ML modellen voor beeldgeneratie zijn de laatste jaren razend populair geworden. Ze vormen samen met LLMs de motor van de generatieve AI revolutie. Het doel is om nieuwe, realistische beelden te creëren op basis van een beschrijving, een ander beeld, of zelfs volledig zonder prompting. In tegenstelling tot beeldherkenning waar we aangeleerde patronen in beelden willen herkennen, gaat het hier om het synthetiseren van nieuwe beelden op basis van de geleerde patronen.
Net zoals bij computer vision en natural language processing, zijn er doorheen de jaren verschillende benaderingen geweest voor beeldgeneratie. Zoals Transformers bij NLP, hebben diffusion models zich de laatste jaren geprofileerd als de meest krachtige en flexibele aanpak.
Belangrijkste evoluties¶
Variational Auto Encoders (VAE)¶
Een auto-encoder architectuur leert om inputs te compresseren naar (encoding), en te reconstrueren (decoding) van, latente representaties in een lager dimensionele ruimte. Bij een variational auto-encoder (Kingma & Welling (2013)) zijn die latente representaties kansverdelingen, wat toelaat om nieuwe voorbeelden (samples) te genereren.
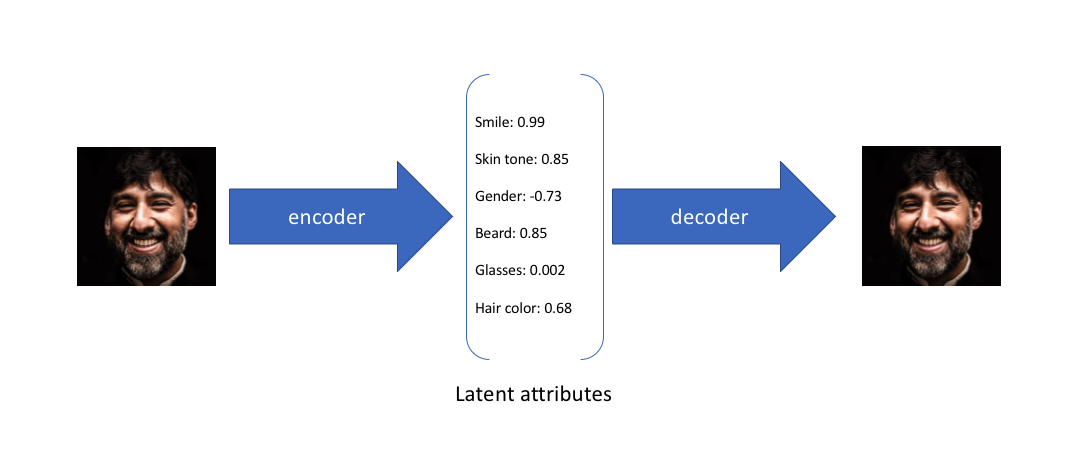
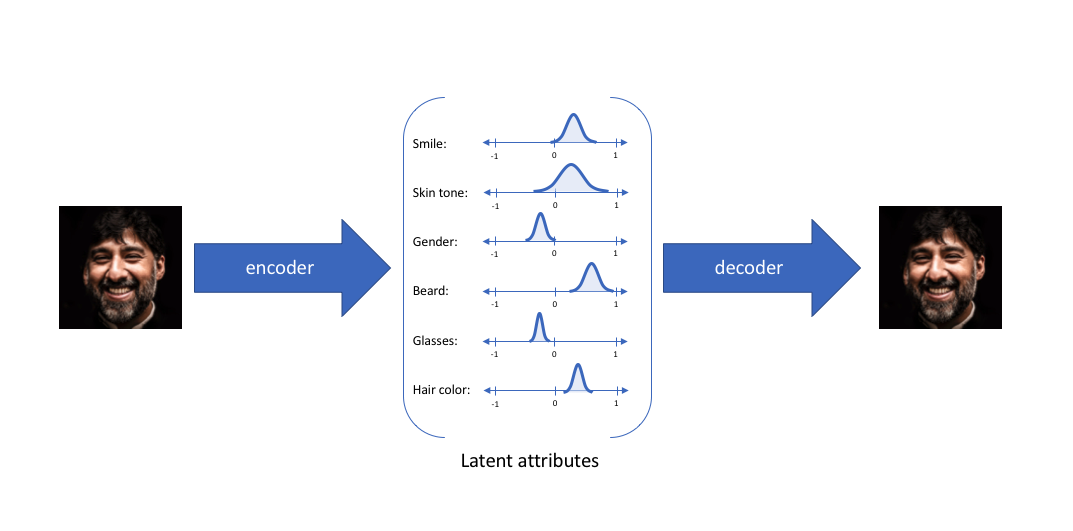
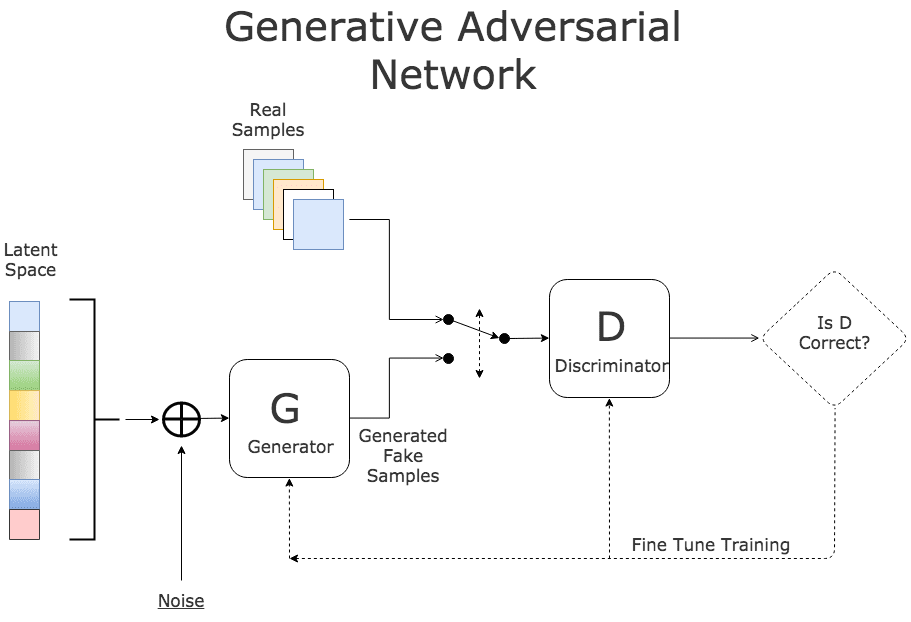
Generative Adversarial Networks (GAN)¶
In deze revolutionaire benadering van Goodfellow et al. (2014) wordt een model getraind om nieuwe samples te genereren vanuit pure ruis. Dit gebeurt aan de hand van een slim concept: tijdens het trainen wordt een groter model getraind waarbij een discriminator moet leren om echte van fake samples te onderscheiden. Hierdoor ontstaat een interne strijd (vandaar de naam adversarial networks): de generator probeert om steeds realistischere samples te produceren uit ruis en de discriminator probeert de generator “door” te krijgen.
Diffusion Modellen¶
Dit idee werd reeds kort na GANs geïntroduceerd door Sohl-Dickstein et al. (2015), maar het duurde tot verbeteringen door Song & Ermon (2019) en Ho et al. (2020) vooraleer er een algemene doorbraak kwam. Hieronder duiken we dieper in dit specifiek modeltype. Het is de backbone van vrijwel alle SOTA beeldgeneratoren zoals bijvoorbeeld Stable Diffusion (Stability AI). In vergelijking met VAE’s leiden diffusion modellen over het algemeen tot kwalitatievere beelden. Tegenover GAN’s zijn ze vooral veel stabieler om te trainen.
🤗 Stable Diffusion
Diffusion modellen¶
Diffusion modellen genereren beelden door stapsgewijs ruis te verwijderen uit een beginbeeld dat volledig uit ruis bestaat. De naam verwijst naar fysische diffusie waarbij moleculen zich verspreiden van een hoge naar een lage concentratie.
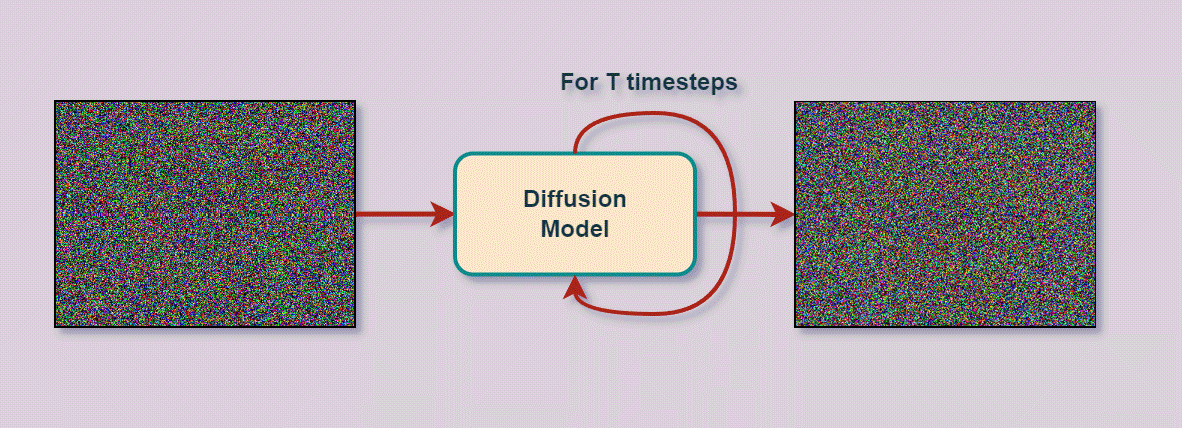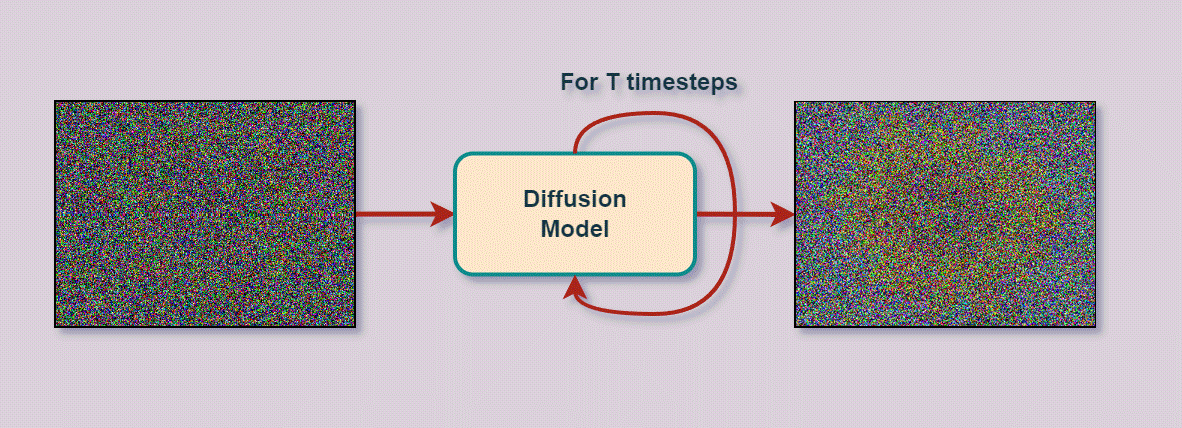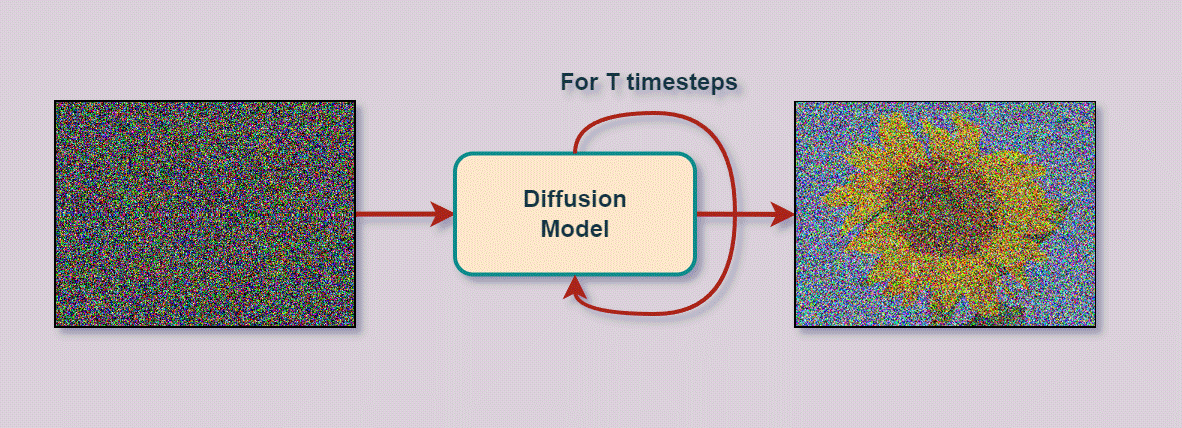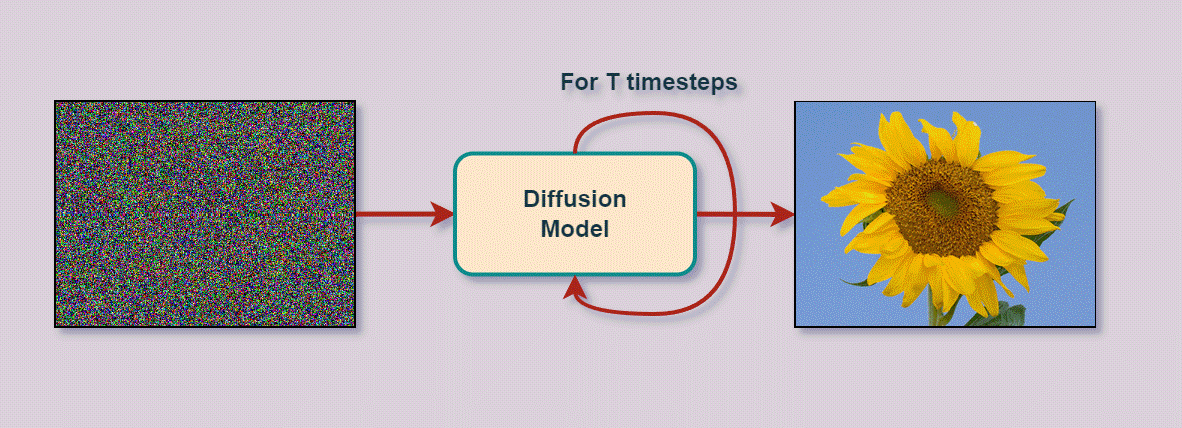
Het concept is eenvoudig. Het bestaat uit twee processen: Forward diffusion en Reverse diffusion.
Forward diffusion¶
In het voorwaartse proces wordt gradueel meer ruis toegevoegd aan een origineel beeld, meestal in 1000+ stappen. Dit proces is volledig deterministisch en houdt dus geen machine learning in. Ruis wordt gesampled uit een kansverdeling, maar mits controle van de initiële random seed, is dit 100% reproduceerbaar. De ruis wordt gesampled uit een Gauss-verdeling met gemiddelde 0 en een gradueel toenemende variantie
Source
import matplotlib.pyplot as plt
import numpy as np
import torch
import torch.nn.functional as F
from PIL import Image
# Set random seed for reproducibility
rng = np.random.default_rng(42)
torch.manual_seed(42)
# Simple visualization of the forward diffusion process
# Load the sample image
def load_sample_image(path="../../../img/all_models_are_wrong.jpg"):
"""Load and preprocess an image for demonstration."""
img = Image.open(path)
# Convert to numpy array and normalize to [0, 1]
img = np.array(img) / 255.0
# Ensure it's RGB (in case it's RGBA or grayscale)
if img.ndim == 2:
img = np.stack([img] * 3, axis=-1)
elif img.shape[2] == 4:
img = img[:, :, :3]
return img
# Create noise schedule (linear)
def create_noise_schedule(timesteps=1000, beta_start=0.0001, beta_end=0.02):
"""Create a linear noise schedule."""
betas = np.linspace(beta_start, beta_end, timesteps)
alphas = 1.0 - betas
alphas_cumprod = np.cumprod(alphas)
return betas, alphas, alphas_cumprod
# Forward diffusion: add noise to image
def forward_diffusion(x0, t, alphas_cumprod):
"""Add noise to image at timestep t."""
# x0: original image, shape (H, W, C)
# t: timestep (scalar)
alpha_t = alphas_cumprod[t]
# Generate random noise
noise = rng.normal(size=x0.shape)
# Noisy image
x_t = np.sqrt(alpha_t) * x0 + np.sqrt(1 - alpha_t) * noise
return x_t, noise
# Visualize the forward process
img = load_sample_image()
timesteps = 1000
_, _, alphas_cumprod = create_noise_schedule(timesteps)
# Select specific timesteps to visualize
steps_to_show = [0, 50, 100, 250, 500, 999]
fig, axes = plt.subplots(2, 3, figsize=(15, 10))
axes = axes.ravel()
for idx, t in enumerate(steps_to_show):
if t == 0:
noisy_img = img
else:
noisy_img, _ = forward_diffusion(img, t, alphas_cumprod)
# Clip values for display
noisy_img_display = np.clip(noisy_img, 0, 1)
axes[idx].imshow(noisy_img_display)
axes[idx].set_title(f"Timestep t={t}")
axes[idx].axis("off")
plt.suptitle("Forward Diffusion Process: Gradual Addition of Noise", fontsize=14)
plt.tight_layout()
plt.show()
Reverse diffusion¶
Reverse diffusion is het tegenovergestelde denoising proces. Dit is waar de eigenlijke machine learning voor beeldgeneratie gebeurt. Er wordt een neuraal netwerk getraind met (a) als input één van de forward samples én de tijdstap en (b) als target output de ruis die werd toegevoegd aan . Het getrainde netwerk wordt dan gebruikt om stapsgewijs vanuit een ruis steekproef tot een nieuw beeld te komen.
Er bestaan veel varianten inzake specifieke implementatie (zie bijvoorbeeld Yang et al. (2022)). In implementaties zoals Stable Diffusion, wordt er bijvoorbeeld ook met tekstuele grounding waardoor het reverse diffusion proces door natuurlijke taal gestuurd kan worden.
Attention U-Net¶
Veel diffusion modellen maken gebruik van de Attention U-Net CNN architectuur. Die werd oorspronkelijk ontwikkeld in de context van medische beeldsegmentatie Oktay et al. (2018). De belangrijkste redenen hiervoor zijn:
Skip connections: Er zijn rechtstreekse verbindingen tussen “vroege” en “late” lagen (wat grafisch aanleiding geeft tot een U-vormig netwerk). Hierdoor kan er zowel met lokale details als globalere context rekening worden gehouden bij het voorspellen van outputs.
Encoder-Decoder structuur:
Encoder: Comprimeert het beeld naar een lagere resolutie.
Decoder: Bouwt het beeld weer op naar de originele resolutie.
Aandacht: Bij Attention U-Net wordt bijkomend een specifieke attention module getraind om context op een zinvolle manier variabel te wegen.
Gemakkelijk te koppelen aan andere netwerken, bijvoorbeeld LLMs voor tekstuele grounding.

Een cruciale aanpassing in de context van diffusion models is dat het netwerk moet weten in welke stap van het diffusie proces het zich bevindt. Dit gebeurt via sinusoidal positional encoding. Deze encoding wordt door het hele netwerk geïnjecteerd via specifieke lagen (zgn. adaptive normalization lagen).
Cross-attention¶
Bij de meeste courante diffusion modellen zoals Stable Diffusion, kan het denoising proces geleid worden vanuit tekst (bv. “een rode appel op een blauwe tafel”). Dit wordt mogelijk gemaakt door zogenaamde cross-attention. Dit mechanisme fungeert bij moderne neurale netwerken algemeen als de brug tussen twee verschillende soorten informatie (of modaliteiten). Zoals we zagen bij Transformers, gaat het ook hier over een aandachtsmechanisme met Keys, Values en Queries. Bij tekstuele grounding wordt de input tekst prompt eerst via een pre-trained netwerk vertaald naar een tekst-embedding. Het netwerk leert om deze embeddings te vertalen naar Keys (denk bv. “appel”, “tafel”) en Values (“rood”, “blauw”, “appel op tafel”). Tijdens het denoising proces fungeren de pixels als Queries en kan het netwerk op die manier bij het voorspellen van ruis, op bepaalde plaatsen in het beeld selectief rekening houden met bepaalde Values uit de prompt.
Parameters¶
De Attention U-Net parameters vormen de bulk van de parameterruimte, uitgebreid met de cross-attention parameters bij grounding. Net zoals bij Transformers gaat het hier over enorm veel (miljarden) parameters om de huidige graad van kwaliteit in beeldgeneratie te behalen.
Features¶
De features worden zoals bij reguliere beeldherkenning bepaald door de input resolutie (aantal pixels) en het aantal kanalen (RGB, RGB-D, enz.). Bij tekstuele grounding worden prompts via standaard tokenizers naar features vertaald.
Leeralgoritme¶
Diffusion modellen worden zoals andere neurale netwerken getraind met varianten van stochastic gradient descent en gebruiken backpropagation om gradiënten te berekenen door het hele netwerk. De Loss functie is bijzonder eenvoudig: de Mean Squared Error tussen echte ruis en voorspelde ruis .
Deze eenvoudige loss-functie staat in contrast met GAN en VAE’s waar respectievelijk, adversarial loss en Kullback Leibler divergence gebruikt worden. Diffusion models zijn hierdoor over het algemeen stabieler tijdens de training, gemakkelijk op te schalen (wat cruciaal is voor performantie) en flexibeler (gemakkelijk uit te breiden met grounding netwerken).
LoRA¶
In de praktijk wordt heel vaak via fine-tuning gewerkt, en dan vooral via zogenaamde Low-Rank Adaptation (LoRA; Hu et al. (2021)). Het principe is om in plaats van het volledige model te fine-tunen, kleine adapter matrices te trainen.
waarbij:
: Frozen pre-trained weights
, : Trainable low-rank matrices
: Rank (typisch 4-16)
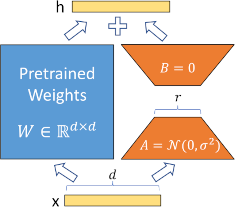
Door LoRa moet slechts een kleine hoeveelheid parameters getraind worden. Meerdere LoRAs kunnen ook gecombineerd worden. Er zijn geen enorme datasets of trainingsinfrastructuur nodig. Dit verklaart de enorme populariteit van het algoritme in de ML-gemeenschap.
🌍 Civitai
Civitai host duizenden community-trained LoRA modellen voor Stable Diffusion:
Anime styles
Artistic styles (oil painting, watercolor, enz.)
Specific artists
Characters and objects
Photography styles

Taak¶
De kerntaak is om nieuwe voorbeelden te creëren die zo min mogelijk te onderscheiden zijn van de echte trainingsdata.
In bepaalde toepassingen worden diffusion modellen gebruikt om trainingsdata te genereren om beeldherkenningsmodellen te trainen (bv. voor object detectietaken).
Ervaring¶
Het principe om noise te voorspellen uit het forward proces komt neer op self-supervision. Op die manier kunnen diffusion modellen gemakkelijk met ongelabelde datasets getraind worden. Om foto-realistische beelden te genereren zijn echter, proportioneel aan het aantal parameters, enorme hoeveelheden beelden nodig. Dit verklaart waarom, zoals voor LLM’s, slechts een beperkt aantal bedrijven in staat is om dit soort modellen (from scratch) te trainen.
Voor tekstuele grounding moet er voor de training ook gewerkt worden met beelden én hun tekstuele beschrijving (bv. LAION-5B).
Evaluatie¶
Er bestaan een aantal specifieke scores in de context van beeldgeneratie. Zoals bij NLP taken is automatische scoring niet altijdeven toereikend. Daarvoor wordt er ook gewerkt met menselijke scoring waarbij onder andere gelet wordt op realisme, duidelijkheid, compositie en overeenkomst met de prompt.
Fréchet Inception distance¶
Deze score drukt de afstand uit tussen de statistische verdeling van gegenereerde beelden en de trainingsbeelden. Beide soorten beelden worden met een standaard pre-trained beeldherkenningsmodel (Inception-v3) vertaald naar embedding-vectoren. Daarna wordt de afstand tussen het gemiddelde en de covariantie van die embedding-vectoren berekend (hoe lager, hoe beter).
Inception score¶
De gegenereerde beelden worden als input aangeboden aan een standaard klassificatiemodel (Inception-v3) dat enkel met echte beelden getraind werd. Dan wordt gekeken hoeveel onzekerheid er in de output aanwezig is (door entropie te berekenen). Hoe meer zekerheid (minder entropie), hoe beter.
CLIP Score¶
Deze maat meet de kwaliteit van tekstuele grounding op basis van de embeddings van het CLIP (Contrastive Language–Image Pre-training) model. Ze drukt de cosine-similarity uit tussen de CLIP-embedding van gegenereerde beelden met de CLIP-embedding van de overeenkomstige prompts (hoe groter, hoe beter).
Inference¶
De originele Denoising Diffusion Probabilistic Models (DDPM; Ho et al. (2020)) doorlopen alle 1000+ stappen van denoising, maar zijn daardoor erg intensief in berekeningen. Er kwam een grote verbetering door zogenaamde Denoising Diffusion Implicit Models (DDIM; Song et al. (2020)) waarbij slechts in 50-100 stappen een goede kwaliteit behaald wordt. Sindsdien zijn nog verschillende optimalisaties ontwikkeld (bv. DPM-Solver Lu et al. (2022), UniPC Zhao et al. (2023)).
Voordelen¶
Tegenover eerdere beeldgeneratiemodellen zijn diffusion modellen vooral
stabieler om te trainen,
gemakkelijk op te schalen tot hele grote modellen met foto-realistische performantie en
heel flexibel richting tal van verschillende toepassingen.
Toepassingen
Text-to-Image: Het genereren van beelden op basis van tekstuele beschrijvingen.
Image-to-Image: Transformatie van beelden naar andere stijlen, het aanpassen van bestaande beelden, of het uitbreiden van beelden.
Inpainting: Het invullen of vervangen van delen van een beeld op een natuurlijke manier.
Outpainting: Het uitbreiden van een beeld buiten de oorspronkelijke grenzen.
Super-resolution: Het verhogen van de resolutie van beelden terwijl details worden toegevoegd.

Video generatie: bv. Runway Gen-4, Sora, Veo, enz.
Nadelen¶
Training: Zeer intensief, zeker indien van nul
Inference: Groot geheugen en (GPU) rekenkracht nodig, zeker voor hogere resoluties
Energie & water verbruik: Aanzienlijke milieu-impact van training en deployment
Artefacten: Het feit dat de meeste mensen 5 vingers hebben of auto’s niet opzij rijden is geen kennis die deze modellen expliciet opbouwen. Daardoor is de output vatbaar voor artefacten.
Bias: Stereotypische beelden in de trainingsdata worden (soms subtiel) vertaald naar de outputs
Over fitting: Kunnen trainingsdata memoriseren en lekken. Door onrechtmatige scraping kunnen daardoor copyright inbreuken tot stand komen.
Ethisch gebruik: De enorme performantie van recente modellen voedt onethische/criminele praktijken (bv. deep-fake video’s)
- Kingma, D. P., & Welling, M. (2013). Auto-Encoding Variational Bayes. arXiv. 10.48550/ARXIV.1312.6114
- Goodfellow, I. J., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., & Bengio, Y. (2014). Generative Adversarial Networks. arXiv. 10.48550/ARXIV.1406.2661
- Sohl-Dickstein, J., Weiss, E. A., Maheswaranathan, N., & Ganguli, S. (2015). Deep Unsupervised Learning using Nonequilibrium Thermodynamics. arXiv. 10.48550/ARXIV.1503.03585
- Song, Y., & Ermon, S. (2019). Generative Modeling by Estimating Gradients of the Data Distribution. arXiv. 10.48550/ARXIV.1907.05600
- Ho, J., Jain, A., & Abbeel, P. (2020). Denoising Diffusion Probabilistic Models. arXiv. 10.48550/ARXIV.2006.11239
- Yang, L., Zhang, Z., Song, Y., Hong, S., Xu, R., Zhao, Y., Zhang, W., Cui, B., & Yang, M.-H. (2022). Diffusion Models: A Comprehensive Survey of Methods and Applications. arXiv. 10.48550/ARXIV.2209.00796
- Oktay, O., Schlemper, J., Folgoc, L. L., Lee, M., Heinrich, M., Misawa, K., Mori, K., McDonagh, S., Hammerla, N. Y., Kainz, B., Glocker, B., & Rueckert, D. (2018). Attention U-Net: Learning Where to Look for the Pancreas. arXiv. 10.48550/ARXIV.1804.03999
- Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., & Chen, W. (2021). LoRA: Low-Rank Adaptation of Large Language Models. arXiv. 10.48550/ARXIV.2106.09685
- Song, J., Meng, C., & Ermon, S. (2020). Denoising Diffusion Implicit Models. arXiv. 10.48550/ARXIV.2010.02502
- Lu, C., Zhou, Y., Bao, F., Chen, J., Li, C., & Zhu, J. (2022). DPM-Solver: A Fast ODE Solver for Diffusion Probabilistic Model Sampling in Around 10 Steps. arXiv. 10.48550/ARXIV.2206.00927
- Zhao, W., Bai, L., Rao, Y., Zhou, J., & Lu, J. (2023). UniPC: A Unified Predictor-Corrector Framework for Fast Sampling of Diffusion Models. arXiv. 10.48550/ARXIV.2302.04867