📚 [1]
Kansrekenen, waarschijnlijkheidsleer of probabiliteitstheorie is een wiskundig kader om uitspraken te doen over onzekerheid. Het laat toe om onzekerheid te kwantificeren en biedt axioma’s om nieuwe onzekere uitspraken af te leiden uit bestaande. Het kan gezien worden als een uitbreiding van Booleaanse logica naar situaties die onzekerheid inhouden Jaynes (2003).
Kans Waarschijnlijkheid Probabiliteit
Bij AI-toepassingen gebruiken we kansrekenen op twee manieren:
Aangezien de wetten van kansrekenen bepalen hoe AI-systemen moeten redeneren over onzekerheid, kunnen we bij het ontwerp van modellen handig gebruik maken van verschillende expressies uit de probabiliteitstheorie.
We zagen reeds hoe we de logistische en softmax activatiefuncties gebruiken zodat we de output van neurale netwerken kunnen interpreteren als een kansverdeling. Zo kunnen we de voorspelling met de hoogste kans selecteren en ook nagaan hoe zeker/onzeker voorspellingen zijn. Voor dit laatste kunnen we een beroep doen op informatietheorie.
We zullen later ook zien dat we probabiliteitstheorie ook kunnen gebruiken om parameterschattingen te bekomen.
We kunnen probabiliteit ook gebruiken om het gedrag van voorgestelde AI-systemen te analyseren. Dit valt onder het domein van statistische analyse. Hierbij willen we de probabilistische eigenschappen van een systeem in kaart brengen.
Zo kunnen we bijvoorbeeld bepaalde (ongegronde) voorkeuren (zoals gender bias) in de voorspellingen nagaan en remediëren. We kunnen probabiliteitstheorie ook gebruiken om te bewijzen dat een bepaald model beter presteert dan een ander niet zomaar bij wijze van toeval, maar op een systematische manier.
Waarom kansrekenen?¶
Veel domeinen binnen de computerwetenschappen werken voornamelijk met entiteiten die volledig deterministisch (vooraf bepaald) zijn. Een programmeur kan er meestal van uitgaan dat een CPU iedere machine-instructie foutloos uitvoert. Er kunnen hardwarefouten optreden, maar die zijn zo zeldzaam dat een programmeur er geen rekening mee hoeft te houden.
In machine learning daarentegen moeten we altijd rekening houden met het tegenovergestelde van “deterministisch”: stochasticiteit (onbepaaldheid, randomness, willekeurigheid). Er zijn drie mogelijke bronnen:
Inherente stochasticiteit
Het systeem dat gemodelleerd wordt kan intrinsiek willekeurig zijn. Bijvoorbeeld, een kaartspel waarbij de kaarten in een random volgorde zitten.Onvolledige observeerbaarheid
Zelfs deterministische systemen kunnen stochastisch lijken wanneer we niet alle variabelen kunnen observeren die het gedrag van het systeem bepalen. Een klassiek voorbeeld is het Monty Hall-probleem: een kandidaat van een spelshow moet kiezen tussen drie deuren en wint een prijs achter de gekozen deur. Twee deuren leiden naar een geit, de derde naar een auto[2]. De uitkomst, gegeven de keuze van de kandidaat, is deterministisch, maar vanuit het perspectief van de kandidaat is de uitkomst onzeker.Onvolledige modellering
Wanneer we een model gebruiken dat sommige geobserveerde informatie moet negeren, resulteert de weggelaten informatie in onzekere voorspellingen. Bijvoorbeeld, als een robot de locatie van alle objecten rond zich exact kan observeren maar de ruimte discretiseert (in cellen opdeelt) bij het voorspellen van toekomstige locaties, dan zijn de voorspellingen automatisch onzeker binnen de dimensies van de cellen.
Frequentistische vs. Bayesiaanse probabiliteit¶
Kansrekenen was oorspronkelijk bedoeld om de frequentie van gebeurtenissen te analyseren, zoals bijvoorbeeld de kans op een bepaalde combinatie van kaarten in een pokerspel. Dit soort gebeurtenissen zijn meestal herhaalbaar: als we zeggen dat een bepaalde gebeurtenis een kans heeft om voor te vallen, wil dat zeggen dat als we het experiment een oneindig aantal keer zouden herhalen, we die gebeurtenis in van de gevallen zullen tegenkomen.
Deze benadering beschouwt probabiliteit als de relatieve frequentie waarmee gebeurtenissen plaatsvinden en wordt daarom de frequentistische benadering genoemd.
Dit soort redeneringen over probabiliteit kunnen we echter niet toepassen bij uitkomsten die niet herhaalbaar zijn. Neem bijvoorbeeld de situatie waarbij we zeggen dat er een kans is dat de nieuwe GTA versie morgen uitkomt. Hier heeft geen betrekking op een frequentie (we kunnen de situatie niet een oneindig aantal keren repliceren), maar op een bepaalde mate van geloof (degree of belief).
Deze benadering heet de Bayesiaanse[3] interpretatie van probabiliteit. Hier heeft probabiliteit betrekking op de mate van geloof (degree of belief) in een bepaalde hypothese, waarbij 1 absolute zekerheid aanduidt en 0 absolute zekerheid dat iets niet het geval is.
Random variabelen¶
Een random, kans- of stochastische variabele is een variabele die willekeurig verschillende waarden kan aannemen. We duiden de random variabele aan met een kleine letter in plain text (bv. ), en specifieke realisaties met subscripts (bv. en ). In het geval van vectoren gebruiken we om de variabele aan te duiden en voor realisaties.
Random variabelen kunnen discreet of continu zijn:
Discrete random variabele: Heeft een eindig of aftelbaar oneindig[4] aantal waarden. Deze waarden hoeven niet noodzakelijk integers te zijn; ze kunnen ook nominaal zijn.
Continue random variabele: Geassocieerd met een reële waarde.
Kansverdelingen¶
Een kansverdeling (probability distribution) beschrijft hoe waarschijnlijk een random variabele of set van random variabelen elk van zijn mogelijke waarden aanneemt. De manier waarop we kansverdelingen beschrijven verschilt naargelang de random variabele discreet of continu is.
Discrete variabelen: Probability Mass Functions¶
Een kansverdeling over discrete waarden wordt beschreven met een probability mass function (PMF). We duiden deze functies aan met een hoofdletter .
De PMF verbindt de verschillende waarden die een discrete random variabele kan aannemen met de kans dat de variabele die waarden aanneemt. De kans dat wordt genoteerd als , waarbij:
Een kans van 1 aanduidt dat zeker is
Een kans van 0 aanduidt dat onmogelijk is
Source
import matplotlib.pyplot as plt
import numpy as np
from scipy import statsSource
# Example: Discrete uniform distribution over a die roll
k = 6 # Six-sided die
outcomes = np.arange(1, k + 1)
probabilities = np.ones(k) / k
fig, ax = plt.subplots(figsize=(10, 6))
ax.bar(outcomes, probabilities, color="steelblue", alpha=0.7, edgecolor="black", linewidth=1.5)
ax.set_xlabel("Outcome", fontsize=12, fontweight="bold")
ax.set_ylabel("Probability P(x)", fontsize=12, fontweight="bold")
ax.set_title("Discrete Uniform Distribution over Die Roll", fontsize=14, fontweight="bold")
ax.set_xticks(outcomes)
ax.set_ylim(0, 0.25)
ax.grid(axis="y", alpha=0.3, linestyle="--")
# Add probability values on bars
for outcome, prob in zip(outcomes, probabilities, strict=False):
ax.text(outcome, prob + 0.01, f"{prob:.3f}", ha="center", va="bottom", fontsize=10)
plt.tight_layout()
plt.show()
print(f"Sum of probabilities: {probabilities.sum():.1f} (must be 1.0)")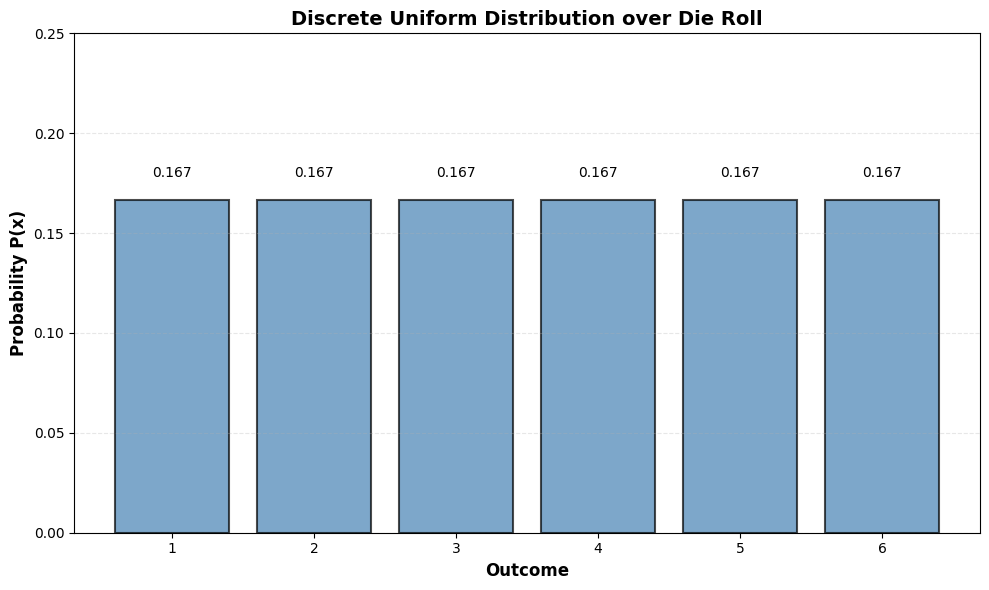
Sum of probabilities: 1.0 (must be 1.0)
Continue variabelen: Probability Density Functions¶
Voor continue random variabelen gebruiken we een probability density function (PDF) in plaats van een probability mass function. We duiden deze functies aan met een kleine letter .
Voor een uniforme distributie op interval met krijgen we:
We noteren dit als .
Source
# Example: Continuous uniform distribution
a, b = 2, 8
x = np.linspace(0, 10, 1000)
pdf = np.where((x >= a) & (x <= b), 1 / (b - a), 0)
fig, ax = plt.subplots(figsize=(12, 6))
ax.plot(x, pdf, "b-", linewidth=2.5, label=f"U({a},{b})")
ax.fill_between(x, pdf, alpha=0.3, color="blue")
# Highlight probability of interval [3, 5]
x_interval = x[(x >= 3) & (x <= 5)]
pdf_interval = pdf[(x >= 3) & (x <= 5)]
ax.fill_between(
x_interval,
pdf_interval,
alpha=0.6,
color="red",
label=f"P(x ∈ [3,5]) = {(5 - 3) / (b - a):.3f}",
)
ax.set_xlabel("x", fontsize=12, fontweight="bold")
ax.set_ylabel("p(x)", fontsize=12, fontweight="bold")
ax.set_title("Continuous Uniform Distribution", fontsize=14, fontweight="bold")
ax.set_ylim(0, 0.25)
ax.grid(alpha=0.3, linestyle="--")
ax.legend(fontsize=11)
ax.axhline(y=0, color="black", linewidth=0.8)
ax.axvline(x=a, color="gray", linestyle="--", alpha=0.5)
ax.axvline(x=b, color="gray", linestyle="--", alpha=0.5)
plt.tight_layout()
plt.show()
print(f"Height of PDF in [{a},{b}]: {1 / (b - a):.4f}")
print(f"Integral over entire domain: {(b - a) * (1 / (b - a)):.1f}")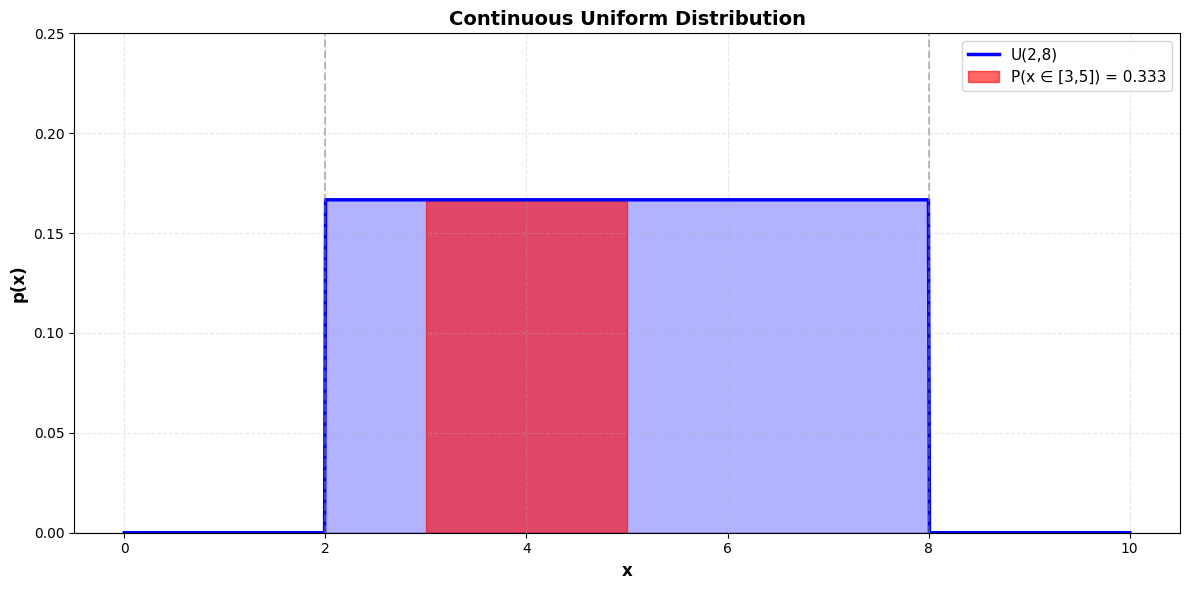
Height of PDF in [2,8]: 0.1667
Integral over entire domain: 1.0
Theoretische en empirische kansverdelingen¶
In het algemene geval weten we bij observaties van random variabelen, behalve de discrete of continue eigenschap, nooit vooraf met welke kansverdeling we precies te maken hebben. In sommige gevallen wordt zonder meer een assumptie gemaakt, bijvoorbeeld de aanname dat we met een eerlijke dobbelsteen te maken hebben en de PMF dus neerkomt op:
In het geval van continue random variabelen wordt vaak de assumptie gemaakt dat de PDF een Gauss- of normaalverdeling volgt met als algemene vorm:
Dit zijn beide voorbeelden van theoretische distributies. We zullen later zien dat dergelijke volledig wiskundig beschreven verdelingen interessante implicaties hebben in de context van ML.
Als we over theoretische kansverdelingen spreken, gaat het telkens over een hypothese (de populatieverdeling genoemd in de statistiek). In realiteit hebben we altijd te maken met steekproeven (samples) en steekproefverdelingen. Als we de assumptie maken dat de data een bepaalde theoretische verdeling volgt, betekent dat dat we ervan uitgaan dat de steekproefverdeling die bepaalde populatieverdeling zal benaderen als we de steekproef oneindig groot maken.
Wanneer we een steekproef nemen, kunnen we de geobserveerde kansen binnen de steekproef weergeven.
Bij een discrete random variabele kunnen we simpelweg voor iedere mogelijke uitkomst de frequentie binnen de steekproef berekenen en visualiseren met een staafdiagram. Bij continue random variabelen maken we meestal gebruik van een histogram. We berekenen dan de frequenties binnen zelf gekozen intervallen (bins).
In beide gevallen spreken we dan over de empirische kansverdeling. Het grote verschil met theoretische verdelingen is dat ze, buiten de algemene eigenschappen van PMFs en PDFs, geen verdere wiskundige specificaties hebben. Ze worden dan ook meestal gebruikt om na te gaan met welke theoretische verdeling ze het best overeenkomen zodat met de specificaties van die verdeling verder gewerkt kan worden.
Source
# Example: Theoretical vs Empirical Distribution
# Population parameters
mu = 175 # mean height in cm
sigma = 10 # standard deviation in cm
# Generate samples
rng = np.random.default_rng(42)
sample_size = 100
sample = rng.normal(mu, sigma, sample_size)
# Create figure with different bin sizes
fig, axes = plt.subplots(2, 2, figsize=(14, 10))
# Theoretical distribution curve
x_theory = np.linspace(mu - 4 * sigma, mu + 4 * sigma, 1000)
y_theory = stats.norm.pdf(x_theory, mu, sigma)
bin_sizes = [5, 10, 20, 50]
for ax, n_bins in zip(axes.flatten(), bin_sizes, strict=False):
# Plot histogram (empirical distribution)
counts, bins, patches = ax.hist(
sample,
bins=n_bins,
density=True,
alpha=0.6,
color="steelblue",
edgecolor="black",
linewidth=1.2,
label=f"Empirical (n={sample_size}, bins={n_bins})",
)
# Plot theoretical distribution
ax.plot(x_theory, y_theory, "r-", linewidth=2.5, label=f"Theoretical N({mu},{sigma}²)")
# Styling
ax.set_xlabel("Height (cm)", fontsize=11, fontweight="bold")
ax.set_ylabel("Probability Density", fontsize=11, fontweight="bold")
ax.set_title(f"Bins = {n_bins}", fontsize=12, fontweight="bold")
ax.legend(fontsize=9)
ax.grid(alpha=0.3, axis="y")
ax.set_xlim(mu - 4 * sigma, mu + 4 * sigma)
# Highlight empty bins if any
empty_bins = np.sum(counts == 0)
if empty_bins > 0:
ax.text(
0.98,
0.95,
f"{empty_bins} empty bins",
transform=ax.transAxes,
fontsize=9,
bbox={"boxstyle": "round", "facecolor": "yellow", "alpha": 0.7},
ha="right",
va="top",
)
# Show bin width
bin_width = bins[1] - bins[0]
ax.text(
0.02,
0.95,
f"Bin width: {bin_width:.1f} cm",
transform=ax.transAxes,
fontsize=9,
bbox={"boxstyle": "round", "facecolor": "lightblue", "alpha": 0.7},
ha="left",
va="top",
)
plt.suptitle("Empirical vs Theoretical Distribution", fontsize=15, fontweight="bold", y=0.995)
plt.tight_layout()
plt.show()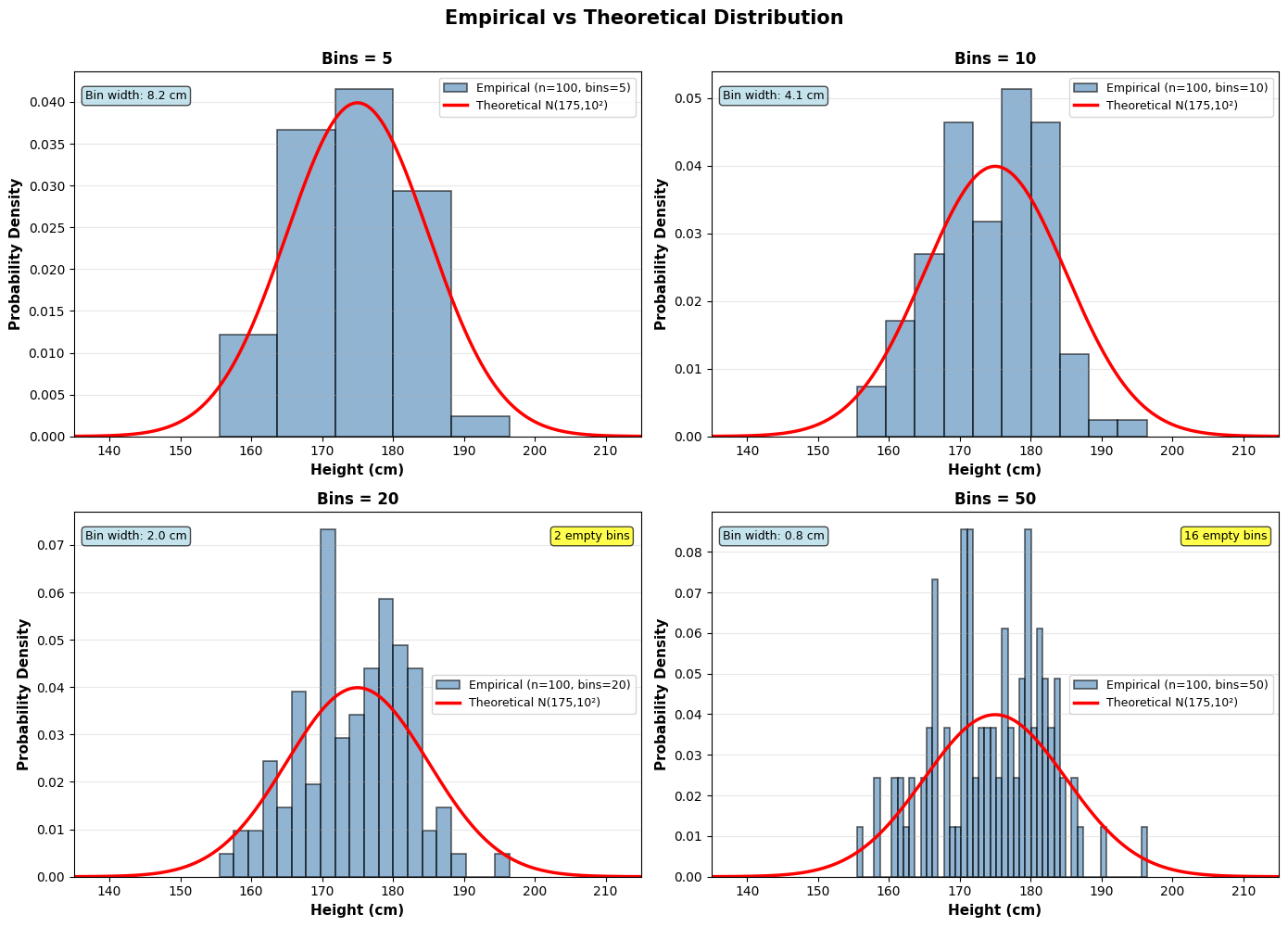
Combinaties van kansvariabelen¶
Tot nu toe hebben we gekeken naar individuele kansvariabelen. De regels van kansrekenen worden pas echt interessant als we naar combinaties van kansvariabelen kijken.
Het voorbeeld illustreert dat we bij twee of meerdere kansvariabelen de verdeling als een gezamenlijke (joint) distributie kunnen zien. Die distributie behoudt de eigenschappen van een enkelvoudige PMF of PDF.
Marginale kans¶
Soms kennen we de kansverdeling over een set van meerdere variabelen en willen we de verdeling over slechts een deelverzameling ervan kennen. De kansverdeling over de deelverzameling wordt de marginale kansverdeling genoemd.
Voor discrete random variabelen en en hun gezamenlijke verdeling kunnen we de marginale verdeling vinden met de som regel:
Voor continue variabelen gebruiken we integratie in plaats van sommatie:
Conditionele kans¶
In veel gevallen zijn we geïnteresseerd in de kans van een gebeurtenis, gegeven dat een andere gebeurtenis plaatsvond. Dit heet een conditionele kans.
We noteren de conditionele kans dat gegeven als . Deze wordt berekend met de formule:
Source
# Example: Marginal and Conditional Distributions with 2D Gaussian
# Create a 2D Gaussian distribution with correlation
# Parameters for bivariate normal distribution
mu_x, mu_y = 0, 0 # means
sigma_x, sigma_y = 1.5, 1.0 # standard deviations
rho = 0.7 # correlation coefficient
# Covariance matrix
cov_matrix = np.array(
[[sigma_x**2, rho * sigma_x * sigma_y], [rho * sigma_x * sigma_y, sigma_y**2]]
)
# Create grid for evaluation
x = np.linspace(-4, 4, 200)
y = np.linspace(-3, 3, 200)
X, Y = np.meshgrid(x, y)
pos = np.dstack((X, Y))
# Compute joint PDF
rv = stats.multivariate_normal([mu_x, mu_y], cov_matrix)
Z = rv.pdf(pos)
# Marginal distributions
pdf_x = stats.norm.pdf(x, mu_x, sigma_x)
pdf_y = stats.norm.pdf(y, mu_y, sigma_y)
# Conditional distribution: p(x|y=y0)
y0 = 1.0 # specific value of y
mu_x_given_y0 = mu_x + rho * (sigma_x / sigma_y) * (y0 - mu_y)
sigma_x_given_y0 = sigma_x * np.sqrt(1 - rho**2)
pdf_x_given_y0 = stats.norm.pdf(x, mu_x_given_y0, sigma_x_given_y0)
# Create figure with custom layout
fig = plt.figure(figsize=(14, 12))
gs = fig.add_gridspec(
3, 3, height_ratios=[1, 3, 0.3], width_ratios=[3, 1, 0.3], hspace=0.05, wspace=0.05
)
# Main plot: joint distribution with contours
ax_joint = fig.add_subplot(gs[1, 0])
contour = ax_joint.contour(X, Y, Z, levels=8, colors="steelblue", linewidths=1.5, alpha=0.6)
contourf = ax_joint.contourf(X, Y, Z, levels=20, cmap="Blues", alpha=0.3)
# Add line indicating y=y0
ax_joint.axhline(y=y0, color="red", linestyle="--", linewidth=2, label=f"y = {y0}")
# Styling
ax_joint.set_xlabel("x", fontsize=12, fontweight="bold")
ax_joint.set_ylabel("y", fontsize=12, fontweight="bold")
ax_joint.set_xlim(-4, 4)
ax_joint.set_ylim(-3, 3)
ax_joint.grid(alpha=0.3, linestyle="--")
ax_joint.legend(fontsize=10, loc="upper right")
# Top plot: marginal p(x) and conditional p(x|y=y0)
ax_top = fig.add_subplot(gs[0, 0], sharex=ax_joint)
ax_top.plot(x, pdf_x, "b-", linewidth=2.5, label="Marginal p(x)")
ax_top.fill_between(x, pdf_x, alpha=0.3, color="blue")
ax_top.plot(x, pdf_x_given_y0, "r-", linewidth=2.5, label=f"Conditional p(x|y={y0})")
ax_top.fill_between(x, pdf_x_given_y0, alpha=0.3, color="red")
ax_top.set_ylabel("Density", fontsize=11, fontweight="bold")
ax_top.set_xlim(-4, 4)
ax_top.legend(fontsize=9, loc="upper right")
ax_top.grid(alpha=0.3, linestyle="--", axis="y")
ax_top.tick_params(labelbottom=False)
# Right plot: marginal p(y)
ax_right = fig.add_subplot(gs[1, 1], sharey=ax_joint)
ax_right.plot(pdf_y, y, "b-", linewidth=2.5, label="Marginal p(y)")
ax_right.fill_betweenx(y, pdf_y, alpha=0.3, color="blue")
ax_right.axhline(y=y0, color="red", linestyle="--", linewidth=2, alpha=0.7)
ax_right.set_xlabel("Density", fontsize=11, fontweight="bold")
ax_right.set_ylim(-3, 3)
ax_right.legend(fontsize=9, loc="upper right")
ax_right.grid(alpha=0.3, linestyle="--", axis="x")
ax_right.tick_params(labelleft=False)
plt.suptitle(
"Marginal and Conditional Distributions for Bivariate Gaussian",
fontsize=14,
fontweight="bold",
y=0.98,
)
plt.show()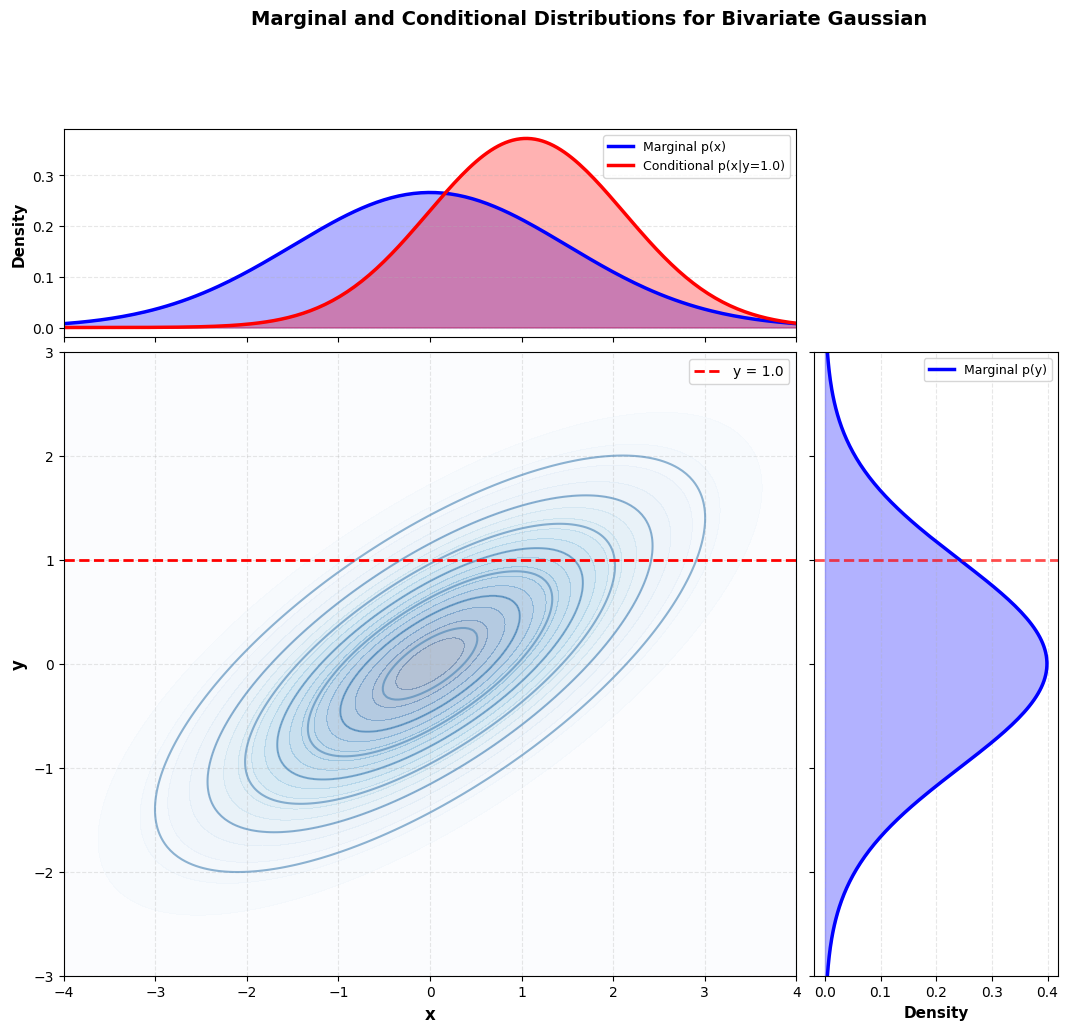
Onafhankelijkheid¶
Van zodra we met twee of meerdere random variabelen te maken krijgen, is het belangrijk om te weten of er al dan niet sprake is van afhankelijkheid tussen de waarden. Wanneer we de lichaamslengte en armlengte in een steekproef meten, zal er een sterke positieve samenhang zijn tussen de uitkomsten van die kansvariabelen. Als we daarentegen de uitkomst van twee gooien met een dobbelsteen tegen elkaar uitzetten, zal er geen sprake zijn van samenhang: de uitkomst van de ene observatie is onafhankelijk van de uitkomst van de andere.
Wanneer twee kansvariabelen onafhankelijk zijn, geldt dat de conditionele verdeling gelijk is aan de marginale verdeling:
Als
dan
Dit impliceert dat de gezamenlijke kansverdeling geschreven kan worden als het product van de marginale verdelingen:
Als
dan
Source
# Example: Independent Variables - Marginal equals Conditional
# Create a 2D Gaussian distribution with NO correlation (rho=0)
# Parameters for bivariate normal distribution with independence
mu_x, mu_y = 0, 0 # means
sigma_x, sigma_y = 1.5, 1.0 # standard deviations
rho = 0.0 # NO correlation - variables are independent
# Covariance matrix (diagonal for independent variables)
cov_matrix = np.array(
[[sigma_x**2, rho * sigma_x * sigma_y], [rho * sigma_x * sigma_y, sigma_y**2]]
)
# Create grid for evaluation
x = np.linspace(-4, 4, 200)
y = np.linspace(-3, 3, 200)
X, Y = np.meshgrid(x, y)
pos = np.dstack((X, Y))
# Compute joint PDF
rv = stats.multivariate_normal([mu_x, mu_y], cov_matrix)
Z = rv.pdf(pos)
# Marginal distributions
pdf_x = stats.norm.pdf(x, mu_x, sigma_x)
pdf_y = stats.norm.pdf(y, mu_y, sigma_y)
# Conditional distribution: p(x|y=y0)
y0 = 1.0 # specific value of y
# For independent variables: mu(x|y) = mu(x) and sigma(x|y) = sigma(x)
mu_x_given_y0 = mu_x + rho * (sigma_x / sigma_y) * (y0 - mu_y) # = mu_x when rho=0
sigma_x_given_y0 = sigma_x * np.sqrt(1 - rho**2) # = sigma_x when rho=0
pdf_x_given_y0 = stats.norm.pdf(x, mu_x_given_y0, sigma_x_given_y0)
# Create figure with custom layout
fig = plt.figure(figsize=(14, 12))
gs = fig.add_gridspec(
3, 3, height_ratios=[1, 3, 0.3], width_ratios=[3, 1, 0.3], hspace=0.05, wspace=0.05
)
# Main plot: joint distribution with contours
ax_joint = fig.add_subplot(gs[1, 0])
contour = ax_joint.contour(X, Y, Z, levels=8, colors="steelblue", linewidths=1.5, alpha=0.6)
contourf = ax_joint.contourf(X, Y, Z, levels=20, cmap="Blues", alpha=0.3)
# Add line indicating y=y0
ax_joint.axhline(y=y0, color="red", linestyle="--", linewidth=2, label=f"y = {y0}")
# Styling
ax_joint.set_xlabel("x", fontsize=12, fontweight="bold")
ax_joint.set_ylabel("y", fontsize=12, fontweight="bold")
ax_joint.set_xlim(-4, 4)
ax_joint.set_ylim(-3, 3)
ax_joint.grid(alpha=0.3, linestyle="--")
ax_joint.legend(fontsize=10, loc="upper right")
# Top plot: marginal p(x) and conditional p(x|y=y0) - IDENTICAL for independent variables
ax_top = fig.add_subplot(gs[0, 0], sharex=ax_joint)
ax_top.plot(x, pdf_x, "b-", linewidth=2.5, label="Marginal p(x)")
ax_top.fill_between(x, pdf_x, alpha=0.3, color="blue")
# Plot conditional on top (will overlay perfectly since they're identical)
ax_top.plot(
x,
pdf_x_given_y0,
"r--",
linewidth=2.5,
alpha=0.8,
label=f"Conditional p(x|y={y0})",
)
ax_top.set_ylabel("Density", fontsize=11, fontweight="bold")
ax_top.set_xlim(-4, 4)
ax_top.legend(fontsize=9, loc="upper right")
ax_top.grid(alpha=0.3, linestyle="--", axis="y")
ax_top.tick_params(labelbottom=False)
# Right plot: marginal p(y)
ax_right = fig.add_subplot(gs[1, 1], sharey=ax_joint)
ax_right.plot(pdf_y, y, "b-", linewidth=2.5, label="Marginal p(y)")
ax_right.fill_betweenx(y, pdf_y, alpha=0.3, color="blue")
ax_right.axhline(y=y0, color="red", linestyle="--", linewidth=2, alpha=0.7)
ax_right.set_xlabel("Density", fontsize=11, fontweight="bold")
ax_right.set_ylim(-3, 3)
ax_right.legend(fontsize=9, loc="upper right")
ax_right.grid(alpha=0.3, linestyle="--", axis="x")
ax_right.tick_params(labelleft=False)
plt.suptitle(
"Independent Variables: Marginal = Conditional (ρ=0)",
fontsize=14,
fontweight="bold",
y=0.98,
)
plt.show()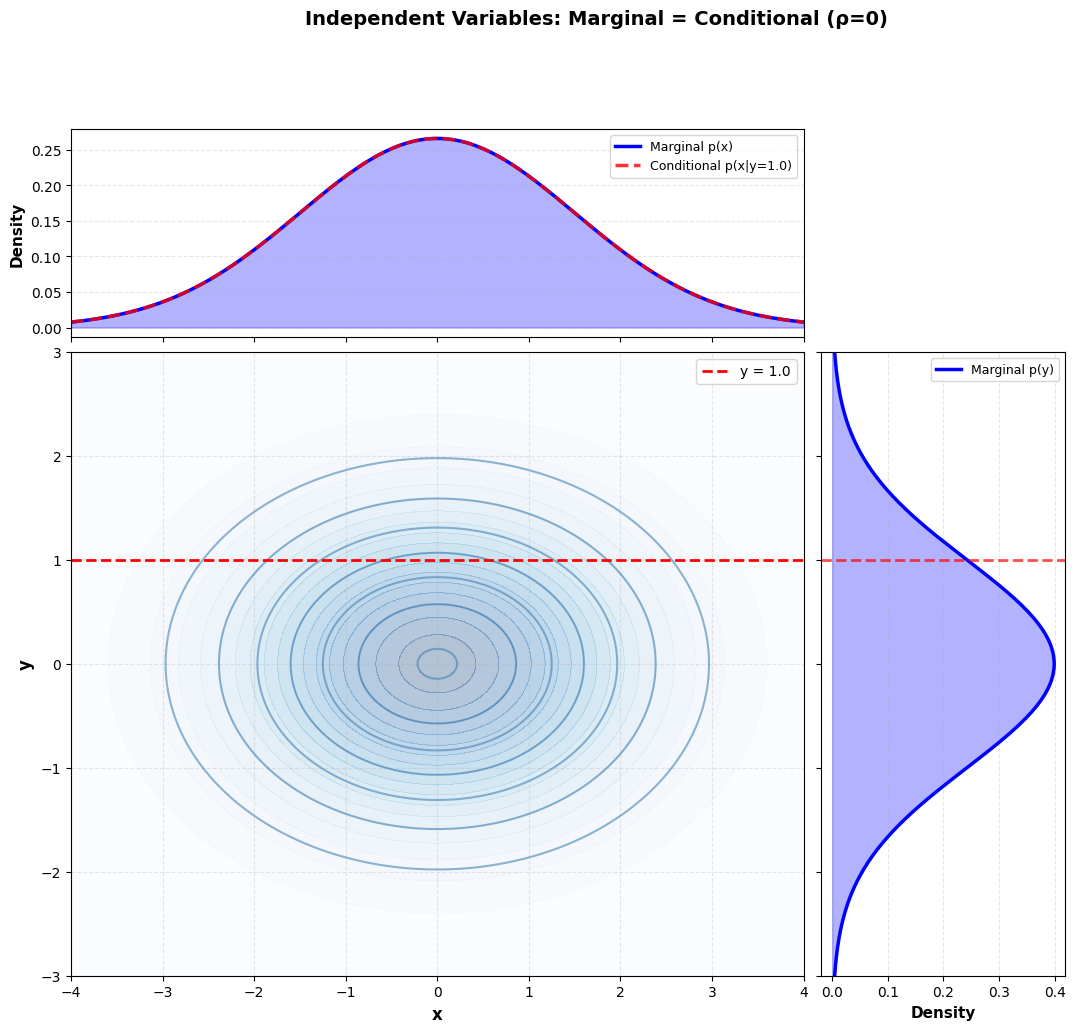
Lineaire samenhang¶
Covariantie¶
Covariantie meet hoe twee kansvariabelen in een lineair verband staan en op welke schaal:
Interpretatie:
Hoge absolute waarden duiden op een tendens om gelijktijdig proportioneel grote afwijkingen ten opzichte van het gemiddelde te tonen.
Positieve covariantie: gelijktijdige afwijkingen hebben dezelfde zin
Negatieve covariantie: gelijktijdige afwijkingen hebben tegengestelde zin
: er is geen lineair verband. ⚠️ Dit impliceert niet automatisch onafhankelijkheid - er kan immers een niet-lineair verband bestaan.
Source
# Example: Zero Covariance but Dependent Variables (Non-linear relationship)
# Generate data with a circular/swirl pattern
n_samples = 1000
theta = rng.uniform(0, 2 * np.pi, n_samples)
r = rng.uniform(0.5, 2, n_samples)
# Circular pattern - clearly dependent but zero covariance
x_circle = r * np.cos(theta)
y_circle = r * np.sin(theta)
# Compute statistics
cov_circle = np.cov(x_circle, y_circle)[0, 1]
corr_circle = np.corrcoef(x_circle, y_circle)[0, 1]
# Create figure with two subplots
fig, axes = plt.subplots(1, 2, figsize=(10, 4), gridspec_kw={"width_ratios": [3, 1]})
# Left plot: Scatter plot
ax = axes[0]
ax.scatter(x_circle, y_circle, alpha=0.6, s=20, color="steelblue", edgecolors="none")
ax.axhline(0, color="gray", linestyle="--", linewidth=1, alpha=0.5)
ax.axvline(0, color="gray", linestyle="--", linewidth=1, alpha=0.5)
ax.set_xlabel("x", fontsize=10, fontweight="bold")
ax.set_ylabel("y", fontsize=10, fontweight="bold")
ax.set_title(r"Non-linear Dependence; $\text{Cov}(x,y) \approx 0$", fontsize=11, fontweight="bold")
ax.set_aspect("equal")
ax.grid(alpha=0.3, linestyle="--")
# Right plot: Statistics text box
ax = axes[1]
ax.axis("off")
textstr = f"""
Cov(x,y) = {cov_circle:.4f}
Corr(x,y) = {corr_circle:.4f}
"""
ax.text(
0.2,
0.5,
textstr,
transform=ax.transAxes,
fontsize=10,
verticalalignment="center",
horizontalalignment="center",
bbox={"boxstyle": "round", "facecolor": "yellow", "alpha": 0.8, "pad": 1},
)
plt.tight_layout()
plt.show()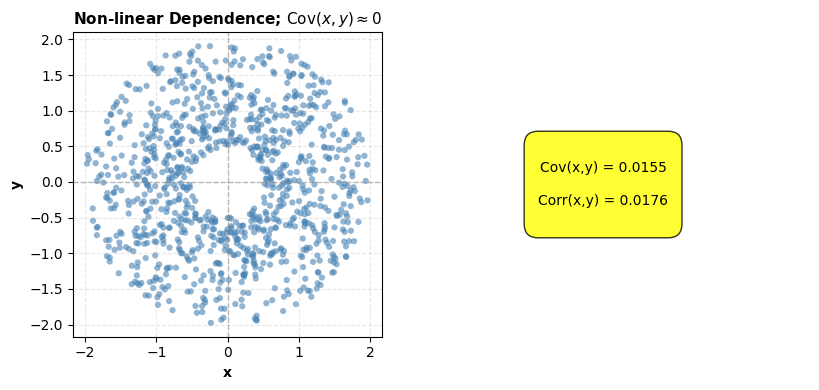
Bij echte onafhankelijke variabelen:
Covariantie van lineaire transformaties:
Correlatie¶
De correlatiecoëfficiënt (of Pearson-correlatie) is de genormaliseerde versie van covariantie:
Eigenschappen:
Bereik:
: Perfecte positieve lineaire relatie ( met )
: Perfecte negatieve lineaire relatie ( met )
: Geen lineaire correlatie (variabelen zijn ongecorreleerd; niet automatisch onafhankelijk)
In tegenstelling tot de covariantie wordt deze maat niet beïnvloed door de schaal van en
Source
# Example: Central Tendency, Moments, and Covariance
# Generate correlated data
n_samples = 1000
x = rng.normal(5, 2, n_samples)
y = 2 * x + rng.normal(0, 1, n_samples) # y is linearly related to x with noise
# Compute statistics
mean_x = np.mean(x)
mean_y = np.mean(y)
var_x = np.var(x)
var_y = np.var(y)
cov_xy = np.cov(x, y)[0, 1]
correlation = cov_xy / (np.sqrt(var_x) * np.sqrt(var_y))
# Visualization
fig, axes = plt.subplots(1, 2, figsize=(14, 6))
# Scatter plot
ax = axes[0]
ax.scatter(x, y, alpha=0.5, s=20, color="steelblue", edgecolors="none")
ax.axvline(mean_x, color="red", linestyle="--", linewidth=2, label=f"E[x] = {mean_x:.2f}")
ax.axhline(mean_y, color="green", linestyle="--", linewidth=2, label=f"E[y] = {mean_y:.2f}")
ax.set_xlabel("x", fontsize=12, fontweight="bold")
ax.set_ylabel("y", fontsize=12, fontweight="bold")
ax.set_title("Scatter Plot: Positive Covariance", fontsize=13, fontweight="bold")
ax.legend(fontsize=10)
ax.grid(alpha=0.3)
# Statistics table
ax = axes[1]
ax.axis("off")
stats_text = f"""
Statistics Summary
{"=" * 40}
Expectation (Mean):
E[x] = {mean_x:.4f}
E[y] = {mean_y:.4f}
Variance:
Var(x) = {var_x:.4f}
Var(y) = {var_y:.4f}
Standard Deviation:
σ(x) = {np.sqrt(var_x):.4f}
σ(y) = {np.sqrt(var_y):.4f}
Covariance:
Cov(x,y) = {cov_xy:.4f}
Correlation:
ρ(x,y) = {correlation:.4f}
Interpretation:
Positive covariance indicates x and y
tend to increase together.
Correlation close to 1 indicates strong
linear relationship.
"""
ax.text(
0.1,
0.5,
stats_text,
fontsize=10,
family="monospace",
verticalalignment="center",
bbox={"boxstyle": "round", "facecolor": "wheat", "alpha": 0.8, "pad": 1},
)
plt.tight_layout()
plt.show()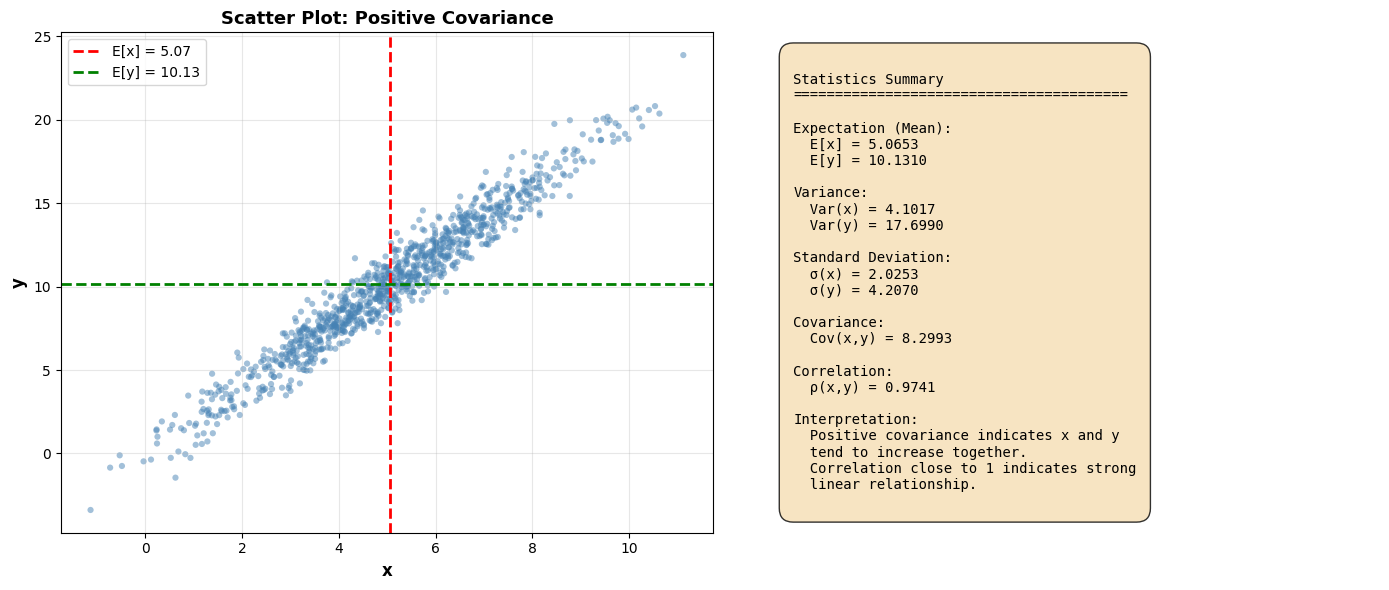
Centrummaten¶
Bij het beschrijven van een kansverdeling is het vaak nuttig om de verdeling te karakteriseren met een beperkt aantal representatieve waarden. De meest gebruikte maten zijn centrummaten (measures of central tendency). Deze geven aan waar het “zwaartepunt” van een kansverdeling ligt.
Verwachte waarde¶
De verwachte waarde van een stochastische variabele is de waarde die deze stochastische variabele gemiddeld genomen zal aannemen. Dit gemiddelde is het gewogen gemiddelde van alle mogelijke uitkomsten met als gewichtsfactor de kans dat een bepaalde waarde zich voordoet.
Voor discrete kansvariabelen vermenigvuldigen we elke mogelijke waarde met zijn kans en tellen alles op:
Voor continue kansvariabelen integreren we vermenigvuldigd met de kansdichtheid:
Verwachte waarden van lineaire transformaties:
Mediaan¶
De mediaan is de waarde waarbij 50% van de kansmassa links en 50% rechts ligt. Bij scheve verdelingen verschilt deze van de verwachte waarde.
Voor een continue random variabele met PDF is de mediaan gedefinieerd als:
Modus¶
De modus is de meest waarschijnlijke waarde (bij discrete verdelingen) of waar de dichtheidsfunctie zijn maximum heeft (bij continue verdelingen).
Voor een continue verdeling:
Source
# Example: Comparing Mean, Median, and Mode across different distributions
fig, axes = plt.subplots(1, 3, figsize=(18, 5))
# 1. Symmetric distribution (Normal): Mean = Median = Mode
ax = axes[0]
mu, sigma = 0, 1
x = np.linspace(-4, 4, 1000)
pdf = stats.norm.pdf(x, mu, sigma)
ax.plot(x, pdf, "b-", linewidth=2.5, label="Normal Distribution")
ax.fill_between(x, pdf, alpha=0.3, color="blue")
# Mean, median, mode are all the same
mean_val = mu
median_val = mu
mode_val = mu
ax.axvline(mean_val, color="red", linestyle="--", linewidth=2, label=f"Mean = {mean_val:.2f}")
ax.axvline(
median_val, color="green", linestyle="-.", linewidth=2, label=f"Median = {median_val:.2f}"
)
ax.axvline(mode_val, color="purple", linestyle=":", linewidth=3, label=f"Mode = {mode_val:.2f}")
ax.set_xlabel("x", fontsize=12, fontweight="bold")
ax.set_ylabel("Density", fontsize=12, fontweight="bold")
ax.set_title("Symmetric Distribution\nMean = Median = Mode", fontsize=13, fontweight="bold")
ax.legend(fontsize=9)
ax.grid(alpha=0.3, linestyle="--")
ax.set_ylim(0, 0.45)
# 2. Right-skewed distribution (Log-normal): Mode < Median < Mean
ax = axes[1]
s = 0.8 # shape parameter
x_pos = np.linspace(0.01, 6, 1000)
pdf_lognorm = stats.lognorm.pdf(x_pos, s)
ax.plot(x_pos, pdf_lognorm, "b-", linewidth=2.5, label="Log-Normal Distribution")
ax.fill_between(x_pos, pdf_lognorm, alpha=0.3, color="blue")
# Calculate statistics
mean_val = np.exp(s**2 / 2)
median_val = 1 # median of lognormal with scale=1
mode_val = np.exp(-(s**2))
ax.axvline(mode_val, color="purple", linestyle=":", linewidth=3, label=f"Mode = {mode_val:.2f}")
ax.axvline(
median_val, color="green", linestyle="-.", linewidth=2, label=f"Median = {median_val:.2f}"
)
ax.axvline(mean_val, color="red", linestyle="--", linewidth=2, label=f"Mean = {mean_val:.2f}")
ax.set_xlabel("x", fontsize=12, fontweight="bold")
ax.set_ylabel("Density", fontsize=12, fontweight="bold")
ax.set_title("Right-Skewed Distribution\nMode < Median < Mean", fontsize=13, fontweight="bold")
ax.legend(fontsize=9)
ax.grid(alpha=0.3, linestyle="--")
ax.set_xlim(0, 6)
ax.set_ylim(0, 0.7)
# Add annotation
ax.annotate(
"",
xy=(mean_val, 0.05),
xytext=(mode_val, 0.05),
arrowprops={"arrowstyle": "<->", "color": "orange", "lw": 2},
)
ax.text(
(mode_val + mean_val) / 2,
0.08,
"Positive skew",
ha="center",
fontsize=9,
color="orange",
fontweight="bold",
)
# 3. Left-skewed distribution (Beta): Mean < Median < Mode
ax = axes[2]
a, b = 8, 2 # shape parameters for left skew
x_beta = np.linspace(0, 1, 1000)
pdf_beta = stats.beta.pdf(x_beta, a, b)
ax.plot(x_beta, pdf_beta, "b-", linewidth=2.5, label="Beta Distribution")
ax.fill_between(x_beta, pdf_beta, alpha=0.3, color="blue")
# Calculate statistics
mean_val = a / (a + b)
median_val = (a - 1 / 3) / (a + b - 2 / 3) # approximation
mode_val = (a - 1) / (a + b - 2)
ax.axvline(mean_val, color="red", linestyle="--", linewidth=2, label=f"Mean = {mean_val:.2f}")
ax.axvline(
median_val, color="green", linestyle="-.", linewidth=2, label=f"Median = {median_val:.2f}"
)
ax.axvline(mode_val, color="purple", linestyle=":", linewidth=3, label=f"Mode = {mode_val:.2f}")
ax.set_xlabel("x", fontsize=12, fontweight="bold")
ax.set_ylabel("Density", fontsize=12, fontweight="bold")
ax.set_title("Left-Skewed Distribution\nMean < Median < Mode", fontsize=13, fontweight="bold")
ax.legend(fontsize=9)
ax.grid(alpha=0.3, linestyle="--")
ax.set_xlim(0, 1)
ax.set_ylim(0, 3.5)
# Add annotation
ax.annotate(
"",
xy=(mode_val, 0.2),
xytext=(mean_val, 0.2),
arrowprops={"arrowstyle": "<->", "color": "orange", "lw": 2},
)
ax.text(
(mode_val + mean_val) / 2,
0.4,
"Negative skew",
ha="center",
fontsize=9,
color="orange",
fontweight="bold",
)
plt.suptitle(
"Comparison of Central Tendency Measures Across Different Distributions",
fontsize=15,
fontweight="bold",
y=1.02,
)
plt.tight_layout()
plt.show()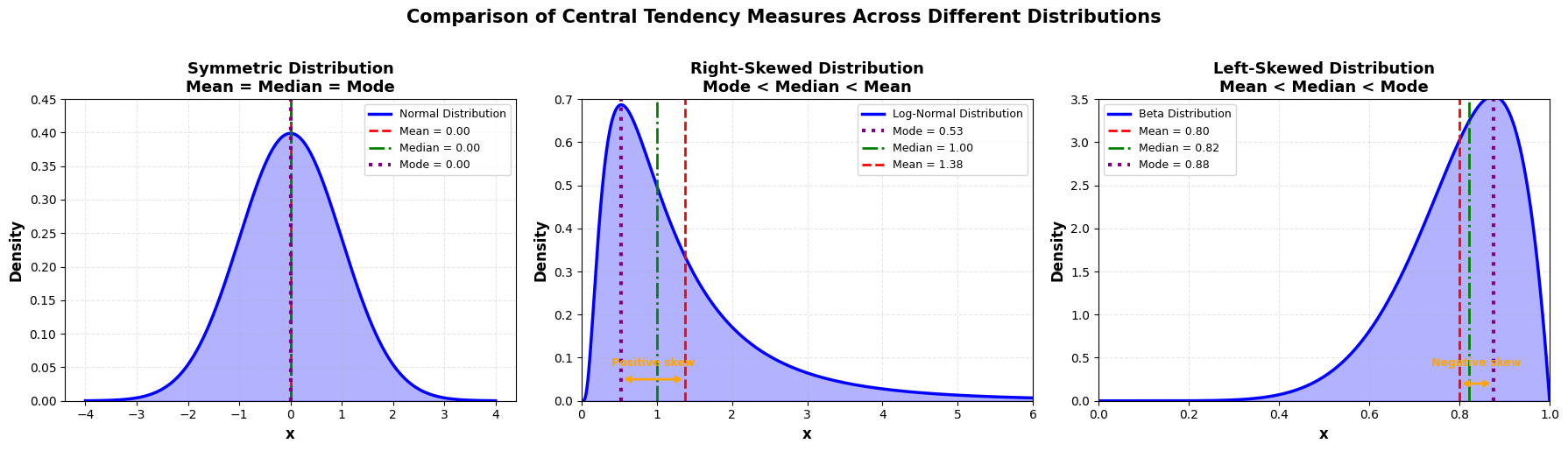
Spreidingsmaten¶
Spreidingsmaten geven aan hoe sterk de waarden variëren rond het “zwaartepunt” van de verdeling. Ze kunnen ook gebruikt worden om na te gaan hoe (a)typisch een sample is, gegeven een bepaalde referentieverdeling.
Variantie¶
De variantie of meet hoe ver waarden gemiddeld van de verwachte waarde afliggen in gekwadrateerde eenheden.
Populatievariantie¶
Voor de theoretische kansverdeling (de populatie) gebruiken we:
Voor discrete kansvariabelen:
Voor continue kansvariabelen:
Steekproefvariantie¶
In de praktijk kennen we de theoretische verdeling meestal niet en werken we met steekproeven. De steekproefvariantie schat de populatievariantie op basis van observaties :
waarbij het steekproefgemiddelde is.
Variantie van lineaire transformaties:
Wanneer we een constante optellen aan elke waarde, verschuiven we de hele verdeling, maar de afstanden tussen waarden blijven gelijk. De spreiding (variantie) verandert dus niet; constante heeft geen effect. Wanneer we elke waarde vermenigvuldigen met , worden alle afwijkingen tot het gemiddelde ook met vermenigvuldigd. Omdat variantie gedefinieerd is als het gemiddelde van de gekwadrateerde afwijkingen, wordt de factor gekwadrateerd: .
Standaardafwijking¶
De standaardafwijking (of standaarddeviatie) is de wortel van de populatie-/of steekproefvariantie: $$
$$
Dit geeft de spreiding in dezelfde eenheden als de originele variabele (niet gekwadrateerd), wat interpretatie makkelijker maakt.
Voor de dobbelsteen:
Merk op dat we deze maat reeds eerder zagen in de context van standaardisatie van variabelen.
Interkwartielafstand¶
Percentielen (of kwantielen) verdelen de kansverdeling in gelijke delen. Het -de percentiel is de waarde waarvoor geldt:
Belangrijke percentielen:
(eerste kwartiel, ): 25% van de waarden ligt hieronder
(tweede kwartiel, of mediaan): 50% van de waarden ligt hieronder
(derde kwartiel, ): 75% van de waarden ligt hieronder
Interkwartielafstand (Interquartile Range, IQR):
In de context van empirische kansverdelingen, is de IQR een robuuste maat voor spreiding die minder gevoelig is voor toevallige uitschieters (outliers) dan de standaardafwijking:
De IQR bevat de middelste 50% van de verdeling en wordt vaak gebruikt om outliers te detecteren tijdens exploratieve data analyse:
Waarden onder of boven worden als mogelijke uitschieters beschouwd.
Source
# Visualization of standard deviation and interquartile range
fig, axes = plt.subplots(2, 3, figsize=(18, 10))
# Row 1: Standard Deviation
# Column 1: Symmetric distribution (Normal)
ax = axes[0, 0]
mu, sigma = 0, 1
x = np.linspace(-4, 4, 1000)
pdf = stats.norm.pdf(x, mu, sigma)
ax.plot(x, pdf, "b-", linewidth=2.5, label="Normal Distribution")
ax.fill_between(x, pdf, alpha=0.3, color="blue")
# Visualize standard deviation
ax.axvline(mu, color="red", linestyle="--", linewidth=2, label=f"μ = {mu:.2f}")
ax.axvline(
mu - sigma, color="orange", linestyle=":", linewidth=2, label=f"μ - σ = {mu - sigma:.2f}"
)
ax.axvline(
mu + sigma, color="orange", linestyle=":", linewidth=2, label=f"μ + σ = {mu + sigma:.2f}"
)
# Shade area within 1 standard deviation
mask_1std = (x >= mu - sigma) & (x <= mu + sigma)
ax.fill_between(x[mask_1std], pdf[mask_1std], alpha=0.5, color="orange", label="μ ± σ (~68%)")
ax.set_xlabel("x", fontsize=12, fontweight="bold")
ax.set_ylabel("Density", fontsize=12, fontweight="bold")
ax.set_title("Symmetric Distribution\nStandard Deviation", fontsize=13, fontweight="bold")
ax.legend(fontsize=9, loc="upper right")
ax.grid(alpha=0.3, linestyle="--")
ax.set_ylim(0, 0.45)
# Column 2: Right-skewed distribution (Log-normal)
ax = axes[0, 1]
s = 0.8
x_pos = np.linspace(0.01, 6, 1000)
pdf_lognorm = stats.lognorm.pdf(x_pos, s)
ax.plot(x_pos, pdf_lognorm, "b-", linewidth=2.5, label="Log-Normal Distribution")
ax.fill_between(x_pos, pdf_lognorm, alpha=0.3, color="blue")
# Statistics
mean_val = np.exp(s**2 / 2)
std_val = mean_val * np.sqrt(np.exp(s**2) - 1)
ax.axvline(mean_val, color="red", linestyle="--", linewidth=2, label=f"μ = {mean_val:.2f}")
ax.axvline(
mean_val - std_val,
color="orange",
linestyle=":",
linewidth=2,
label=f"μ - σ = {mean_val - std_val:.2f}",
)
ax.axvline(
mean_val + std_val,
color="orange",
linestyle=":",
linewidth=2,
label=f"μ + σ = {mean_val + std_val:.2f}",
)
# Shade area within 1 standard deviation
mask_1std = (x_pos >= mean_val - std_val) & (x_pos <= mean_val + std_val)
ax.fill_between(x_pos[mask_1std], pdf_lognorm[mask_1std], alpha=0.5, color="orange", label="μ ± σ")
ax.set_xlabel("x", fontsize=12, fontweight="bold")
ax.set_ylabel("Density", fontsize=12, fontweight="bold")
ax.set_title("Right-Skewed Distribution\nStandard Deviation", fontsize=13, fontweight="bold")
ax.legend(fontsize=9, loc="upper right")
ax.grid(alpha=0.3, linestyle="--")
ax.set_xlim(0, 6)
ax.set_ylim(0, 0.7)
# Column 3: Left-skewed distribution (Beta)
ax = axes[0, 2]
a, b = 8, 2
x_beta = np.linspace(0, 1, 1000)
pdf_beta = stats.beta.pdf(x_beta, a, b)
ax.plot(x_beta, pdf_beta, "b-", linewidth=2.5, label="Beta Distribution")
ax.fill_between(x_beta, pdf_beta, alpha=0.3, color="blue")
# Statistics
mean_val = a / (a + b)
std_val = np.sqrt(a * b / ((a + b) ** 2 * (a + b + 1)))
ax.axvline(mean_val, color="red", linestyle="--", linewidth=2, label=f"μ = {mean_val:.2f}")
ax.axvline(
mean_val - std_val,
color="orange",
linestyle=":",
linewidth=2,
label=f"μ - σ = {mean_val - std_val:.2f}",
)
ax.axvline(
mean_val + std_val,
color="orange",
linestyle=":",
linewidth=2,
label=f"μ + σ = {mean_val + std_val:.2f}",
)
# Shade area within 1 standard deviation
mask_1std = (x_beta >= mean_val - std_val) & (x_beta <= mean_val + std_val)
ax.fill_between(x_beta[mask_1std], pdf_beta[mask_1std], alpha=0.5, color="orange", label="μ ± σ")
ax.set_xlabel("x", fontsize=12, fontweight="bold")
ax.set_ylabel("Density", fontsize=12, fontweight="bold")
ax.set_title("Left-Skewed Distribution\nStandard Deviation", fontsize=13, fontweight="bold")
ax.legend(fontsize=9, loc="upper right")
ax.grid(alpha=0.3, linestyle="--")
ax.set_xlim(0, 1)
ax.set_ylim(0, 3.5)
# Row 2: Interquartile Range (IQR)
# Column 1: Symmetric distribution (Normal)
ax = axes[1, 0]
ax.plot(x, pdf, "b-", linewidth=2.5, label="Normal Distribution")
ax.fill_between(x, pdf, alpha=0.3, color="blue")
# Quartile calculations
q1 = stats.norm.ppf(0.25, mu, sigma)
q2 = stats.norm.ppf(0.50, mu, sigma) # median
q3 = stats.norm.ppf(0.75, mu, sigma)
iqr = q3 - q1
ax.axvline(q1, color="green", linestyle=":", linewidth=2, label=f"Q1 (P25) = {q1:.2f}")
ax.axvline(q2, color="red", linestyle="--", linewidth=2, label=f"Q2 (Median) = {q2:.2f}")
ax.axvline(q3, color="green", linestyle=":", linewidth=2, label=f"Q3 (P75) = {q3:.2f}")
# Shade IQR region (middle 50%)
mask_iqr = (x >= q1) & (x <= q3)
ax.fill_between(
x[mask_iqr], pdf[mask_iqr], alpha=0.5, color="green", label=f"IQR = {iqr:.2f} (50%)"
)
ax.set_xlabel("x", fontsize=12, fontweight="bold")
ax.set_ylabel("Density", fontsize=12, fontweight="bold")
ax.set_title("Symmetric Distribution\nInterquartile Range (IQR)", fontsize=13, fontweight="bold")
ax.legend(fontsize=9, loc="upper right")
ax.grid(alpha=0.3, linestyle="--")
ax.set_ylim(0, 0.45)
# Column 2: Right-skewed distribution (Log-normal)
ax = axes[1, 1]
ax.plot(x_pos, pdf_lognorm, "b-", linewidth=2.5, label="Log-Normal Distribution")
ax.fill_between(x_pos, pdf_lognorm, alpha=0.3, color="blue")
# Quartile calculations
q1 = stats.lognorm.ppf(0.25, s)
q2 = stats.lognorm.ppf(0.50, s)
q3 = stats.lognorm.ppf(0.75, s)
iqr = q3 - q1
ax.axvline(q1, color="green", linestyle=":", linewidth=2, label=f"Q1 (P25) = {q1:.2f}")
ax.axvline(q2, color="red", linestyle="--", linewidth=2, label=f"Q2 (Median) = {q2:.2f}")
ax.axvline(q3, color="green", linestyle=":", linewidth=2, label=f"Q3 (P75) = {q3:.2f}")
# Shade IQR region
mask_iqr = (x_pos >= q1) & (x_pos <= q3)
ax.fill_between(
x_pos[mask_iqr], pdf_lognorm[mask_iqr], alpha=0.5, color="green", label=f"IQR = {iqr:.2f} (50%)"
)
ax.set_xlabel("x", fontsize=12, fontweight="bold")
ax.set_ylabel("Density", fontsize=12, fontweight="bold")
ax.set_title("Right-Skewed Distribution\nInterquartile Range (IQR)", fontsize=13, fontweight="bold")
ax.legend(fontsize=9, loc="upper right")
ax.grid(alpha=0.3, linestyle="--")
ax.set_xlim(0, 6)
ax.set_ylim(0, 0.7)
# Column 3: Left-skewed distribution (Beta)
ax = axes[1, 2]
ax.plot(x_beta, pdf_beta, "b-", linewidth=2.5, label="Beta Distribution")
ax.fill_between(x_beta, pdf_beta, alpha=0.3, color="blue")
# Quartile calculations
q1 = stats.beta.ppf(0.25, a, b)
q2 = stats.beta.ppf(0.50, a, b)
q3 = stats.beta.ppf(0.75, a, b)
iqr = q3 - q1
ax.axvline(q1, color="green", linestyle=":", linewidth=2, label=f"Q1 (P25) = {q1:.2f}")
ax.axvline(q2, color="red", linestyle="--", linewidth=2, label=f"Q2 (Median) = {q2:.2f}")
ax.axvline(q3, color="green", linestyle=":", linewidth=2, label=f"Q3 (P75) = {q3:.2f}")
# Shade IQR region
mask_iqr = (x_beta >= q1) & (x_beta <= q3)
ax.fill_between(
x_beta[mask_iqr], pdf_beta[mask_iqr], alpha=0.5, color="green", label=f"IQR = {iqr:.2f} (50%)"
)
ax.set_xlabel("x", fontsize=12, fontweight="bold")
ax.set_ylabel("Density", fontsize=12, fontweight="bold")
ax.set_title("Left-Skewed Distribution\nInterquartile Range (IQR)", fontsize=13, fontweight="bold")
ax.legend(fontsize=9, loc="upper right")
ax.grid(alpha=0.3, linestyle="--")
ax.set_xlim(0, 1)
ax.set_ylim(0, 3.5)
plt.suptitle(
"Comparison of Dispersion Measures: Standard Deviation and Interquartile Range",
fontsize=15,
fontweight="bold",
y=0.995,
)
plt.tight_layout()
plt.show()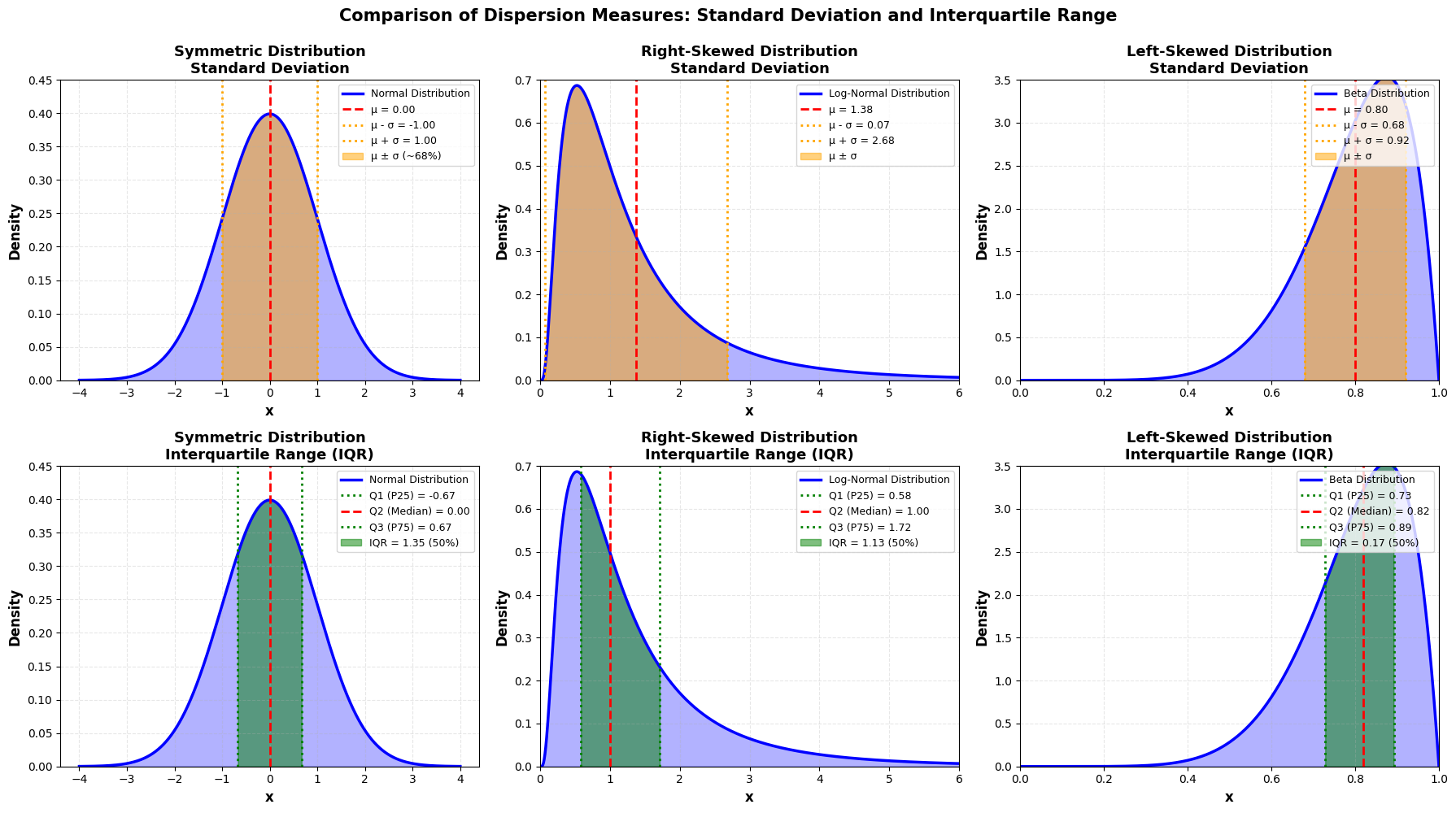
Deze sectie is onder andere gebaseerd op hoofdstuk 3 uit Heaton (2017) en Hoofdstuk 1 uit SPIE-Intl Soc Optical Eng (2007)
Het probleem gaat over een probabilistische puzzel en werd louter omwille van het thema naar de presentator van de Amerikaanse tv-show Let’s Make a Deal vernoemd. De oorspronkelijke formulering luidt: Suppose you’re on a game show, and you’re given the choice of three doors: Behind one door is a car; behind the others, goats. You pick a door, say No. 1, and the host, who knows what’s behind the doors, opens another door, say No. 3, which has a goat. He then says to you, “Do you want to pick door No. 2?” Is it to your advantage to switch your choice
De term Bayesiaans is afgeleid van de 18e-eeuwse Engelse wiskundige en theoloog Thomas Bayes, die de eerste wiskundige behandeling gaf van een niet-triviaal probleem van statistische data-analyse met behulp van wat nu bekend staat als Bayesiaanse inferentie. Wiskundige Pierre-Simon Laplace was pionier van en populariseerde wat nu Bayesiaanse kansrekening wordt genoemd.
Een aftelbaar oneindig aantal waarden verwijst naar een verzameling met oneindig veel elementen, die echter op een systematische manier genummerd of geteld kunnen worden. Een bekend voorbeeld hiervan is de verzameling van de natuurlijke getallen of de gehele getallen . Het belangrijkste kenmerk is dat er een één-op-één correspondentie bestaat tussen deze verzameling en de verzameling van natuurlijke getallen.
- Jaynes, E. T. (2003). Probability Theory: The Logic of Science (G. L. Bretthorst, Ed.). Cambridge University Press. 10.1017/cbo9780511790423
- Cox, R. T. (1946). Probability, Frequency and Reasonable Expectation. American Journal of Physics, 14(1), 1–13. 10.1119/1.1990764
- Heaton, J. (2017). Ian Goodfellow, Yoshua Bengio, and Aaron Courville: Deep learning: The MIT Press, 2016, 800 pp, ISBN: 0262035618. Genetic Programming and Evolvable Machines, 19(1–2), 305–307. 10.1007/s10710-017-9314-z
- Pattern Recognition and Machine Learning. (2007). Journal of Electronic Imaging, 16(4), 049901. 10.1117/1.2819119