Natural Language Processing¶
Natural language processing (NLP) is, naast computer vision, een domein binnen machine learning waar neurale netwerken voor grote doorbraken hebben gezorgd. NLP richt zich op het automatisch begrijpen, interpreteren en genereren van menselijke taal. Het is een domein met vele vertakkingen en een lange geschiedenis in machine learning. Sinds de introductie van de zogenaamde Transformer architectuur (Vaswani et al. (2017)) is deze familie van neurale netwerken de dominante modelbenadering geworden in dit domein[1]. Deze architectuur gaf aanleiding tot de huidige golf van Large Language Foundation modellen.
Net zoals bij beelddata hebben we hier te maken met ongestructureerde data (Tekstdocumenten: Word-bestanden, PDF’s, enz.).
Alles draait om de automatische extractie van semantische patronen en taalkundige structuren. Vroege NLP toepassingen waren vaak gebaseerd op combinaties van rule based en statistische verwerking. Tot aan de doorbraak van Transformer modellen, deden neurale netwerken eerst hun intrede bij NLP via recurrent neural networks (RNN), gevolgd door long short-term memory (LSTM) en gated recurrent unit (GRU) neurale netwerken.
Rule-based systemen
Een voorbeeld van een klassieke rule-based benadering is Part-of-Speech (POS) tagging.

Part-of-Speech tagging is een klassieke NLP taak waarbij elk woord in een zin een grammaticale categorie krijgt toegewezen (zelfstandig naamwoord, werkwoord, bijvoeglijk naamwoord, etc.).
Vroege systemen gebruikten regels voor het Engels zoals:
Woorden die eindigen op “-ing” zijn waarschijnlijk werkwoorden
Woorden die volgen op “the” zijn waarschijnlijk zelfstandige naamwoorden
Woorden in hoofdletters aan het begin van een zin zijn waarschijnlijk eigennamen
Woorden die eindigen op “-ly” zijn waarschijnlijk bijwoorden
enz.
Transformers¶
Moderne NLP gebeurt bijna uitsluitend op basis van Transformers. Het is een specifieke neurale netwerkarchitectuur die in 2017 werd geïntroduceerd. Hun succes vloeit voort uit het feit dat ze woorden in hun context begrijpen via het zogenaamde self-attention mechanisme. Dit is een heel krachtig mechanisme om met de complexe afhankelijkheidsstructuren bij taalverwerking om te gaan.
De oorspronkelijke modelarchitectuur ziet er als volgt uit (figuur uit Vaswani et al. (2017)):
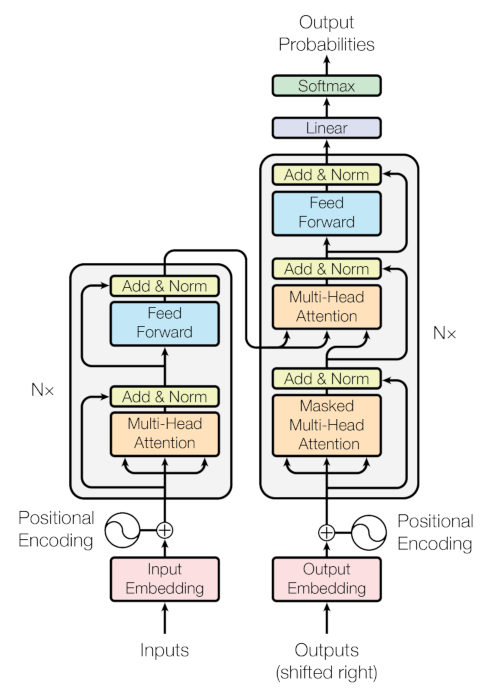
Self-attention¶
Door dit mechanisme kan een model bij het verwerken van een bepaald woord naar alle andere woorden in de sequentie “kijken” en “beslissen” welke het belangrijkst zijn voor het begrip van dat specifieke woord. Voor mensen is dit evident, maar het is verre van evident gebleken om dit in machine learning na te bootsen[2].
Neem bijvoorbeeld de zin:
The airplane was parked in the hangar because it had a technical problem.
Als mens begrijpen we onmiddellijk dat it hier verwijst naar airplane en niet naar hangar, maar hoe lost self-attention dit op?
Om dit te begrijpen, kunnen we denken aan een bibliotheek waarin we ( het model) op zoek gaan naar informatie over een bepaald onderwerp ( woord[3]). Die informatie staat verspreid over verschillende boeken ( andere woorden[3] in de sequentie). Self-attention voert een dergelijke zoektocht uit op basis van drie belangrijke componenten die moeten worden geleerd tijdens de modeltraining.
Query (Q): De zoekvraag; dit is bijvoorbeeld (een abstracte vorm van): “Ik ben een voornaamwoord... naar wie verwijs ik?”
Key (K): De eigenschappen die een woord[3] adverteert; bijvoorbeeld: “Ik ben een zelfstandig naamwoord, een mogelijk onderwerp...”. Dit kunnen we vergelijken met de labels op de rug van de boeken in de bibliotheek.
Value (V): De betekenis van het woord[3] in deze context. Denk aan de daadwerkelijke inhoud van een boek.
De verwerking gaat dan als volgt:
Voor ieder woord[3] worden de Q, K en V vectoren berekend
Ieder woord[3] vergelijkt zijn Query met de Keys van de andere woorden[3] wat resulteert in een genormaliseerde score. Bijvoorbeeld:
Q(it)•K(The)= 0.0 (niet relevant)Q(it)•K(airplane)= 0.88 (zeer relevant)...
Q(it)•K(problem)= 0.65 (relevant)
Aan de hand van die score worden voor ieder woord[3], de Value vectoren (dus de eigenlijke betekenis) van andere woorden[3] telkens anders gewogen (geïntegreerd) in de self-attention output.
In de architectuur zitten niet één, maar verschillende (multi) self-attention heads. Deze worden elk onafhankelijk van elkaar getraind en toegepast. Zo kan bij eenzelfde woord[3] tegelijk rekening gehouden worden met verschillende taalkundige eigenschappen (zie onderstaande figuur uit Vaswani et al. (2017)).

De output van de verschillende heads wordt samengevoegd in de output naar volgende lagen. Door hun diepe structuur (zie N x bij de blokken in de figuur) kunnen transformers ook veel grotere verbanden leren leggen, dus niet enkel op het niveau van individuele zinnen, maar ook uiteenzettingen, conversaties, enz.
Encoder-Decoder¶
De oorspronkelijke Transformer architectuur (Vaswani et al. (2017)) bestaat uit twee hoofdstructuren die samenwerken bij sequence-to-sequence taken zoals machine translation:
Encoder¶
(links in de figuur)
Verwerkt de volledige input sequentie (bv. een zin in het Frans)
Bestaat uit verschillende identieke lagen (6 in de originele architectuur)
Elke laag bevat multi-head self-attention waarbij tokens naar alle andere tokens in de sequentie kunnen “kijken”
Output: Een dense contextuele representatie van de input[4]
Decoder¶
(rechts in de figuur)
🤗 Autoregressie

Genereert de output sequentie token voor token (bv. de vertaling in het Engels)
Bij elk nieuw gegenereerd token wordt dit terug als input in de decoder aangeboden (dit heet algemeen autoregressie)
Bestaat ook uit verschillende identieke lagen (6 in de originele architectuur)
Voor de decoder input wordt met masked multi-head self-attention gewerkt: in tegenstelling tot de encoder, gebeurt de verwerking van tokens enkel door te kijken naar voorgaande tokens in de sequentie
Er bestaan verschillende strategieën om de outputwaarden uiteindelijk te decoderen naar woorden.
🤗 Decoding
Parameters¶
De parameters van transformer modellen zijn enorm talrijk en complex. De belangrijkste zijn:
Token embeddings: Ieder token (ID) is gelinkt aan een dense vector in een embedding matrix. Die matrix wordt getraind.
Positional embeddings: Een van de voordelen van Transformers is dat de verwerking van tokens in parallel kan gebeuren. In tegenstelling tot architecturen die berusten op recurrente verbindingen of convoluties, moet daarom expliciete informatie over de relatieve positie van een token in de sequentie meegegeven worden. Dit gebeurt in recente modellen ook vaak via getrainde parameters[5].
Voor elke attention head in elke layer:
Query (Q) matrix: Transformeert de input naar de query vector
Key (K) matrix: Transformeert de input naar de key vector
Value (V) matrix: Transformeert de input naar de value vector
Output projection: Combineert de outputs van de multiple heads
Features¶
We weten intussen dat om machine learning toe te passen alle data naar numerieke waarden omgezet moet worden. Zoals voor alle NLP ML toepassingen, neemt dit bij Transformers de speciale vorm van tokenization aan.
Tokenization is de eerste en cruciale stap bij alle NLP ML toepassingen waarbij ruwe tekst wordt opgedeeld in kleinere eenheden genaamd tokens - ongeacht het model type. Deze tokens vormen de elementaire deeltjes die door machine learning modellen verwerkt worden.
Er bestaan weliswaar verschillende tokenization strategieën, elk met hun eigen voor- en nadelen:
Word-level¶
Dit is de eenvoudigste benadering waarbij tekst wordt opgesplitst op basis van spaties en interpunctie. Elk uniek woord krijgt een eigen ID.
All models are wrong
| All | models | are | wrong |
[2460, 4211, 527, 5076]Voordelen:
Intuïtief en gemakkelijk te begrijpen
Behoudt woordgrenzen
Nadelen:
Groot vocabularium (honderdduizenden tokens)
Geen representatie voor out-of-vocabulary woorden
Morfologische varianten worden als volledig verschillende tokens behandeld
Character-level¶
Hier wordt ieder individueel karakter een token.
All models are wrong
| A | l | l | _ | m | o | d | e | l | s | _ | a | r | e | _ | w | r | o | n | g |
[65, 108, 108, 32, 109, 111, 100, 101, 108, 115, 32, 97, 114, 101, 32, 119, 114, 111, 110, 103]Voordelen:
Klein vocabularium
Geen out-of-vocabulary problemen
Kan morfologische patronen leren
Nadelen:
Langere sequenties
Moeilijker om semantische (en andere meer abstracte) informatie te leren
Sub-word¶
Hierbij splitst men woorden op in kleinere, betekenisvolle eenheden. Voorbeelden zijn Byte-Pair Encoding (BPE) en WordPiece.
All unmeaningfulish models are wrong
| All | un | mean | ing | ful | ish | models | are | wrong
[1398, 8362, 3263, 7192, 2118, 2365, 2944, 1132, 2488]Voordelen:
Balans tussen vocabularium grootte en lengte van sequenties
Kan omgaan met out-of-vocabulary woorden
Deelt informatie tussen morfologisch gerelateerde woorden
Meest gebruikt in moderne transformers (BERT, GPT, T5, enz.)
Nadelen:
Minder intuïtief
Vereist voorafgaande training
🤗 Tokenizer playground
Leeralgoritme¶
Transformers worden zoals andere neurale netwerken getraind met varianten van stochastic gradient descent en gebruiken backpropagation om gradiënten te berekenen door het hele netwerk. Loss functies nemen verschillende vormen aan per taak.
Taken¶
Transformers worden voor een breed scala aan NLP taken ingezet.
Klassificatie¶
Zowel op het niveau van teksten als van individuele tokens, bestaan verschillende varianten, bijvoorbeeld:
Sentiment analyse: Bepalen of een tekst positief, negatief of neutraal is
Topic classificatie: Indelen in thematische categorieën
Spam detectie: Onderscheiden van ongewenste berichten
Named Entity Recognition (NER): bv. Is dit een eigennaam?
🌍
Voorbeelden:
Automatische vertaling¶
Het model vertaalt tekst van de ene taal naar de andere. Dit gebeurt aan de hand van een encoder-decoder architectuur.
Vragen beantwoorden¶
Binnen deze taak is het chatten vandaag de meest gekende toepassing. Er vallen specifieke taken onder zoals het opvolgen van instructies, genereren van redeneringen. Hiervoor worden verschillende (complexe) subtaken opgezet tijdens het trainen.
Representation learning¶
Encoder-only modellen genereren embeddings die nuttig zijn voor diverse downstream taken, zoals similarity search en few-/zero-shot klassificatie
Ervaring¶
Moderne transformer architecturen (LLMs) worden doorgaans in twee fases getraind:
pre-training
fine-tuning
Pre-training¶
Tijdens pre-training gebeurt training via self-supervised learning. Hierbij bestaan er verschillende varianten. De meest eenvoudige zijn:
Causal language modeling: Het model voorspelt het volgende token in een sequentie van tokens en krijgt daarop rechtstreeks feedback.
The capital of France is _ | target: ParisMasked language modeling: Het model moet leren om gedeeltelijk gemaskeerde inputs te reconstrueren.
The _ of France is _ | targets: capital, ParisHet is de bedoeling dat het model een generiek begrip opbouwt van één of meerdere taal/talen. Dit vraagt enorme volumes aan data en rekenkracht.
Fine-tuning¶
Tijdens de fine-tuning fase worden modellen georiënteerd naar specifieke taken en objectieven. Hier wordt dan gebruik gemaakt van supervised training regimes.
In de context van moderne chatbots en assistenten worden speciale fine-tuning technieken ingezet, waaronder:
Instruction following: het model wordt supervised getraind op diverse taken die geformuleerd zijn als instructies:
"Vertaal naar Engels: Hallo wereld"
"Vat samen: [lange tekst]"
"Beantwoord de vraag: Wat is ML?"Reinforcement Learning from Human Feedback (RLHF): Tijdens de pre-training fase hebben LLMs geleerd om taal te produceren die quasi niet te onderscheiden is van natuurlijke taal. Ze zijn daarom niet per se goed in het geven van nuttige/correcte/veilige antwoorden. RLHF werd geïntroduceerd door OpenAI en Google DeepMind (Christiano et al. (2017)) in de aanloop naar ChatGPT. Ze lieten op grote schaal een pre-trained model verschillende antwoorden genereren voor bepaalde vragen en vroegen echte mensen die antwoorden te scoren op hun wenselijkheid.
Question: "How do I make pasta?"
Response A: "Boil water, add salt, cook pasta for 8-10 minutes, drain and serve."
Response B: "Pasta pasta pasta delicious yummy food."
...
Score Response A > Score Response BMet die informatie werd een apart (reward) model getraind om voor iedere output van het eigenlijke model de “menselijke wenselijkheid” te voorspellen. Daarna werd dit reward model gebruikt om het taalmodel te fine-tunen via reinforcement learning richting meer nuttige/correcte/veilige output.
🌍 GPT-2
Deze GPT versie heeft nog geen fine-tuning via RLHF. We illustreren hieronder de output met verschillende decoding strategieën.
Input: What’s the weather going to be like in Antwerp tomorrow?
Decoding strategieën:
Greedy: Neemt telkens het token met de hoogste waarschijnlijkheid
Beam: Houdt meerdere hypotheses bij en kiest daaruit de beste
Sampling met temperatuur: Introduceert randomness voor meer diverse output
Top-K=50 sampling: Selecteert random alleen uit top-50 meest waarschijnlijke tokens
Top-P=0.9 sampling: Selecteert random uit kleinste set tokens waarvan som >= 0.9
N-gram penalty: Voorkomt dat twee opeenvolgende tokens zich herhalen
Observaties:
GPT-2 geeft geen directe antwoorden op vragen
Output lijkt vaak op trainingsdata (Wikipedia, nieuws, etc.)
Geen begrip van conversatie context
Dit is waarom men instructie fine-tuning en RLHF heeft geïntroduceerd.
Source
import torch
import torch.nn.functional as F
from transformers import AutoModelForCausalLM, AutoTokenizer
from IPython.display import clear_output
prompt = "What's the weather going to be like in Antwerp tomorrow?"
model_name = "gpt2"
max_length = 50
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
model.eval()
# Tokenize the input
inputs = tokenizer(prompt, return_tensors="pt")
# 1. GREEDY DECODING
print("\n1. GREEDY DECODING: Always choose the token with the highest probability")
with torch.no_grad():
greedy_output = model.generate(
**inputs, max_length=max_length, do_sample=False, pad_token_id=tokenizer.eos_token_id
)
greedy_text = tokenizer.decode(greedy_output[0], skip_special_tokens=True)
print(f" {greedy_text}")
# 2. BEAM SEARCH
print(
"\n\n2. BEAM SEARCH (num_beams=5): Keeps track of multiple hypotheses and chooses the best one"
)
with torch.no_grad():
beam_output = model.generate(
**inputs,
max_length=max_length,
num_beams=5,
do_sample=False,
pad_token_id=tokenizer.eos_token_id,
)
beam_text = tokenizer.decode(beam_output[0], skip_special_tokens=True)
print(f" {beam_text}")
# 3. SAMPLING met Temperature
print("\n\n3. SAMPLING (temperature=0.7): Introduces randomness for more diverse output")
torch.manual_seed(42)
with torch.no_grad():
sample_output = model.generate(
**inputs,
max_length=max_length,
do_sample=True,
temperature=0.7,
pad_token_id=tokenizer.eos_token_id,
)
sample_text = tokenizer.decode(sample_output[0], skip_special_tokens=True)
print(f" {sample_text}")
# 4. TOP-K SAMPLING
print("\n\n4. TOP-K SAMPLING (k=50): Sample only from top-50 most likely tokens")
torch.manual_seed(123)
with torch.no_grad():
topk_output = model.generate(
**inputs,
max_length=max_length,
do_sample=True,
top_k=50,
pad_token_id=tokenizer.eos_token_id,
)
topk_text = tokenizer.decode(topk_output[0], skip_special_tokens=True)
print(f" {topk_text}")
# 5. TOP-P (NUCLEUS) SAMPLING
print(
"\n\n5. TOP-P SAMPLING (p=0.9): Sample from the smallest set of tokens whose cumulative probability >= 90%"
)
torch.manual_seed(456)
with torch.no_grad():
topp_output = model.generate(
**inputs,
max_length=max_length,
do_sample=True,
top_p=0.9,
pad_token_id=tokenizer.eos_token_id,
)
topp_text = tokenizer.decode(topp_output[0], skip_special_tokens=True)
print(f" {topp_text}")
# 6. N-GRAM PENALTY
print("\n\n6. BEAM SEARCH + NO_REPEAT_NGRAM (size=2): Prevents repetition of 2-grams")
with torch.no_grad():
ngram_output = model.generate(
**inputs,
max_length=max_length,
num_beams=5,
no_repeat_ngram_size=2,
do_sample=False,
pad_token_id=tokenizer.eos_token_id,
)
ngram_text = tokenizer.decode(ngram_output[0], skip_special_tokens=True)
print(f" {ngram_text}")Output
1. GREEDY DECODING: Always choose the token with the highest probability
What's the weather going to be like in Antwerp tomorrow?
The weather is going to be very good. The weather is going to be very good. The weather is going to be very good. The weather is going to be very
2. BEAM SEARCH (num_beams=5): Keeps track of multiple hypotheses and chooses the best one
What's the weather going to be like in Antwerp tomorrow?
The weather is going to be like in Antwerp tomorrow.
The weather is going to be like in Antwerp tomorrow.
The weather is going
3. SAMPLING (temperature=0.7): Introduces randomness for more diverse output
What's the weather going to be like in Antwerp tomorrow? We'll have a chance to see how the wind gets to us tomorrow."
It was a sunny day for the French capital, with temperatures dipping above freezing, and the air
4. TOP-K SAMPLING (k=50): Sample only from top-50 most likely tokens
What's the weather going to be like in Antwerp tomorrow? Why did you get it here?"
Fry is a Belgian-born musician who has appeared on The X Factor and The Real Housewives of Beverly Hills. He has written
5. TOP-P SAMPLING (p=0.9): Sample from the smallest set of tokens whose cumulative probability >= 90%
What's the weather going to be like in Antwerp tomorrow? (photo: @KathrynWG)
A couple of days ago, the state legislature voted to change how the government is governed. The new rules would have put
6. BEAM SEARCH + NO_REPEAT_NGRAM (size=2): Prevents repetition of 2-grams
What's the weather going to be like in Antwerp tomorrow?
The weather will be a bit different tomorrow than it was yesterday. We'll have to wait and see how it goes tomorrow, but we'll be able to get a good
Evaluatie¶
Naast klassieke metrieken (bv. voor klassificatie), bestaan er algemeen in de context van NLP veel specifieke varianten zoals:
Voor veel NLP taken is automatische evaluatie echter ontoereikend en wordt er geïnvesteerd in menselijke scoring:
Fluency: Is de gegenereerde tekst vloeiend en grammaticaal correct?
Coherence: Is de tekst logisch en samenhangend?
Relevance: Is de output relevant voor de input?
Factuality: Zijn de feiten correct?
Safety: Is de output veilig en ethisch verantwoord?
Voordelen¶
State-of-the-art performantie: Transformers behalen de beste resultaten op vrijwel alle NLP benchmarks
Transfer learning: Pre-trained modellen zijn herbruikbaar voor vele taken
Parallellisatie: Snelle training op moderne hardware (GPUs/TPUs)
Lange-termijn afhankelijkheden: Kunnen context over lange afstanden modelleren zonder de beperkingen van sequentiële verwerking
Multi-task learning: Eén model kan meerdere taken aan
Multi-lingual: Moderne modellen werken vaak over talen heen
Nadelen¶
Training: Zeer intensief (duurtijd in de orde van maanden)
Inference: Groot geheugen en (GPU) rekenkracht nodig voor grote modellen; trage responsen
Energie & water verbruik: Aanzienlijke milieu-impact van training en deployment
Interpreteerbaarheid: Complexe, ontransparante architectuur
Toxiciteit: Kunnen ongepaste of schadelijke inhoud genereren - moeilijk om 100% te controleren
Hallucinaties: Kunnen overtuigend feitelijk incorrecte output genereren
Over fitting: Kunnen trainingsdata memoriseren en lekken. Door onrechtmatige scraping kunnen daardoor copyright inbreuken tot stand komen.
Training window: Om modellen als kennisbronnen te gebruiken moeten we rekening houden met de training data cutoff datum
Context window: Een context window is het maximale aantal tokens dat het model tegelijk kan “zien”. Dit kan 4.000 tokens zijn, 8.000, of zelfs meer dan een miljoen in de nieuwste modellen. Informatie buiten dit venster kan niet in rekening worden gebracht en moet, indien nodig, worden aangereikt via een database van embeddings[6].
en andere domeinen zoals beeldherkenning -en generatie.
Eerdere benaderingen zoals RNN, LSTM en GRU neurale netwerken schoten hier telkens in te kort.
Het gaat hier over tensor-representaties. Die noemen we dense om aan te duiden dat alle of de meerderheid van de elementen niet 0 zijn.
In Vaswani et al. (2017) was dit niet het geval en werd een vaste sinusoïde-encodering gebruikt.
zoals in zogenaamde Retrieval Augmented Generation (RAG)
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., & Polosukhin, I. (2017). Attention Is All You Need. arXiv. 10.48550/ARXIV.1706.03762
- Christiano, P., Leike, J., Brown, T. B., Martic, M., Legg, S., & Amodei, D. (2017). Deep reinforcement learning from human preferences. arXiv. 10.48550/ARXIV.1706.03741