📚 [1]
Reinforcement Learning¶
Zoals we reeds zagen in de bespreking van ML taken, is het bij actieplanning de bedoeling om optimale actiesequenties te leren, met het oog op het bereiken van een bepaald doel. Hierbij wordt gewerkt met een specifieke vorm van ervaring: reinforcement learning (RL). In tegenstelling tot (self-)supervised learning, wordt er bij RL in de zoektocht naar optimale parameters geen rechtstreekse feedback gegeven over de juistheid van een individuele actie. In tegenstelling tot unsupervised learning, wordt het leren gestuurd door op zoek te gaan naar een zo groot mogelijke cumulatieve beloning uit de omgeving.
Agents die via RL getraind worden, hebben de volgende algemene eigenschappen:
Iteratieve output: De agent bepaalt niet in één keer de hele sequentie van acties, maar registreert en integreert na iedere actie feedback over de gevolgen van die actie in de omgeving in een nieuwe (voorspelde) actie.
Trial-and-error learning: Leren gebeurt door acties uit te proberen en de uiteindelijke beloning te observeren.
Markov-eigenschap: Dit is een centrale aanname: om te weten wat de beste volgende actie is, heeft de agent enkel kennis nodig van de huidige stand van zaken in de omgeving (state). In een schaakspel, bijvoorbeeld, worden acties enkel genomen op basis van reflecties over de toekomst, gegeven de huidige staat op het bord, niet op basis van reflecties over hoe de huidige staat tot stand kwam.
RL Loop¶
Het RL proces moet gezien worden als een continue loop van interacties tussen een agent en een omgeving:
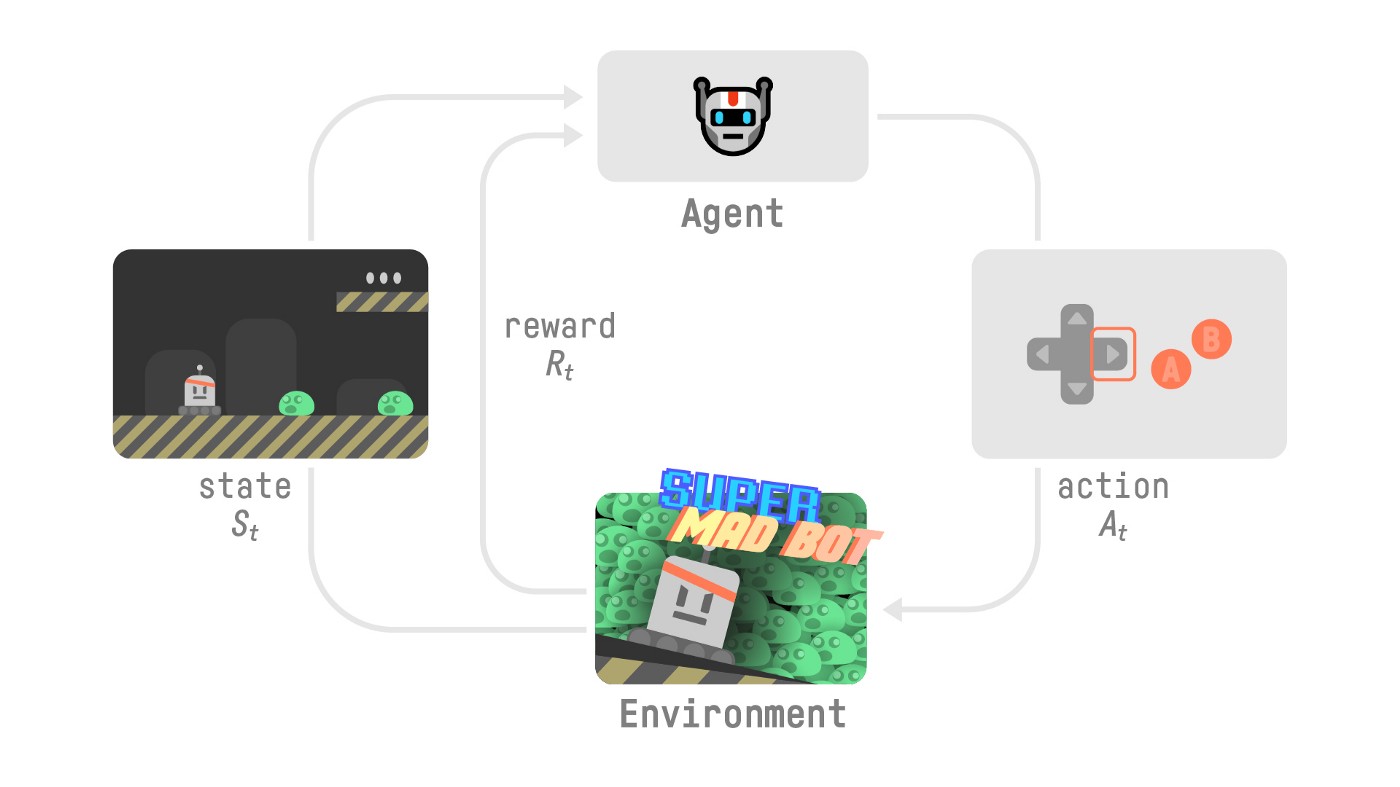
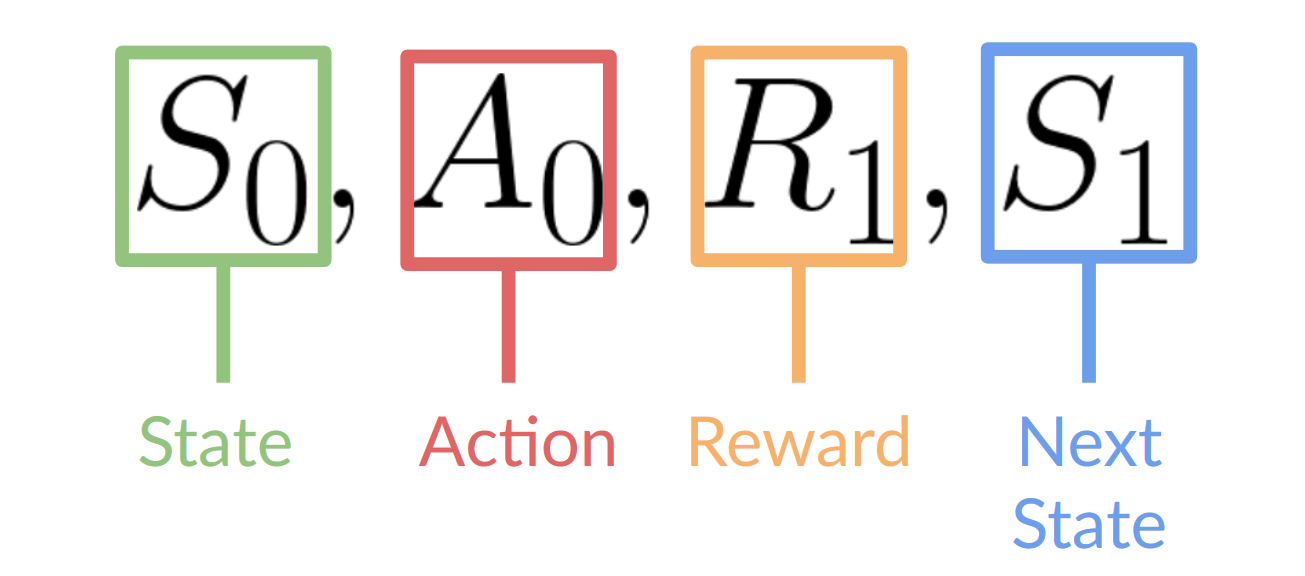
De cyclus werkt als volgt:
De agent observeert de huidige state van de omgeving
Op basis van die state kiest de agent een actie
Dit geeft aanleiding tot een een nieuwe state in de omgeving
Of basis van die verandering, krijgt de agent een reward signaal uit de omgeving
Het doel van de agent is om de cumulatieve reward over tijd te maximaliseren.
Kernconcepten¶
Omgeving¶
Dit is de “wereld” waarin de agent zich begeeft.
States¶
Een state is een momentane beschrijving van de omgeving. De state is hetzij volledig geobserveerd (bv. bij een schaakbord),

hetzij gedeeltelijk geobserveerd (bv. bij een videogame zoals Super Mario).

In de praktijk onderscheiden we daarom:
State : De complete beschrijving van de omgeving op een bepaald moment .
Observatie : Het gedeelte van de omgeving dat de agent waarneemt op moment .
Acties¶
De action space bevat alle mogelijke acties die een agent kan uitvoeren:
Discrete action space: Eindig aantal acties (bijv. Super Mario: links, rechts, springen, bukken)
Continue action space: Oneindig aantal acties (bijv. de stuurhoek bij een zelfrijdende wagen)
Rewards¶
De reward of beloning is het enige feedbacksignaal voor de agent waaruit het tijdens de training de optimale parameters gezocht kunnen worden voor de onderliggende ML modellen. De reward hypothese stelt dat alle doelen kunnen worden beschreven als het maximaliseren van de verwachte cumulatieve reward.
De cumulatieve reward of return is gegeven als:
waarbij staat voor het traject: de sequentie van state-actieparen tot op moment .
Op basis van de onderliggende ML modellen, kunnen agents (expliciet of impliciet) rekening houden met expected cumulatieve rewards om de meest wenselijke volgende actie te bepalen. Omdat voorspellingen onzekerder zijn naarmate ze verder in de toekomst liggen, wordt bij de berekening van de return een correctie toegepast naarmate de returns verder in de toekomst liggen. Hierdoor kan er bij de keuzes van acties voorkeur gegeven worden aan acties met een meer onmiddellijke winst. Dit gebeurt aan de hand van een discount factor, wat resulteert in de discounted return is:
waarbij (gamma) de discount factor is ():
dicht bij 1: Agent houdt rekening met lange-termijn rewards
dicht bij 0: Agent focust op korte-termijn rewards
Value functie¶
De value functie is de functie die de verwachte discounted return bepaalt gegeven een bepaalde state (-functie) of state-actiepaar (-functie).
Policy¶
De policy is de strategie van de agent - het bepaalt welke actie de agent kiest in een bepaalde state:
Dit kan zijn:
Deterministisch: - altijd dezelfde actie voor een state
Stochastisch: - kansverdeling over acties
Modellen¶
Het doel van de agent is om tijdens de trainingsfase de optimale policy te vinden die de verwachte return maximaliseert. Hiervoor bestaan fundamenteel twee benaderingen: model-free en model-based RL.
Model-free RL¶
Bij model-free RL leert de agent rechtstreeks uit ervaring zonder een expliciet model van de omgevingsdynamieken te leren. De agent leert welke acties goed zijn door ze uit te proberen en de rewards te observeren. Dit kan op twee manieren:
Policy-based: Er wordt een ML model getraind met states als input en acties als output. Daaruit krijgt de agent bij inference dus rechtstreeks informatie over de optimale actie.
Value based: Een ML model leert de return te voorspellen, voor verschillende states of state-actieparen. Daarna kan de agent, gegeven een bepaalde state, bijvoorbeeld de actie kiezen met de grootste verwachte return (dit is een zogenaamde greedy policy).
Voordelen van model-free RL:
Eenvoudiger te implementeren
Geen modelfouten die kunnen accumuleren
Werkt goed wanneer de omgeving te complex is om te modelleren
Nadelen van model-free RL:
Sample inefficiënt: Vereist veel interacties met de omgeving
Geen planning mogelijk: Kan niet “nadenken” over toekomstige scenario’s zonder echte ervaring
Model-based RL¶
Bij model-based RL leert de agent een expliciet model van de omgevingsdynamieken. Dit model voorspelt hoe de omgeving zal reageren op acties:
Met dit geleerde model kan de agent:
toekomstige trajecten simuleren zonder echte interacties
Verschillende acties “in gedachten” uitproberen voordat er een keuze gemaakt wordt
Gesimuleerde ervaringen genereren om training te versnellen
Voordelen van model-based RL:
Sample efficiënt: Kan veel leren uit weinig echte interacties
Planning: Kan vooruitdenken en plannen maken
Transfer learning: Modelkennis kan hergebruikt worden voor nieuwe taken in dezelfde omgeving
Interpreteerbaarheid: Het geleerde model kan inzicht geven in hoe de omgeving werkt
Nadelen van model-based RL:
Error propagation: Kleine fouten in het model kunnen leiden tot grote fouten in planning
Complexiteit: Het leren van accurate omgevingsmodellen kan zeer uitdagend zijn
Computational cost: Planning met modellen vereist extra berekeningen
Niet altijd praktisch: Voor zeer complexe omgevingen (bv. sociale interacties) is een accuraat model vaak onhaalbaar
Het bekendste voorbeeld van een model-based RL algoritme is wellicht MuZero; Google DeepMind’s algoritme dat o.a. schaak en Go beheerst zonder de spelregels te kennen.
Hybride benaderingen¶
In de praktijk worden model-free en model-based benaderingen vaak gecombineerd om de voordelen van beide te benutten:
Model-geassisteerde model-free learning: Gebruik het model om extra training data te genereren
Dyna-architecturen: Wissel af tussen echte ervaring en gesimuleerde ervaring
Ensemble methoden: Gebruik meerdere modellen om onzekerheid te schatten
In principe kan ieder type ML model in deze benaderingen gekoppeld worden. In wat volgt zullen we echter focussen op toepassingen met deep learning modellen of zogenaamde Deep RL. De beschrijving van deze modellen, in termen van architectuur, parameters, features en hyperparameters wordt bepaald door de use-case en heeft geen specifieke eigenschappen die gekoppeld zijn aan het domein van actieplanning.
Leeralgoritmes¶
De training is bij RL doorgaans veel complexer dan bij andere domeinen van ML. Dat komt vooral door de verschillende leeralgoritmes, hyperparameters (bv. om exploratie versus exploitatie te bepalen) en complexe loss functies om de reward signalen te vertalen naar de updates voor de modelparameters. Door de grote variabiliteit, bestaat er een reëel risico op instabiele training. Die variabiliteit komt uiteraard ook uit de omgeving van de agent zelf die soms heel complex kunnen zijn (denk bv. aan een zelfrijdende wagen). Hoe krachtig de resultaten van RL ook kunnen zijn, het toepassen van RL in een nieuwe omgeving blijft doorgaans heel uitdagend.
De leeralgoritmes hangen nauw samen met de gekozen modeltypes. We bespreken hier de belangrijkste algoritmes voor model-free en model-based RL.
Model-free leeralgoritmes¶
Q-learning¶
Q-Learning is een value based algoritme waarbij een optimale state-actie value functie (of model) geleerd wordt. Een greedy policy neemt dan meestal de volgende vorm aan:
Bij Deep Q Learning wordt de zogenaamde -loss berekend door de voorspelde (discounted) return bij een gegeven state-actionpaar te vergelijken met een -target (in de standaard MSE vorm). Die target wordt geschat door de voorspellingen van het model zelf (met parameters ) over de -value van de volgende state , samen met de onmiddellijke return , in de zogenaamde Bellman vergelijking in te vullen:
De gradient van de -loss wordt dan gebruikt om de parameters van het neurale netwerk via standaard backpropagation en gradient descent te updaten.
Policy gradient learning¶
Deze familie van leeralgoritmes zijn policy based. Er wordt dus rechtstreeks een optimale policy-functie (of model) geleerd. Policy gradient learning past gradient ascent toe op de gradient van de verwachtte return (om die dus te maximaliseren):
Waarbij:
: De richting die de probabiliteit van actie verhoogt.
: De return (cumulatieve reward) vanaf tijdstip .
Het dot-product: Verhoogt de probabiliteit van acties die tot hoge returns leidden en verlaag de probabiliteit van acties tot lage returns leidden.
Dit vormt de basis van het REINFORCE algoritme door Williams (1992). In recent werk wordt meestal gewerkt met het zogenaamde Proximal Policy Optimization (PPO) algoritme wat over het algemeen stabielere resultaten oplevert.
Merk op dat de optimalisatie hier niet op basis van een loss functie gebeurt, maar door rechtstreeks de verwachtte return te maximaliseren[2].
Actor-critic learning¶
Hierbij wordt een value-functie gecombineerd met een policy-functie. De actor leert de policy terwijl de critic de value-functie of leert. In plaats van de werkelijke returns te gebruiken bij het updaten van de policy (zoals bij policy gradient learning), worden value-predicties van de critic gebruikt (expected return). Net zoals het PPO algoritme, leidt deze techniek over het algemeen tot stabielere resultaten. Doordat er niet moet gewacht worden tot tot het einde van een interactie om de werkelijke return te berekenen, wordt deze benadering vaak gekozen omwille van sample efficiëntie en bij continue taken (bv. robotica; zie verder). De meest populaire variant Soft-Actor-Critic (SAC) introduceert ook entropie in de parameter-optimalisatie functie (Haarnoja et al. (2018)).
Model-based leeralgoritmes¶
Bij model-based RL draait het leerproces om twee afzonderlijke maar gekoppelde leertaken:
Het leren van het omgevingsmodel
Het leren van de optimale policy op basis van het omgevingsmodel
Omgevingsmodel¶
Het eerste leerprobleem is het trainen van een model dat de omgevingsdynamieken voorspelt. Het model wordt getraind met standaard supervised learning technieken (bv. gradient descent op de MSE loss), gebruikmakend van echte ervaringen verzameld uit interacties met de omgeving.
Policy model¶
Eens het omgevingsmodel getraind is, kan het gebruikt worden om de optimale policy te vinden. Er bestaan verschillende varianten:
Dyna-Q¶
Combineert model-free Q-learning met model-based planning:
Voer een echte actie uit in de omgeving en observeer
Update op basis van deze echte ervaring (model-free update)
Gebruik het omgevingsmodel om gesimuleerde transities te genereren
Update ook op basis van deze gesimuleerde ervaringen (model-based update)
Model Predictive Control (MPC)¶
Bij elke beslissing:
Simuleer meerdere mogelijke actiesequenties met het omgevingsmodel
Evalueer welke sequentie de hoogste verwachte cumulatieve reward oplevert
Voer alleen de eerste actie van de beste sequentie uit
Herhaal dit proces bij de volgende state (receding horizon)
World Models¶
Leert een compact latent model van de omgeving:
Train een variational autoencoder (VAE) om observaties te comprimeren naar een latente representatie
Train een recurrent model (bv. Transformer) om toekomstige latente states te voorspellen
Train een policy volledig binnen de geleerde latente ruimte (dreaming)
Dit is bijzonder nuttig voor visueel complexe omgevingen (bv. videogames) waar het direct voorspellen van pixels te moeilijk is.
Taken¶
We maken een onderscheid tussen twee soorten taken afhankelijk of er sprake is van een eind-state.
Episodische taken¶
Hierbij is er een duidelijke eind-state, bijvoorbeeld, wanneer een game uitgespeeld is.
Continue taken¶
Hierbij is er geen eindpunt. Denk aan autonoom rijden, robotica, trading, enz.
RL is geschikt voor problemen waarbij:
sequentiële beslissingen cruciaal zijn,
interactie met omgeving mogelijk is,
feedback of wenselijk of onwenselijke predicties (rewards) pas na verloop van tijd duidelijk worden en
geen expliciete labels beschikbaar zijn,
zoals bij:
🎮 Game AI: AlphaGo, Dota 2, StarCraft II
🤖 Robotica: Lopen, grijpen, manipulatie
🚗 Autonome systemen: Zelfrijdende auto’s
💰 Trading: Automatische handelssystemen
🏭 Resource management: Datacenter koeling, energie-optimalisatie
💊 Gezondheidszorg: Behandelprotocollen, medicatie timing
🎯 Aanbevelingssystemen: Personalisatie over de tijd
Evaluatie¶
Bij RL evalueren we op basis van scores zoals:
Average return: De gemiddelde cumulatieve reward over meerdere episodes.
Success rate: Het percentage van de episodes waarin een specifiek doel wordt bereikt.
Leercurve: Hoe snel verbetert de agent tijdens training?
enz.
Dit is anders dan typische scores zoals accuracy bij klassificatie of MSE bij regressie, omdat we geïnteresseerd zijn in de prestaties over de tijd.
Voordelen¶
Geen gelabelde data nodig: RL leert rechtstreeks uit interactie met de omgeving, zonder vooraf gelabelde voorbeelden
Sequentiële besluitvorming: Ideaal voor problemen waar acties gevolgen hebben op toekomstige situaties
Adaptief leren: Agents kunnen zich aanpassen aan veranderende omgevingen en nieuwe situaties
Autonomie: Agents ontdekken zelf strategieën die mensen misschien niet hadden bedacht (bv. AlphaGo)
Breed toepassingsgebied: Van games en robotica tot resource management en gezondheidszorg
Trial-and-error: Natuurlijke leerwijze die exploratie en experimenteren mogelijk maakt
Nadelen¶
Sample inefficiëntie: Vaak miljoenen interacties nodig, zeker bij complexe omgevingen
Reward design: Vaak moeilijk om een goede reward functie te definiëren
Exploitatie-Exploratie trade-off
Credit assignment: Uitdagend om wiskundig te bepalen welke acties verantwoordelijk waren voor rewards (of het gebrek daaraan)
Training stability: RL training kan heel instabiel zijn
Sparse rewards: Bij veel problemen krijg je zelden feedback
Deze sectie is gebaseerd op de Hugging Face Deep RL Course.
Vandaar dat we hier te maken hebben met gradient ascent en niet gradient descent.
- Williams, R. J. (1992). Simple statistical gradient-following algorithms for connectionist reinforcement learning. Machine Learning, 8(3–4), 229–256. 10.1007/bf00992696
- Haarnoja, T., Zhou, A., Abbeel, P., & Levine, S. (2018). Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor. arXiv. 10.48550/ARXIV.1801.01290