardoor krijgen we de mogelijkheid om de onzekerheid over parameters en predicties te kwantificeren op basis van probabiliteitstheorie en zelfs modelparameters via probabiliteitstheorie te schatten en modellen te vergelijken. We bekijken dit terug in de context van eenvoudige lineaire regressie.
In het algemene lineaire regressiemodel stellen we dat onze data afkomstig zijn van een onderliggende lineaire combinatie van predictoren (features) mét additieve sampling-ruis .
Toen we dit model introduceerden, hebben we bij het simuleren van data de errors gesampled uit een normaalverdeling met gemiddelde 0 en een bepaalde (populatie) standaardafwijking :
Tot nu toe deden we verder niets met deze assumptie. We waren enkel begaan met het leren van de onbekende lineaire parameters . Hier zullen we echter de parameter van de ruis-verdeling ook als een leerbare parameter beschouwen. Dit opent de deur naar probabiliteits- en informatietheoretische benaderingen.
Maximum likelihood (ML)¶
Door de regels voor lineaire combinaties van kansvariabelen toe te passen, krijgen we volgende formulering voor de kansverdeling van de data (gegeven de feature matrix , de parameters en de ruis standaarddeviatie ):
In woorden: de gezamenlijke (joint) kansverdeling van de data is een multivariate normaalverdeling met gemiddelde en een homogene variantie zodat:
De variantie-covariantiematrix van de gezamenlijke (joint) kansverdeling is dus een diagonaalmatrix met constante variantie (). Het feit dat de niet-diagonaal elementen van de variantie-covariantiematrix nul zijn, geeft aan dat we in ons model ervan uitgaan dat alle datapunten en onafhankelijk van elkaar zijn.
Geven de assumptie dat de individuele observaties onafhankelijk van elkaar zijn, kunnen we via de vereenvoudigde productregel (zonder conditionele kansen ) de likelihood functie bij lineaire regressie met normaal verdeelde homogene ruis als het product van de individuele kansen uitdrukken:
We kunnen nu de vraag stellen: welke waarden voor de onbekende parameters én zorgen voor een maximale likelihood[1]? Ook hier kunnen we dit slim benaderen door de gradient van de likelihoodfunctie te berekenen (in plaats van grid search of ongeleide monte-carlo sampling). Daarvoor is het handig om het product in vergelijking (3) om te zetten naar een som door over te stappen naar de log likelihood functie[2]:
Als we nu de formulering van de normaalverdeling invoegen, krijgen we:
¶
Als we ons eerst richten tot de schatting van , kunnen we ons focussen op de tweede term, aangezien niet deelneemt aan de eerste term en die term dus geen invloed heeft op het maximum met betrekking tot de lineaire gewichten . Bovendien kunnen we ook achterwege laten, aangezien dit slechts een schaalfactor is. We zoeken dus het maximum van:
¶
Het voordeel van de likelihood-benadering is dat we ook een optimale schatting voor de variantie kunnen vinden door de gradient te berekenen.
We vertrekken van de log-likelihood functie en willen de gradient met betrekking tot :
We behandelen beide termen apart:
Term 1:
De afgeleide naar (waarbij een constante is)[3]:
Term 2:
We gebruiken de machtsregel voor de afgeleide[4]. Laat , dan:
Combineren en gelijkstellen aan nul:
Vermenigvuldig beide zijden met :
De maximum likelihood schatting voor de variantie in een lineaire regressie met homogene Gaussiaanse ruis is dus gelijk aan de mean squared error:
Fisher information¶
Naast het feit dat het principe van maximum likelihood gemakkelijk toe te passen is op tal van verschillende modellen met verschillende probabilistische assumpties, laat de techniek ons ook toe om de onzekerheid over geleerde parameters uit te drukken. Dit doen we via het concept van Fisher informatie.
De Fisher informatie meet hoeveel informatie een observatie draagt over een onbekende parameter . Ze is gedefinieerd als de verwachte waarde van het kwadraat van de eerste afgeleide van de log-likelihood:
Alternatief kan ze ook uitgedrukt worden als de negatieve verwachte waarde van de tweede afgeleide van de log-likelihood:
Voor meerdere parameters krijgen we de Fisher informatiematrix:
Hoge Fisher informatie:
de likelihood-functie is relatief stijl; ze verandert snel in functie van de parameter
de data is zeer informatief met betrekking tot parameter
we kunnen parameter met veel zekerheid schatten
Lage Fisher informatie:
de likelihood-functie is relatief vlak; ze verandert traag in functie van de parameter
de data is weinig informatief met betrekking tot parameter
we kunnen parameter enkel met veel onzekerheid schatten
Standaardfouten van parameters¶
In de praktijk gebruiken we de Fisher informatie om de standaardfouten van onze parameterschattingen te berekenen. De standaard fouten vertellen ons wat de verwachte spreiding is van de schattingen over verschillende samples. De geschatte covariantiematrix van de parameters is de inverse van de Fisher informatiematrix:
De standaardfout van parameter is dan:
waarbij het -de diagonaalelement van de matrix aangeeft.
Betrouwbaarheidintervallen¶
De standaardfouten van de parameters laten ons toe om naast de punt-schatting ook een interval-schatting te maken. In de veronderstelling van een normaal verdeelde sampling distributie, berekenen we ze als . Bij spreken we bijvoorbeeld van het 95% betrouwbaarheidsinterval (confidence interval) en is de correcte interpretatie:
Als we het experiment (sampling + berekening van het interval) oneindig vaak zouden herhalen, dan zou 95% van deze intervallen de ware parameter bevatten.
Predictie-intervallen¶
Naast betrouwbaarheidsintervallen voor parameters zijn we in machine learning vooral geïnteresseerd in intervallen voor voorspellingen: predictie-intervallen (prediction intervals). Een predictie-interval geeft aan waar we verwachten dat een nieuwe observatie zal liggen.
Een predictie-interval kwantificeert de onzekerheid over een nieuwe individuele observatie. Een betrouwbaarheidsinterval, daarentegen, kwantificeert de onzekerheid over de schatting van een populatieparameter (bijv. ).
Predictie-intervallen zijn altijd breder dan betrouwbaarheidsintervallen omdat ze rekening houden met twee bronnen van onzekerheid:
Onzekerheid over de parameters (net als betrouwbaarheidsintervallen)
Inherente variabiliteit in de data ()
Bij lineaire regressie hebben we voor een nieuwe observatie met features de puntvoorspelling:
Het 95% predictie-interval is:
waarbij de standaardfout van de voorspelling is:
met de leverage of hat value.
Interpretatie van de componenten:
: De geschatte standaarddeviatie van de residuen (inherente variabiliteit)
1: Komt van de inherente ruis in nieuwe observaties
: De leverage of hat value - meet hoe ver de nieuwe observatie ligt van het centrum van de trainingdata
Kleine (dicht bij centrum): Lage extra onzekerheid, voorspelling is betrouwbaar
Grote (ver van centrum): Hoge extra onzekerheid, extrapolatie buiten trainingsgebied
Likelihood ratio test¶
We kunnen via een probabilistische modelformulering ook de goodness of fit van verschillende modellen met elkaar vergelijken bij dezelfde trainingsdata. De likelihood ratio test vergelijkt de likelihood van twee geneste modellen: een volledig model met parameters versus een gereduceerd model met parameters. De teststatistiek is:
waarbij de likelihood van het gereduceerde model is en de likelihood van het volledige model. De intuïtie is de volgende:
: De nulhypothese stelt dat het gereduceerde model een even goede fit voor de data biedt
: De alternatieve hypothese stelt dat het volledige model een betere fit geeft
volgt asymptotisch een -verdeling met vrijheidsgraden onder . Indien wordt het complexere model verkozen.
Illustratie¶
Hier demonstreren we het lineaire regressiemodel met homogene Gaussiaanse ruis opnieuw met de gesimuleerde data van de relatie tussen de grootte van een bestelling in een koffiehuis en de fooi die klanten erbovenop betalen.
Parameterschatting¶
import matplotlib.pyplot as plt
import numpy as np
from scipy import stats
from ml_courses.sim.monte_carlo_tips import MonteCarloTipsSimulation
# Generate the same tips dataset
rng = np.random.default_rng(42)
sim = MonteCarloTipsSimulation()
# Fit the linear regression model using OLS
X = np.column_stack([np.ones(len(sim.order_totals)), sim.order_totals])
y = sim.observed_tips
# Compute OLS estimates
XtX_inv = np.linalg.inv(X.T @ X)
b_hat = XtX_inv @ X.T @ y
# Compute residuals and estimate sigma
residuals = y - X @ b_hat
N = len(y)
M = 2 # number of parameters (intercept + slope)
sigma_hat = np.sqrt(np.sum(residuals**2) / (N - M))
print(f"Estimated model: Tip = {b_hat[0]:.3f} + {b_hat[1]:.3f} × Order Total")
print(f"Estimated σ: {sigma_hat:.3f}")
print(f"True model: Tip = {sim.true_b1:.3f} + {sim.true_b2:.3f} × Order Total")
print(f"True σ: {sim.noise_std:.3f}")Estimated model: Tip = 0.559 + 0.143 × Order Total
Estimated σ: 0.227
True model: Tip = 0.500 + 0.150 × Order Total
True σ: 0.300
Betrouwbaarheidsintervallen¶
Hier berekenen we de betrouwbaarheidsintervallen voor de parameters (intercept) en (slope).
# Compute standard errors for parameters
# SE(b_j) = σ * sqrt([(X^T X)^{-1}]_{jj})
se_b = sigma_hat * np.sqrt(np.diag(XtX_inv))
# 95% confidence intervals using t-distribution
alpha = 0.05
t_critical = stats.t.ppf(1 - alpha / 2, df=N - M)
ci_lower = b_hat - t_critical * se_b
ci_upper = b_hat + t_critical * se_b
print("95% Confidence intervals for parameters:")
print(f" b₀ (intercept): [{ci_lower[0]:.3f}, {ci_upper[0]:.3f}]")
print(f" b₁ (slope): [{ci_lower[1]:.3f}, {ci_upper[1]:.3f}]")
print("\nTrue values:")
print(f" b₀ (intercept): {sim.true_b1:.3f}")
print(f" b₁ (slope): {sim.true_b2:.3f}")95% Confidence intervals for parameters:
b₀ (intercept): [0.390, 0.728]
b₁ (slope): [0.132, 0.153]
True values:
b₀ (intercept): 0.500
b₁ (slope): 0.150
Predictie-intervallen¶
Nu berekenen we de predictie-intervallen voor nieuwe observaties over het bereik van order totals.
# Create a range of order totals for prediction
order_range = np.linspace(sim.order_totals.min(), sim.order_totals.max(), 100)
X_new = np.column_stack([np.ones(len(order_range)), order_range])
# Point predictions
y_pred = X_new @ b_hat
# Compute leverage (hat values) for each new point
# h_new = x_new^T (X^T X)^{-1} x_new
h_new = np.sum((X_new @ XtX_inv) * X_new, axis=1)
# Standard error for predictions
# SE_pred = σ * sqrt(1 + h_new)
se_pred = sigma_hat * np.sqrt(1 + h_new)
# 95% prediction intervals
pred_lower = y_pred - t_critical * se_pred
pred_upper = y_pred + t_critical * se_pred
# Also compute confidence intervals for the mean response (without the "1" term)
# SE_mean = σ * sqrt(h_new)
se_mean = sigma_hat * np.sqrt(h_new)
mean_lower = y_pred - t_critical * se_mean
mean_upper = y_pred + t_critical * se_mean
print(f"Average leverage (hat value): {h_new.mean():.4f}")
print(f"Min leverage: {h_new.min():.4f} (at center)")
print(f"Max leverage: {h_new.max():.4f} (at extremes)")
print(f"\nAverage width of prediction interval: {2 * t_critical * se_pred.mean():.3f}")
print(f"Average width of confidence interval (mean): {2 * t_critical * se_mean.mean():.3f}")Average leverage (hat value): 0.0393
Min leverage: 0.0200 (at center)
Max leverage: 0.0826 (at extremes)
Average width of prediction interval: 0.933
Average width of confidence interval (mean): 0.177
Visualisatie¶
Source
fig, ax = plt.subplots(figsize=(14, 8))
# Plot the observed data
ax.scatter(
sim.order_totals,
sim.observed_tips,
alpha=0.6,
color="saddlebrown",
s=80,
edgecolor="white",
linewidth=1,
label="Observed tips",
zorder=3,
)
# Plot the true relationship
true_tips = sim.true_b1 + sim.true_b2 * order_range
ax.plot(
order_range,
true_tips,
"r--",
linewidth=2.5,
label=f"True relationship: {sim.true_b1:.2f} + {sim.true_b2:.2f} × Order",
zorder=2,
)
# Plot the fitted line
ax.plot(
order_range,
y_pred,
"b-",
linewidth=2.5,
label=f"Fitted line: {b_hat[0]:.2f} + {b_hat[1]:.2f} × Order",
zorder=2,
)
# Plot confidence interval for mean response
ax.fill_between(
order_range,
mean_lower,
mean_upper,
alpha=0.3,
color="blue",
label="95% Confidence band (mean)",
zorder=1,
)
# Plot prediction interval
ax.fill_between(
order_range,
pred_lower,
pred_upper,
alpha=0.15,
color="green",
label="95% Prediction band (new observation)",
zorder=0,
)
ax.set_xlabel("Order Total ($)", fontsize=12, fontweight="bold")
ax.set_ylabel("Tip Amount ($)", fontsize=12, fontweight="bold")
ax.set_title(
"☕ Confidence Bands vs Prediction Bands",
fontsize=14,
fontweight="bold",
pad=20,
)
ax.legend(loc="upper left", fontsize=10, framealpha=0.95)
ax.grid(True, alpha=0.3, linestyle="--")
plt.tight_layout()
plt.show()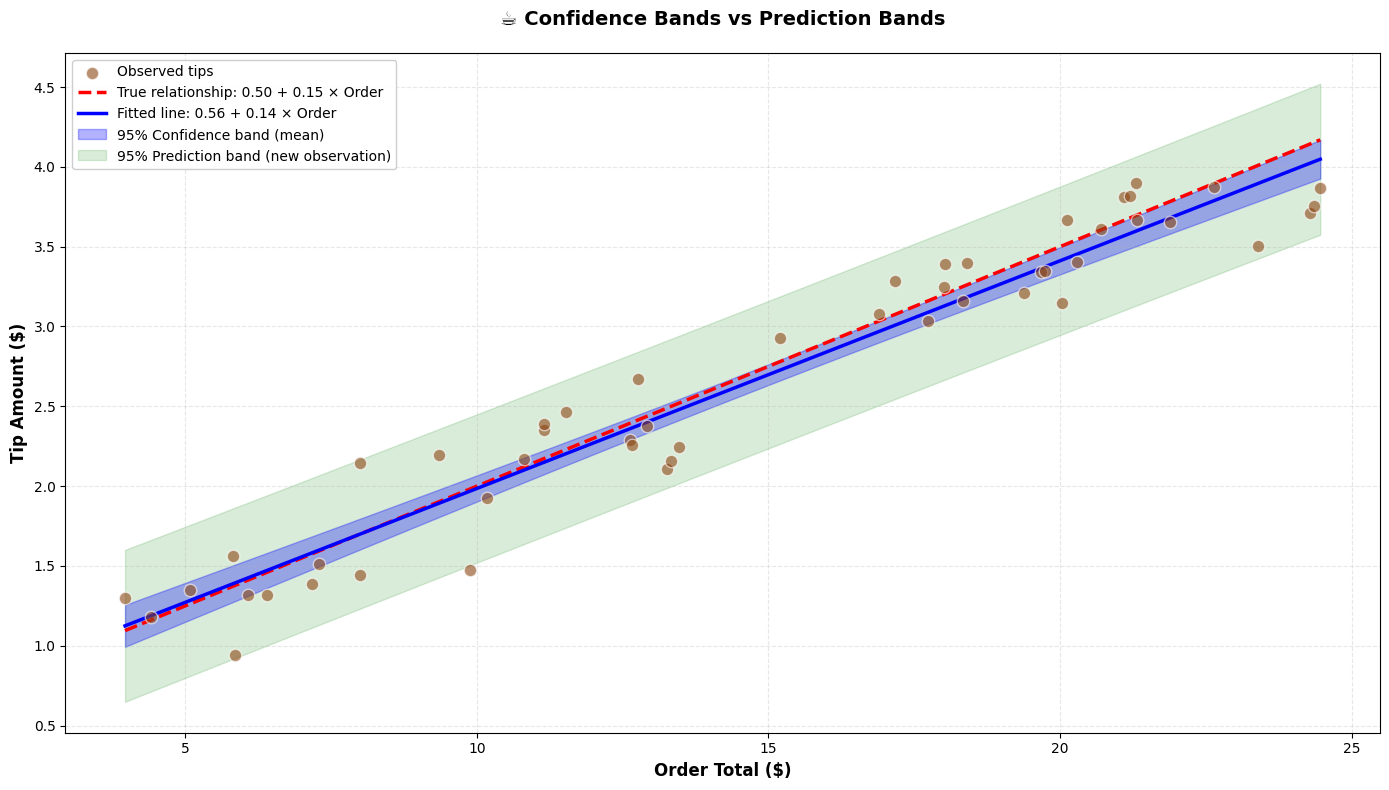
Leverage¶
Hier visualiseren we de _leverage (hat values) waardoor we kunnen zien hoe de onzekerheid varieert over de range van order totals.
Source
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(16, 6))
# Left plot: Leverage values
ax1.plot(order_range, h_new, "purple", linewidth=2.5)
ax1.axhline(
h_new.mean(),
color="orange",
linestyle="--",
linewidth=2,
label=f"Average: {h_new.mean():.4f}",
)
ax1.set_xlabel("Order Total ($)", fontsize=12, fontweight="bold")
ax1.set_ylabel("Leverage (hat value)", fontsize=12, fontweight="bold")
ax1.set_title("Leverage over Order Totals", fontsize=13, fontweight="bold")
ax1.legend(fontsize=10)
ax1.grid(True, alpha=0.3)
# Add annotations
center_x = sim.order_totals.mean()
min_leverage_idx = np.argmin(np.abs(order_range - center_x))
ax1.annotate(
"Lowest leverage\n(at data center)",
xy=(order_range[min_leverage_idx], h_new[min_leverage_idx]),
xytext=(center_x + 5, h_new.max() * 0.6),
arrowprops={"arrowstyle": "->", "color": "green", "lw": 2},
fontsize=10,
color="green",
fontweight="bold",
)
max_leverage_idx = np.argmax(h_new)
ax1.annotate(
"Highest leverage\n(at extremes)",
xy=(order_range[max_leverage_idx], h_new[max_leverage_idx]),
xytext=(order_range[max_leverage_idx] - 8, h_new[max_leverage_idx] - 0.01),
arrowprops={"arrowstyle": "->", "color": "red", "lw": 2},
fontsize=10,
color="red",
fontweight="bold",
)
# Right plot: Components of prediction SE
ax2.plot(
order_range,
sigma_hat * np.ones_like(order_range),
"b-",
linewidth=2,
label=r"$\hat{\sigma}$ (inherent noise)",
)
ax2.plot(
order_range,
sigma_hat * np.sqrt(h_new),
"r-",
linewidth=2,
label=r"$\hat{\sigma}\sqrt{h_{new}}$ (parameter uncertainty)",
)
ax2.plot(
order_range,
se_pred,
"g-",
linewidth=2.5,
label=r"$\text{SE}_{pred} = \hat{\sigma}\sqrt{1 + h_{new}}$",
)
ax2.set_xlabel("Order Total ($)", fontsize=12, fontweight="bold")
ax2.set_ylabel("Standard Error ($)", fontsize=12, fontweight="bold")
ax2.set_title("Components of Prediction Standard Error", fontsize=13, fontweight="bold")
ax2.legend(fontsize=10)
ax2.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()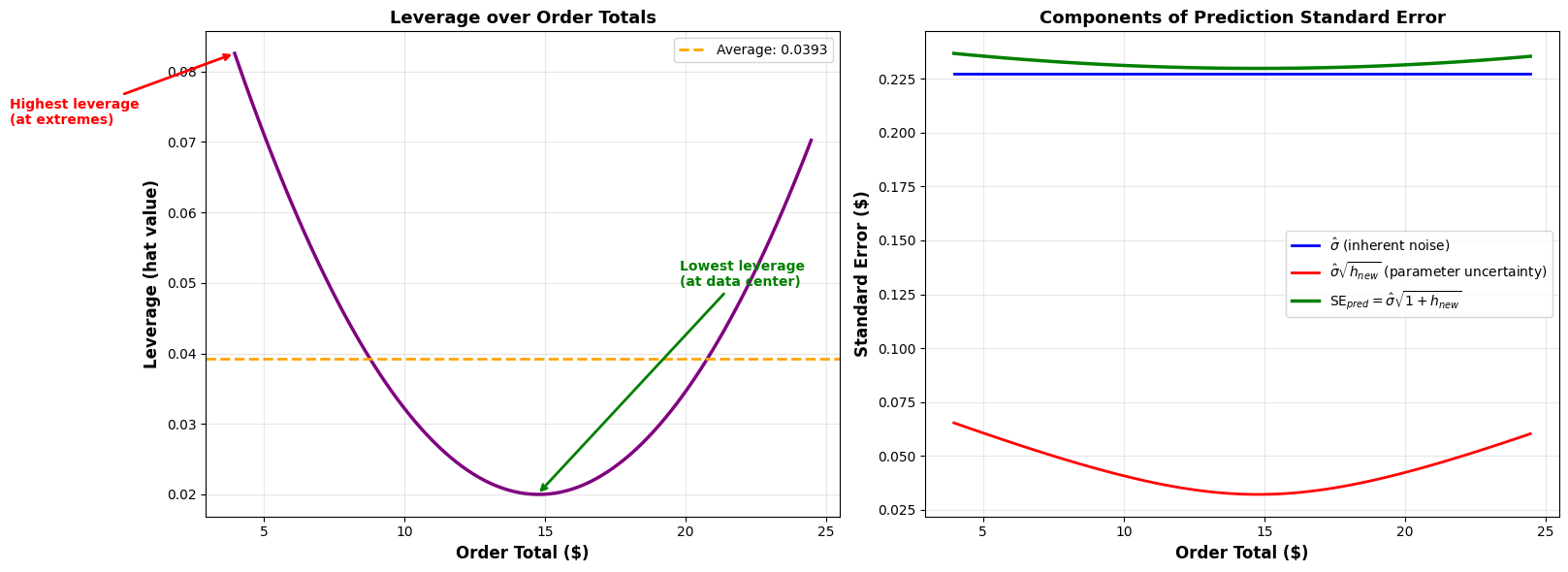
Likelihood ratio test¶
Here we test whether the slope parameter contributes significantly to the model by comparing the full model (with intercept and slope) to a reduced model (intercept only).
# Model 1: Full model with intercept and slope
# Already fitted: y = b_0 + b_1 * x
# Compute log-likelihood for full model
log_likelihood_full = -N / 2 * np.log(2 * np.pi * sigma_hat**2) - np.sum(residuals**2) / (
2 * sigma_hat**2
)
# Model 0: Reduced model (intercept only)
# y = b_0 (mean model)
b0_reduced = np.mean(y)
residuals_reduced = y - b0_reduced
sigma_reduced = np.sqrt(np.sum(residuals_reduced**2) / (N - 1))
# Compute log-likelihood for reduced model
log_likelihood_reduced = -N / 2 * np.log(2 * np.pi * sigma_reduced**2) - np.sum(
residuals_reduced**2
) / (2 * sigma_reduced**2)
# Likelihood ratio test statistic
Lambda = -2 * (log_likelihood_reduced - log_likelihood_full)
# Degrees of freedom: difference in number of parameters
df = 1 # M_1 - M_0 = 2 - 1
# Critical value from chi-squared distribution (alpha = 0.05)
alpha = 0.05
chi2_critical = stats.chi2.ppf(1 - alpha, df)
# P-value
p_value = 1 - stats.chi2.cdf(Lambda, df)
print(f"Model 0 (reduced): Tip = {b0_reduced:.3f}")
print(f" Log-likelihood: {log_likelihood_reduced:.3f}")
print(f" σ: {sigma_reduced:.3f}\n")
print(f"Model 1 (full): Tip = {b_hat[0]:.3f} + {b_hat[1]:.3f} × Order")
print(f" Log-likelihood: {log_likelihood_full:.3f}")
print(f" σ: {sigma_hat:.3f}\n")
print(f"Test statistic Λ = {Lambda:.3f}")
print(f"Degrees of freedom: {df}")
print(f"Critical value (χ² at α={alpha}): {chi2_critical:.3f}")
print(f"P-value: {p_value:.6f}\n")
if Lambda > chi2_critical:
print("✓ CONCLUSION: Reject H₀")
print(
f" The slope parameter contributes significantly to the model ({Lambda:.3f} > {chi2_critical:.3f})"
)
else:
print("✗ CONCLUSION: Do not reject H₀")
print(f" The slope parameter is not significant ({Lambda:.3f} ≤ {chi2_critical:.3f})")Model 0 (reduced): Tip = 2.666
Log-likelihood: -65.672
σ: 0.909
Model 1 (full): Tip = 0.559 + 0.143 × Order
Log-likelihood: 4.087
σ: 0.227
Test statistic Λ = 139.518
Degrees of freedom: 1
Critical value (χ² at α=0.05): 3.841
P-value: 0.000000
✓ CONCLUSION: Reject H₀
The slope parameter contributes significantly to the model (139.518 > 3.841)