Computer vision¶
Computer vision is, naast natural language processing (NLP), een domein binnen machine learning waar alles draait rond neurale netwerkmodellen. Computer vision richt zich op het automatisch interpreteren en begrijpen van digitale beelden. Het domein stond in het middelpunt van verschillende grote AI doorbraken. Het onderging in de voorbije decennia een ware transformatie onder impuls van (diepe) Convolutional Neural Networks (CNN) en meest recent, Vision Transformers.
In tegenstelling tot gestructureerde data waar we werken met tabulaire gegevens, hebben we hier te maken met beelden (RGB, RGB-D, hyper-spectraal, point-cloud) en sequenties daarvan. Het zijn bij uitstek voorbeelden van ongestructureerde data.
Alles draait om de automatische extractie van visuele patronen. Daar waar dit lang gebeurde op basis van deterministische filters, brachten CNNs de mogelijkheid om die filters rechtstreeks uit de data te leren wat een enorme sprong in performantie en flexibiliteit met zich meebracht.
Deterministische filter
Een voorbeeld van een deterministische filter is het Canny edge detection algoritme.

Canny edge detection is een klassieke computer vision techniek die randen in beelden detecteert aan de hand van een reeks vaste bewerkingen:
Noise reduction: Gaussian blur filter om ruis te verminderen
Gradient berekening: Bepalen van intensiteitsgradiënten (Sobel filters)
Non-maximum suppression: Dunne randen behouden, dikke randen elimineren
Double threshold: Onderscheid tussen sterke en zwakke randen
Edge tracking by hysteresis: Zwakke randen behouden enkel als ze verbonden zijn met sterke randen
Dit is een volledig deterministisch proces - er worden géén parameters geleerd uit data. De filters en drempelwaarden zijn handmatig ontworpen door domeinexperts. Dit contrasteert sterk met moderne deep learning benaderingen waar CNNs automatisch optimale filters leren uit trainingsdata.
Source
import cv2
import numpy as np
from matplotlib import patches
from matplotlib import pyplot as pltSource
# Load an example image (you can replace this with your own image path)
# For demo purposes, we'll create a simple synthetic image
image = np.ones((400, 600, 3), dtype=np.uint8) * 255
# Add some simple shapes to detect
cv2.rectangle(image, (50, 50), (150, 150), (255, 0, 0), -1)
cv2.circle(image, (400, 200), 60, (0, 255, 0), -1)
cv2.rectangle(image, (450, 300), (550, 380), (0, 0, 255), -1)
image = cv2.imread("../../../img/all_models_are_wrong.jpg")
# Convert to grayscale for feature detection
gray = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
gray_single = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# Apply Canny edge detection (deterministic feature extraction)
edges = cv2.Canny(gray_single, 50, 150)
# Find contours (object detection based on edges)
contours, hierarchy = cv2.findContours(edges, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# Draw bounding boxes around detected objects
result = image.copy()
for contour in contours:
x, y, w, h = cv2.boundingRect(contour)
cv2.rectangle(result, (x, y), (x + w, y + h), (0, 255, 255), 2)
# Display results
fig, axes = plt.subplots(1, 3, figsize=(15, 5))
axes[0].imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
axes[0].set_title("Original Image")
axes[0].axis("off")
axes[1].imshow(edges, cmap="gray")
axes[1].set_title("Edge Detection (Canny)")
axes[1].axis("off")
axes[2].imshow(cv2.cvtColor(result, cv2.COLOR_BGR2RGB))
axes[2].set_title(f"Object Detection ({len(contours)} objects found)")
axes[2].axis("off")
plt.tight_layout()
plt.show()
Convolutionele Neurale Netwerk Modellen¶
Convolutionele Neurale Netwerken (CNNs) hebben lange tijd (voor de komst van Vision Transformers) het domein van machine learning voor computer vision gedomineerd.
Het basis concept is dat ze in plaats van deterministische filters, aangeleerde (dus data-gedreven) filters toepassen om predicties te maken. Daardoor zijn ze veel flexibeler dan traditionele beeldverwerkings pipelines.
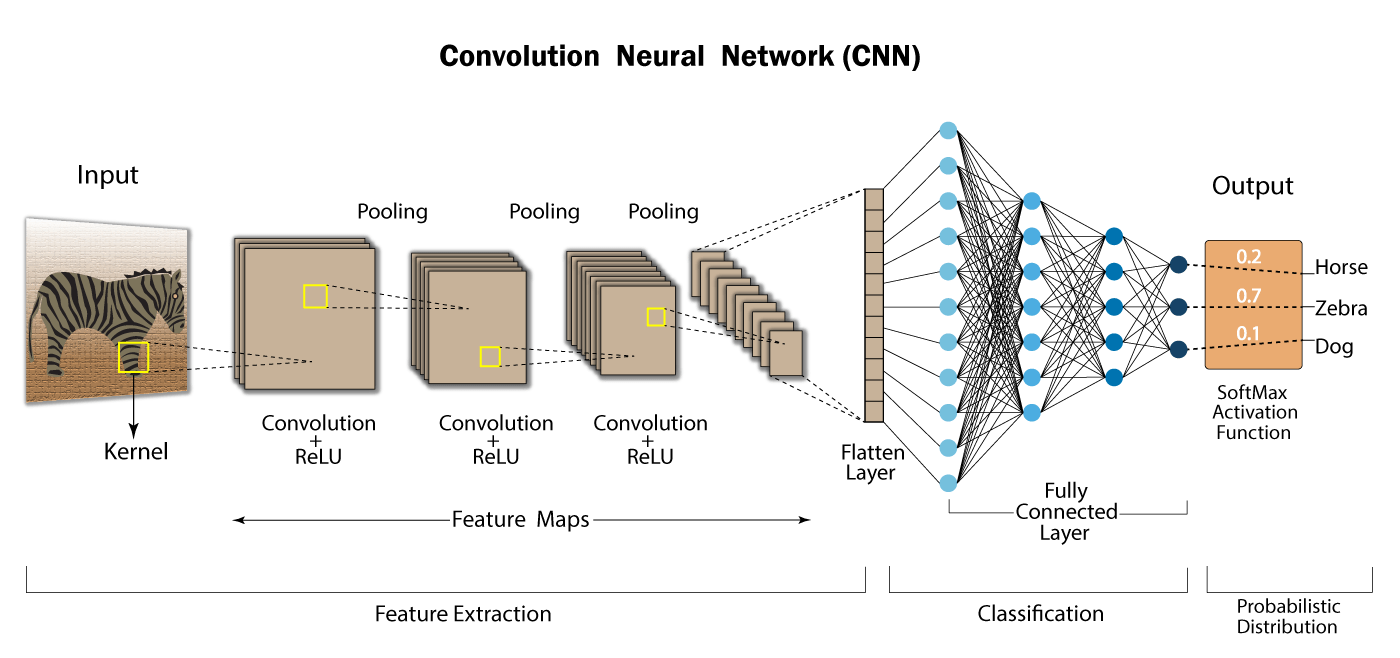
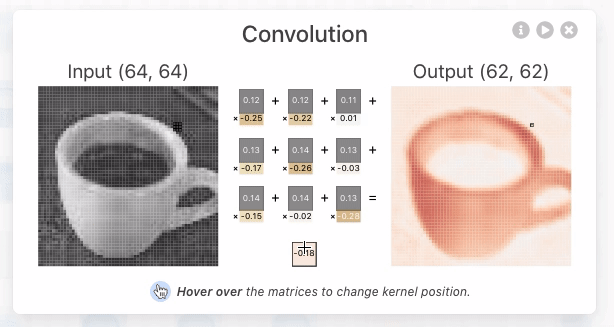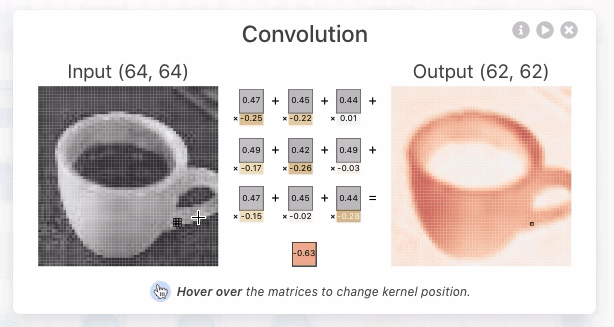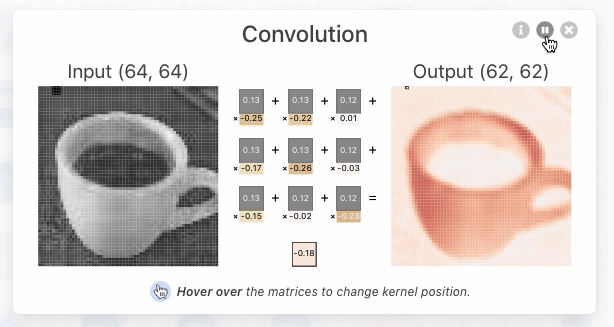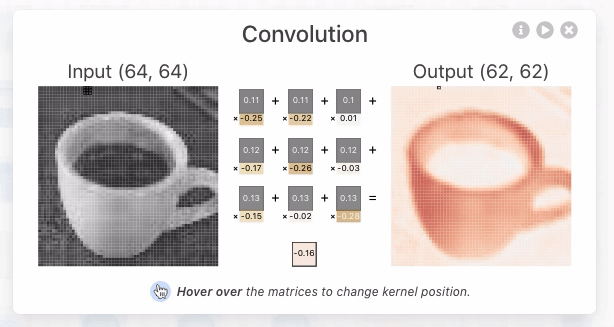
CNNs bestaan uit verschillende hiërarchische gestructureerde lagen. De lagen verschillen van elkaar naargelang de specifieke tensor-operaties die worden uitgevoerd. Deze familie van deep-learning neurale netwerken danken hun naam aan een specifiek type laag: convolutionele filters. Een dergelijke filter is in essentie een kleine tensor (een kernel genaamd) die over het input-grid verschoven wordt en waarmee een output-grid gecreëerd wordt via element-gewijze vermenigvuldiging en optelling.
Source
from ml_courses.sim.cnn_viz import (
visualize_activation_functions,
visualize_convolution_steps,
visualize_max_pooling,
visualize_padding,
visualize_stride_comparison,
)
visualize_convolution_steps()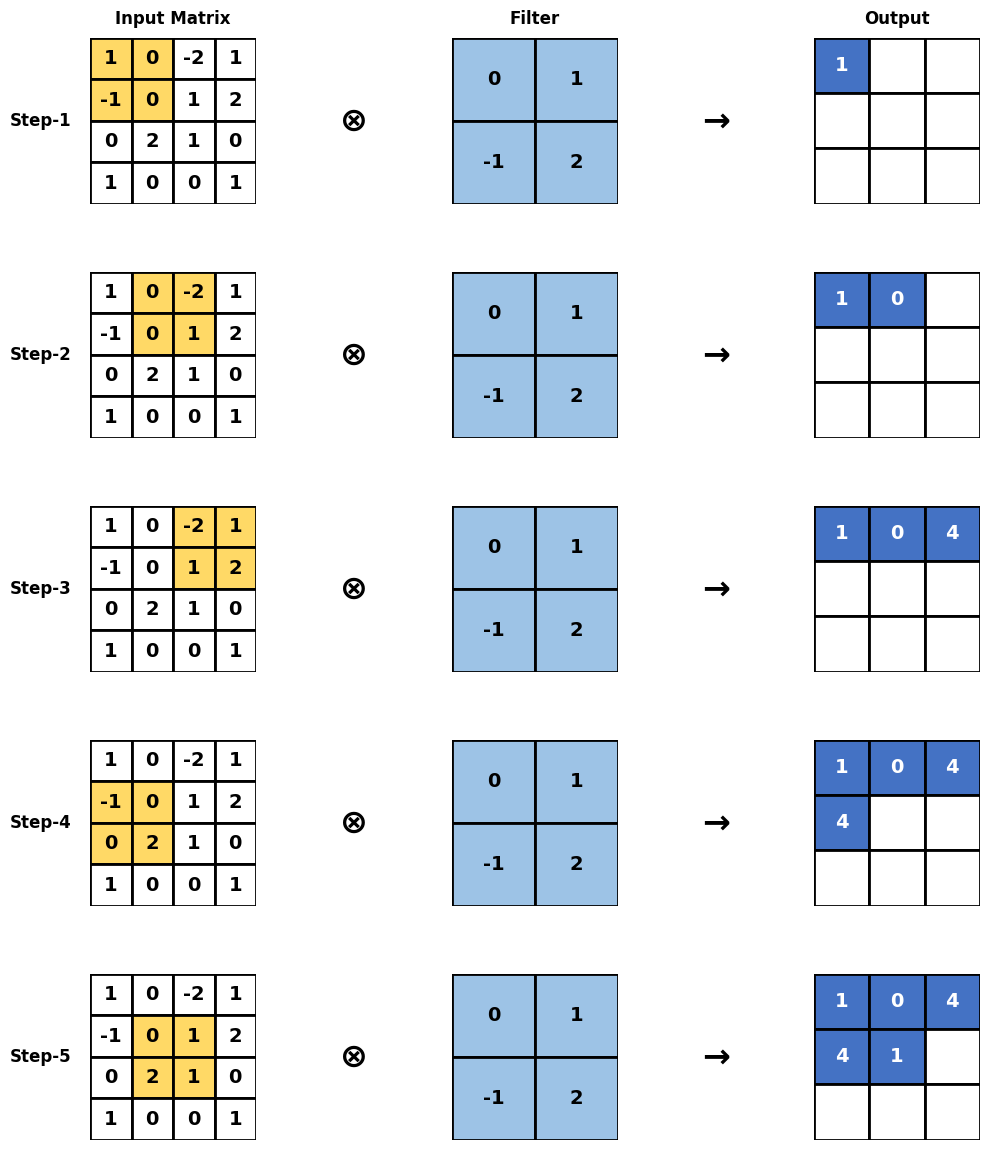
Calculations for each step:
Step 1: (1*0) + (0*1) + (-1*-1) + (0*2) = 1
Step 2: (0*0) + (-2*1) + (0*-1) + (1*2) = 0
Step 3: (-2*0) + (1*1) + (1*-1) + (2*2) = 4
Step 4: (-1*0) + (0*1) + (0*-1) + (2*2) = 4
Step 5: (0*0) + (1*1) + (2*-1) + (1*2) = 1
De convolutionele filter fungeert als een soort “lens” die over de input bewogen wordt.
Vaak wordt de input aangevuld met constante waarden (meestal 0) om bij de output gelijke dimensies als bij de input te krijgen. Dit proces wordt padding genoemd.
Source
visualize_padding()Output
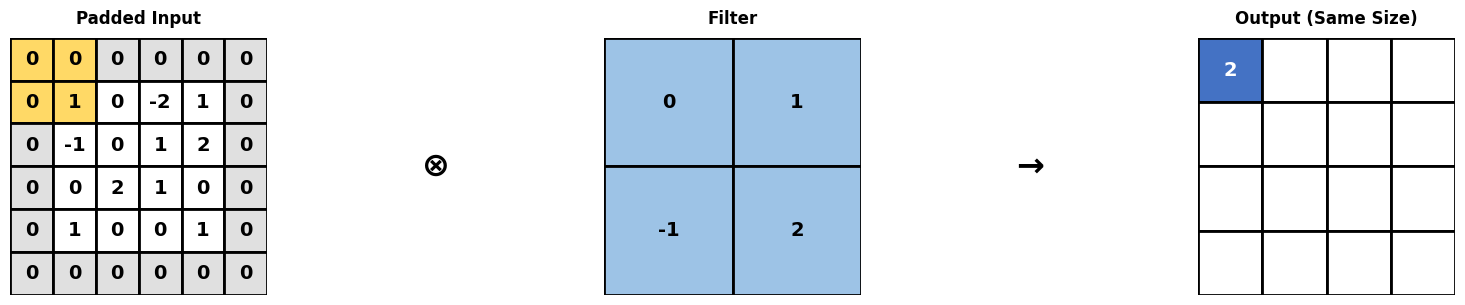
Calculation: (0*0) + (0*1) + (0*-1) + (1*2) = 2
De grootte van de stappen waarmee de filter verschoven wordt, noemt men de stride.
Source
visualize_stride_comparison()Output
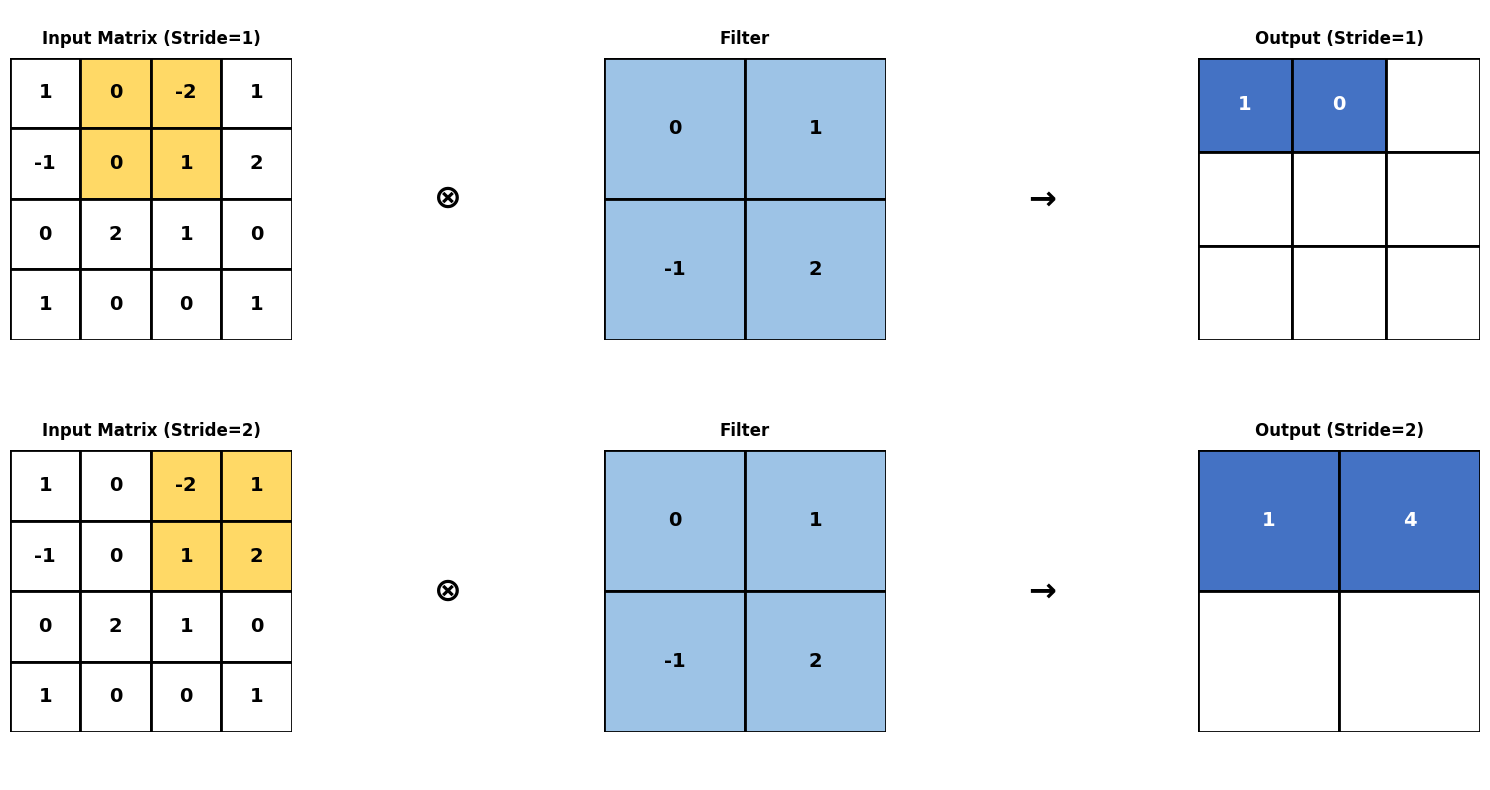
Stride=1, Step 2:
(0*0) + (-2*1) + (0*-1) + (1*2) = 0
Stride=2, Step 2:
(-2*0) + (1*1) + (1*-1) + (2*2) = 4
Niet-convolutionele lagen
Convolutionele lagen worden afgewisseld met andere laagtypes waarin andere tensoroperaties toegepast worden. Ze vormen samen een meerlagige (“diepe”; deep) structuur. Voorbeelden van niet-convolutionele lagen/operaties zijn:
Rectificatie via lineaire units (ReLU):
Pooling: Downsampling via aggregatie (bv. max pooling)
Drop out: Random uitschakelen van connecties
enz.
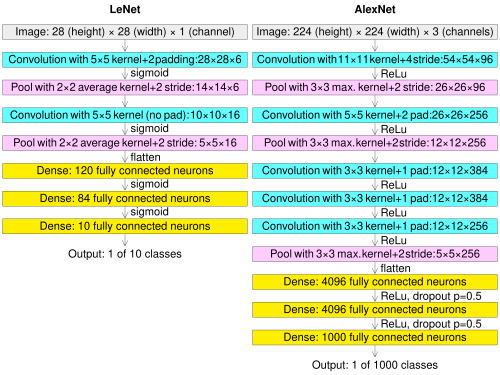
Source
# visualize ReLU and Sigmoid activation functions
visualize_activation_functions()
Output
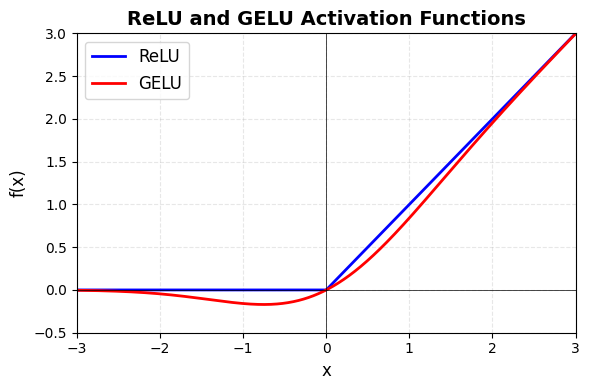
Source
# visualise max pooling operation
visualize_max_pooling()Output
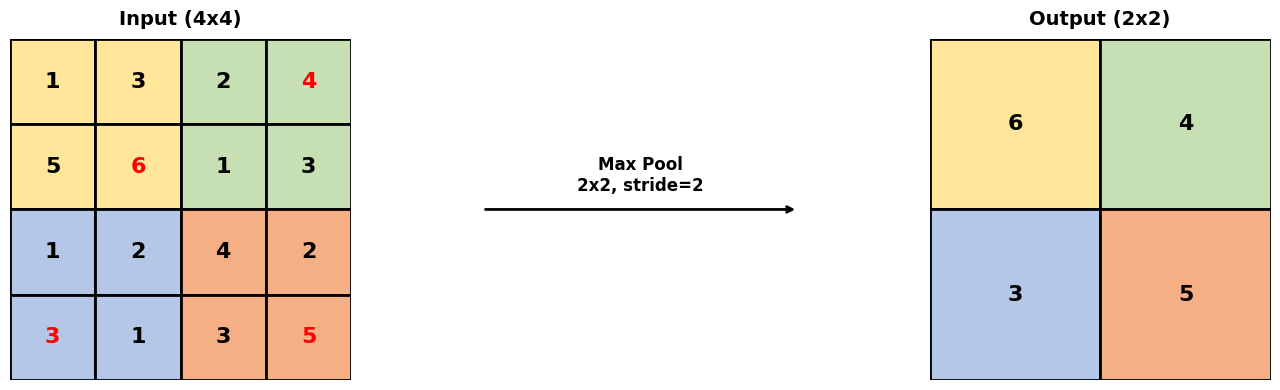
Max Pooling Calculations (2x2 with stride 2):
Top-left region: max([1 3 5 6]) = 6
Top-right region: max([2 4 1 3]) = 4
Bottom-left region: max([1 2 3 1]) = 3
Bottom-right region: max([4 2 3 5]) = 5
🌍 Online CNN demo #1

Parameters¶
De convolutionele kernels zijn het voorwerp van training en hun elementen zijn de belangrijkste parameters van het model. Merk op dat iedere kernel ongewijzigd wordt toegepast op alle secties van de input. Iedere kernel heeft een maximale output bij zijn eigen specifieke patroon. Het zijn dus echte pattern matching devices. Naargelang de specifieke CNN architectuur zijn er nog bijkomende parameters, zoals lineaire gewichten bij fully connected output lagen.
🌍 Online CNN demo #2
Features¶
Bij traditionele beeldsensoren zijn alle pixels van een beeld of beelden de input features voor een computer vision model. Er gebeurt geen selectie van pixels, al kan er wel beslist worden om beelden te vervormen (vaak om meer variatie in de dataset te brengen):
Crop: Er worden nieuwe beelden gemaakt via uitsnijding.
Rotatie: Beelden worden onder verschillende hoeken gedraaid.
Spiegelbeelden
Schaling
enz.
Naargelang de specifieke sensor, zijn er per pixel andere kanalen (channels) beschikbaar. Daar gebeuren soms wel selecties en/of transformaties. Bij standaard sensoren hebben we drie kanalen: rood, groen en blauw (RGB). Soms is er slechts één kanaal (bv. Röntgen scans of RGB beelden die omgezet worden in grijswaarden). Via fusion met andere sensoren is er soms een extra kanaal met diepte-informatie (RGB-D). Bij hyper-spectrale beeldvorming zijn er honderden kanalen (overeenkomstig met verschillende golflengtes in het lichtspectrum) en wordt vaak gefocust op bepaalde banden (bv. infrarood).
🌍 Hyper-spectrale beeldvorming

Tenslotte wordt bij bepaalde toepassingen ook gewerkt met point clouds - voornamelijk afkomstig van LiDAR sensoren. Hier zijn specifieke uitdagingen omdat het om sparse 3D features gaat.
🌍 LiDAR
Leeralgoritme¶
Parameteroptimalisatie gebeurt iteratief via een vorm van stochastische gradient descent (SGD) met zogenaamde backpropagation [1].
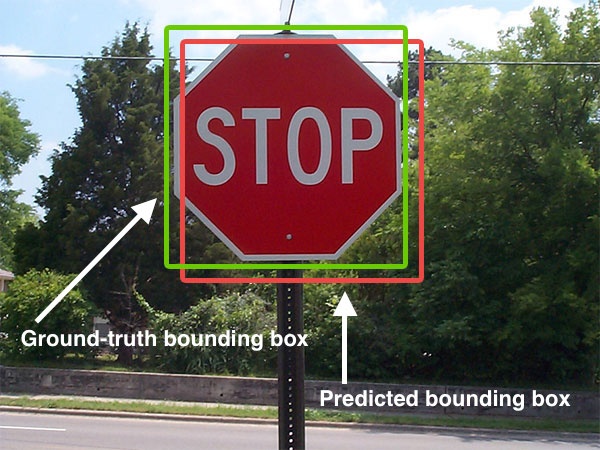
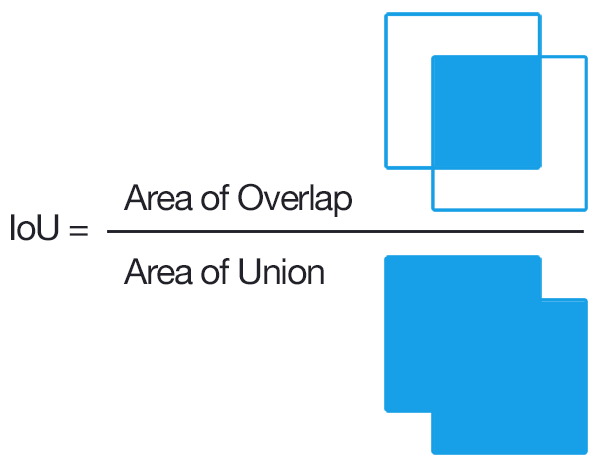
Er bestaat veel variatie in loss functies. Bij classificatie wordt bijvoorbeeld vaak gewerkt met cross-entropy (de “afstand” tussen output en target class probabilities), terwijl er voor objectdetectie kan gewerkt worden met de Intersection over Union.
Intersection over Union
Variabiliteit¶
Beelden zijn inherent complex en variabel - zeker wanneer ze niet uit een gecontroleerde setting afkomstig zijn:
Schaalgrootte: Zelfde objecten kunnen op heel verschillende afstanden van de camera staan en dus grote variaties in schaal vertonen
Rotatie en perspectief: Objecten kunnen gedraaid zijn of vanuit verschillende hoeken bekeken worden
Belichting: Lichtomstandigheden kunnen sterk variëren (dag/nacht, binnen/buiten, schaduwen)
Occlusie: Objecten kunnen gedeeltelijk achter andere objecten verborgen zijn
Achtergrond: Complexe achtergronden maken het onderscheiden van objecten moeilijk
Resolutie: Zelfde objecten kunnen ook afhankelijk van de resolutie van de sensoren heel anders in beeld komen
Optische lens: Een lens kan voor onscherpte zorgen, maar ook specifieke vervormingen (bv. fish eye lenzen)
🌍 Fish-Eye Lens

Wanneer het belangrijk is voor de use-case om dezelfde objecten te kunnen herkennen op verschillende afstanden, bij verschillende belichting, enz. , moet er extra aandacht gaan naar het weerspiegelen van de juiste variabiliteit in de trainingsdata. Het is in die context niet verwonderlijk dat de meest performante modellen voor beeldanalyse in the wild afkomstig zijn van internetgiganten met rechtstreekse toegang tot enorme hoeveelheden natuurlijk beeldmateriaal zoals Google en Meta. In gecontroleerde settings zoals productielijnen wordt samen met een camerasensor ook specifieke belichting voorzien om variabiliteit te verkleinen.
🌍 Belichting
Taken¶
Computer vision modellen worden voor verschillende taken gebruikt. In veel gevallen wordt een zelfde basis CNN-architectuur (model backbone) gebruikt en wordt enkel de toplaag of -lagen (model head) ingewisseld voor taak-specifieke noden.
Klassificatie¶
Het model moet leren om beelden in hun geheel te categoriseren (binair of multi-class). Dit is één van de fundamentele taken in computer vision waarbij het hele beeld één label krijgt.
🌍
Objectdetectie¶
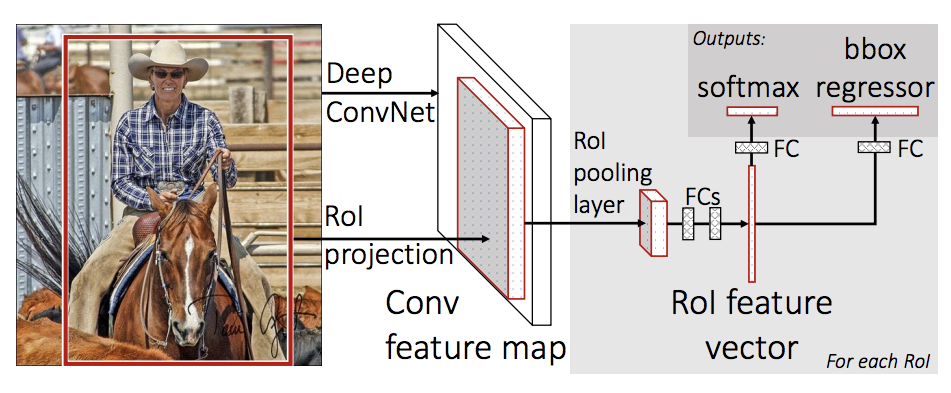
Het model moet leren om objecten te labelen én te lokaliseren binnen beelden aan de hand van bounding boxes. Er bestaan verschillende varianten die op geheel andere wijze tot detecties komen.
🌍
Semantische segmentatie¶
Het model moet leren om op het niveau van pixels class labels toe te kennen. Er wordt geen onderscheid gemaakt tussen verschillende instanties van eenzelfde klasse.

Instance segmentatie¶
Hier maakt het model voorspellingen over de exacte begrenzing ieder object op pixelniveau.
🌍

Key point detectie¶
Het model moet specifieke anatomische of structurele punten lokaliseren in beelden, zoals gewrichten bij mensen of knooppunten bij objecten.
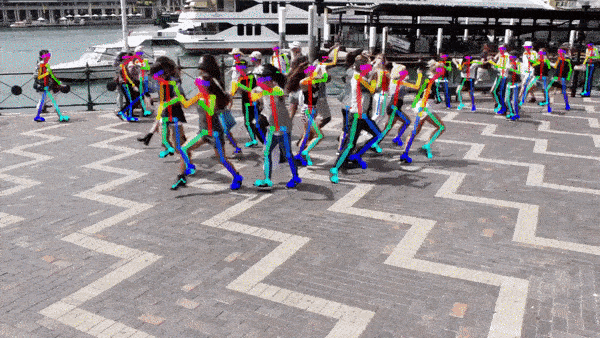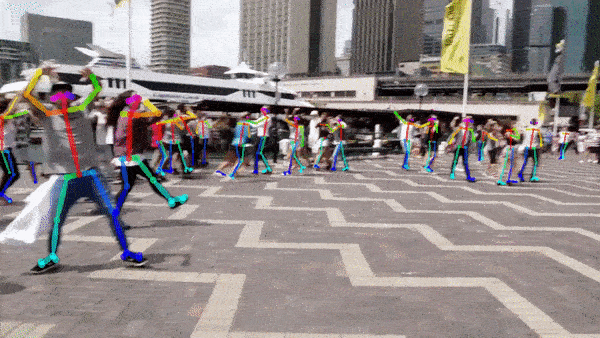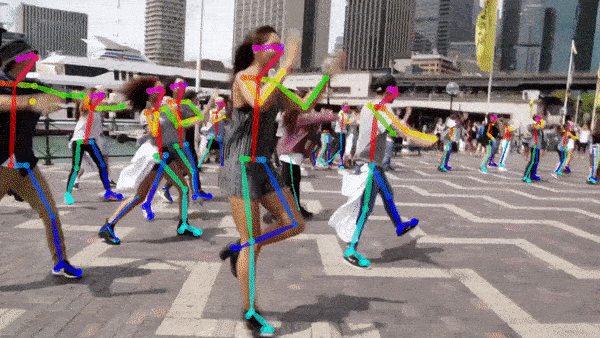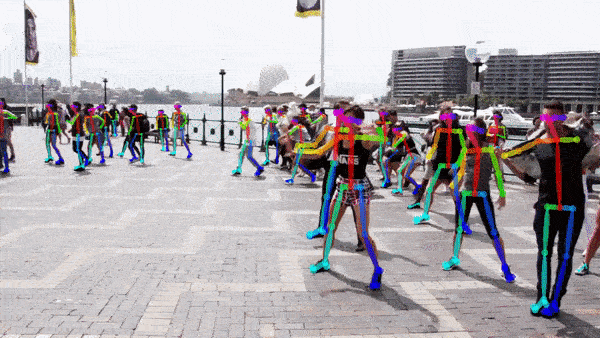
Diepteschatting¶
Het model moet inschatten hoe ver objecten van de camera verwijderd zijn door zogenaamde depth maps te voorspellen
🌍
Voorbeeld:
Depth Anything


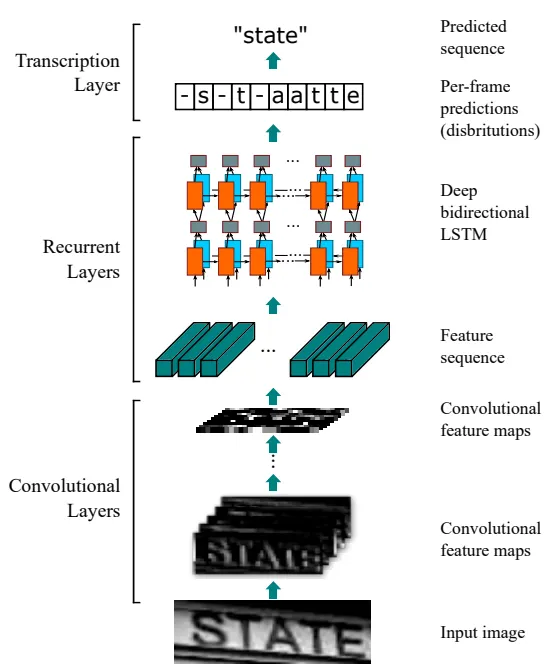
Text detection¶
Het model moet tekstuele regio’s in beelden detecteren en lokaliseren (zonder de tekst zelf te herkennen). Dit is vaak de eerste stap in een OCR-pipeline.
🌍

Optical Character Recognition (OCR)¶
Het model moet tekst in beelden herkennen en transcriberen naar machine-leesbare tekst.
🌍
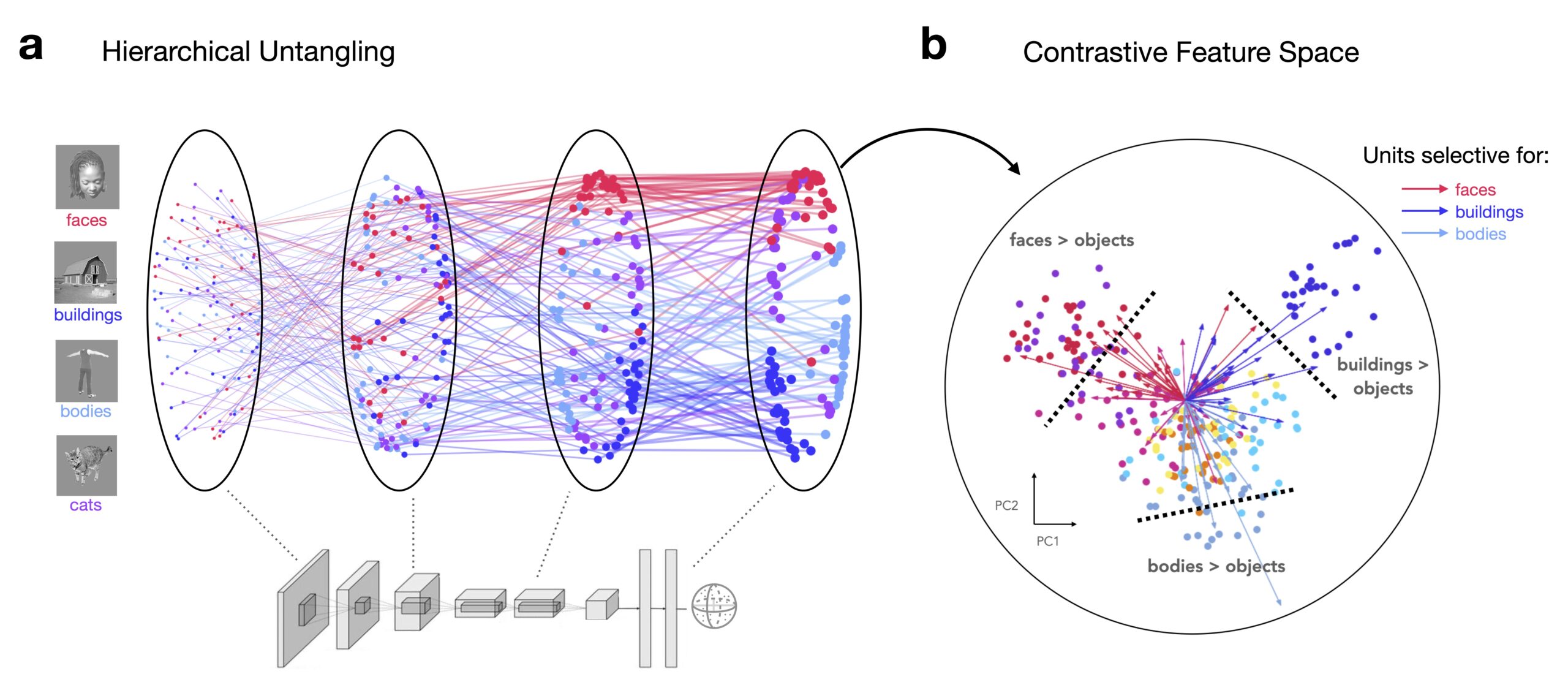
Representation learning¶
Het model leert algemene beeldrepresentaties (ook embeddings genoemd) die nuttig zijn voor diverse downstream taken, zoals vector similarity search en few-/zero-shot klassificatie.
🌍
Ervaring¶
Supervised learning¶
Supervised learning is heel lang de gouden standaard geweest om CNNs te trainen. Het verkrijgen van targets of zogenaamde ground truth data (class labels, bounding boxes, segmentatie polygonen, keypoints, captions enz.) is echter niet vanzelfsprekend zoals bij het voorspellen van huisprijzen. Dit proces heet beeldannotatie. De grote doorbraken in vision AI zijn er gekomen dankzij enorme investeringen in annotatie door grote internetbedrijven.
🌍 Beeldannotatie
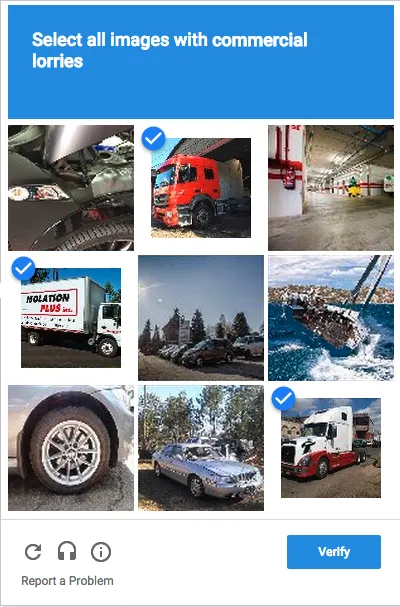
Er bestaan verschillende annotatieplatformen om beeldannotatie minder arbeidsintensief en meer betrouwbaar te maken (bv. het oorspronkelijk Belgische segments.ai).
Er zijn ook slimme applicaties om via crowdsourcing geannoteerde beelden te bekomen.
Afhankelijk van de taak bestaan er verschillende publieke geannoteerde dataset die ook fungeren als gestandaardiseerde benchmarks:
ImageNet: Een iconische dataset voor klassificatie met ~14 miljoen beelden verdeeld over 20.000+ categorieën.
COCO (Common Objects in Context): ~330.000 beelden met meer dan 200.000 gelabelde objecten in 80 categorieën. Bevat ook annotaties voor segmentatie, keypoints en captioning.
Cityscapes: 25.000 beelden van straten met pixel-level annotaties voor 30 klassen (voertuigen, voetgangers, wegen, etc.)
Street View Text: Beelden van Google Street View met tekstannotaties voor scene text recognition.
ChestX-ray14: 112.000 röntgenfoto’s van de borst met labels voor 14 pathologieën.
Waymo Open Dataset: ~1000 rijsegmenten (elk ~20 seconden); Hoge-resolutie camera beelden (5 camera’s); LiDAR point clouds; 3D bounding box annotaties voor voertuigen, voetgangers, fietsers en verkeersborden; ~12 miljoen 3D labels
enz.
Transfer learning en fine tuning¶
Om een goede performantie te krijgen, zeker bij natuurlijk beeldmateriaal, zijn voor supervised learning heel veel geannoteerde trainingsdata nodig en bijgevolg ook veel trainingstijd. Omdat veel grote getrainde modellen open-source beschikbaar zijn, wordt in de praktijk vaak met transfer learning gewerkt. Transfer learning betekent dat je een model dat reeds getraind is op een hele grote dataset (bijvoorbeeld ImageNet) hergebruikt voor een nieuwe, gerelateerde taak. Het basisidee is dat de vroege lagen van een CNN generieke features leren (randen, texturen, kleuren) die nuttig zijn voor veel verschillende taken, terwijl de latere lagen meer taak-specifieke features leren. In de praktijk komt dit neer op het vervangen de laatste taak-specifieke laag/lagen in het netwerk (de model head; bv. een lineaire regressielaag). Dit heeft als voordeel dat je doorgaans met een veel kleinere geannoteerde dataset een goede performantie kan bekomen. Dit fenomeen heet few-shot, of in het extreme geval, zero-shot learning.
Fine tuning is een gerelateerde aanpak waarbij onderste (feature-extractie) lagen worden bij-getraind (vertrekkende van hun vooraf getrainde waarden).
Self-supervision¶
De jongste jaren is er meer en meer aandacht voor training op basis van self-supervision. Hierbij wordt algemeen gesproken met een niet-geannoteerde dataset gewerkt van waaruit toch een supervised learning procedure wordt bekomen door surrogaat labels te creëren. Een specifiek voorbeeld hiervan is contrastive learning. Voor iedere input worden getransformeerde varianten gemaakt. Het model wordt dan getraind met een loss functie die de afstand tussen output tensors minimaliseert bij die varianten. Daarnaast wordt de afstand tussen output tensors gemaximaliseerd bij twee verschillende inputbeelden. Na een dergelijke generieke trainingsfase wordt dan in een tweede fase via transfer learning of fine tuning, met een kleine set geannoteerde beelden een taakspecifiek model getraind.
Evaluatie¶
Afhankelijk van de taak zijn er een aantal specifieke score metrics gangbaar in de context van computer vision.
Klassificatie¶
Voor klassificatie wordt naar standaard score metrics gekeken zoals accuracy, precision, recall, F-scores
Objectdetectie¶
Intersection over Union (IoU) of Jaccard Index: Meet de overlap tussen voorspelde en ground truth bounding boxes.
Mean Average Precision (mAP): Combineert zowel de nauwkeurigheid van detecties als de volledigheid ervan.
Segmentatie¶
Pixel Accuracy: Percentage correct geclassificeerde pixels
Mean Intersection over Union (mIoU): Gemiddelde IoU over alle klassen
Dice Coefficient: Meet de overlap tussen predicted en ground truth segmentaties. Vergelijkbaar met IoU maar geeft meer gewicht aan true positives.
Key point detectie¶
Percentage of Correct Key points (PCK): Percentage key points binnen een tolerantieafstand.
Mean Per Joint Position Error (MPJPE): Gemiddelde Euclidische afstand tussen voorspelde en ground truth key points.
OCR¶
Character Error Rate (CER): Percentage foutief voorspelde karakters/woorden.
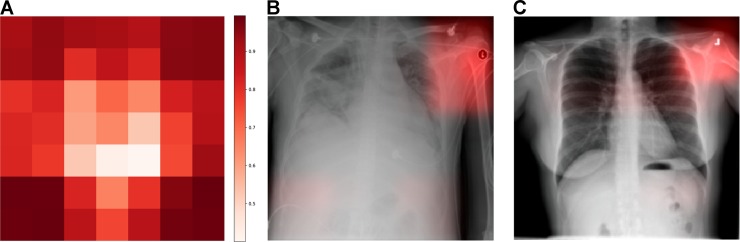
Explainability¶
Deep learning modellen zijn alomtegenwoordig voor computer vision taken. Dit type modellen zijn echter in grote mate black boxes. Het is heel moeilijk om model parameters te interpreteren en bijgevolg om te begrijpen hoe een specifieke modeloutput tot stand komt. Hierdoor ontstaat ook een ernstig risico op model artefacten.
🌍

Voordelen¶
Flexibel gebruik in verschillende domeinen
Hergebruik/finetuning mogelijk met kleine datasets
Nadelen¶
Computationeel zwaar: Kan geaccelereerd worden met GPUs/TPUs/enz., maar deze infrastructuur is zeer kostelijk. Zeker wanneer er (near) realtime beeldverwerking gewenst is (zoals bij bewakingscamera’s) kan dit praktisch zeer uitdagend zijn.
Interpreteerbaarheid: Complexe, ontransparante modelarchitectuur - weliswaar zijn technieken ontwikkeld om inzicht te krijgen in feature maps
Heel veel data en trainingstijd voor nieuwe domeinen
🌍 Quantization
Om near realtime te kunnen werken wordt, naast hardware-accelerators (GPU/TPU/enz.), een beroep gedaan op speciaal ontworpen “kleine” CNN architecturen (bv. MobileNet) die op relatief lage input resoluties werken. Daarnaast wordt er ook vaak quantization toegepast op de parameters. Quantization houdt algemeen in dat de precisie van parameters na het trainen wordt verlaagd (bv. int8 in plaat van float32).
Foundation Modellen¶
De laatste jaren is de flexibiliteit van computer vision modellen nog veel groter geworden door de komst van zogenaamde foundation modellen. Dit zijn doorgaans zeer omvangrijke (large) modellen die met enorme hoeveelheden beelden getraind zijn met ook verschillende taken (object detectie, segmentatie, captioning enz.). Ze hebben een enorme generalisatie capaciteit. Dit wil zeggen dat ze erg goede performantie behalen bij ongezien data. AI engineers kunnen daardoor meer en meer een beroep doen op vooraf getrainde of pre-trained modellen die zonder of met minimale extra training ingezet kunnen worden.
Source
import random
from PIL import Image, ImageDraw
from transformers import AutoModelForCausalLM, AutoProcessor
Source
model_id = "microsoft/Florence-2-base"
model = AutoModelForCausalLM.from_pretrained(
model_id, attn_implementation="eager", trust_remote_code=True
)
processor = AutoProcessor.from_pretrained(model_id, trust_remote_code=True)
Output
Source
def run_example(task_prompt, text_input=None):
"""Run Florence model inference on an image with a given task prompt.
Args:
task_prompt: The task prompt for the model (e.g., '<CAPTION>', '<OBJECT_DETECTION>')
text_input: Optional additional text input to append to the task prompt
Returns
-------
Parsed answer from the model based on the task prompt
"""
image = Image.open("../../../img/all_models_are_wrong.jpg").convert("RGB")
prompt = task_prompt if text_input is None else task_prompt + text_input
inputs = processor(text=prompt, images=image, return_tensors="pt")
# Generate with use_cache=False to avoid past_key_values issues
generated_ids = model.generate(
input_ids=inputs["input_ids"],
pixel_values=inputs["pixel_values"],
max_new_tokens=1024,
do_sample=False,
use_cache=False,
)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=False)[0]
parsed_answer = processor.post_process_generation(
generated_text, task=task_prompt, image_size=(image.width, image.height)
)
return parsed_answer# Example usage for image captioning
caption = run_example("<CAPTION>")
print("Generated Caption:", caption)Generated Caption: {'<CAPTION>': 'A black and white photo of a man with glasses.'}
Source
def plot_bbox(data):
"""Plot bounding boxes on an image.
Args:
image: The image to display
data: Dictionary containing 'bboxes' and 'labels' keys
"""
# Create a figure and axes
fig, ax = plt.subplots()
# Display the image
image = Image.open("../../../img/all_models_are_wrong.jpg").convert("RGB")
ax.imshow(image)
# Plot each bounding box
for bbox, label in zip(data["bboxes"], data["labels"], strict=False):
# Unpack the bounding box coordinates
x1, y1, x2, y2 = bbox
# Create a Rectangle patch
rect = patches.Rectangle(
(x1, y1), x2 - x1, y2 - y1, linewidth=1, edgecolor="r", facecolor="none"
)
# Add the rectangle to the Axes
ax.add_patch(rect)
# Annotate the label
plt.text(x1, y1, label, color="white", fontsize=8, bbox={"facecolor": "red", "alpha": 0.5})
# Remove the axis ticks and labels
ax.axis("off")
# Show the plot
plt.show()
# Example usage for object detection
detection = run_example("<DENSE_REGION_CAPTION>")
plot_bbox(detection["<DENSE_REGION_CAPTION>"])
# Example usage for Optical Character Recognition (OCR)
ocr = run_example("<OCR>")
print("Detected text:", ocr)Detected text: {'<OCR>': 'All models are wrongbut some are usefulGeorge E.P. Box'}
Source
def draw_ocr_bboxes(prediction, scale=1):
"""Draw OCR bounding boxes on an image.
Args:
image: PIL Image object to draw on
prediction: Dictionary containing 'quad_boxes' and 'labels' keys
scale: Scale factor for bounding box coordinates (default: 1)
"""
image = Image.open("../../../img/all_models_are_wrong.jpg").convert("RGB")
draw = ImageDraw.Draw(image)
bboxes, labels = prediction["quad_boxes"], prediction["labels"]
colormap = [
"red",
"blue",
"green",
"purple",
"orange",
"yellow",
"pink",
"cyan",
"magenta",
"lime",
]
for box, label in zip(bboxes, labels, strict=False):
color = random.choice(colormap)
new_box = (np.array(box) * scale).tolist()
draw.polygon(new_box, width=3, outline=color)
draw.text((new_box[0] + 8, new_box[1] + 2), f"{label}", align="right", fill=color)
display(image)ocr_with_region = run_example("<OCR_WITH_REGION>")
draw_ocr_bboxes(ocr_with_region["<OCR_WITH_REGION>"])
Vision Transformers¶
Vision Transformers (ViTs) hebben in de voorbije jaren een belangrijke verschuiving in computer vision teweeg gebracht. In tegenstelling tot traditionele Convolutional Neural Networks (CNN’s), die werken met hiërarchische convolutionele filters voor feature-extractie, passen ViTs het transformer-mechanisme toe dat oorspronkelijk ontwikkeld werd voor natuurlijke taalverwerking (NLP).
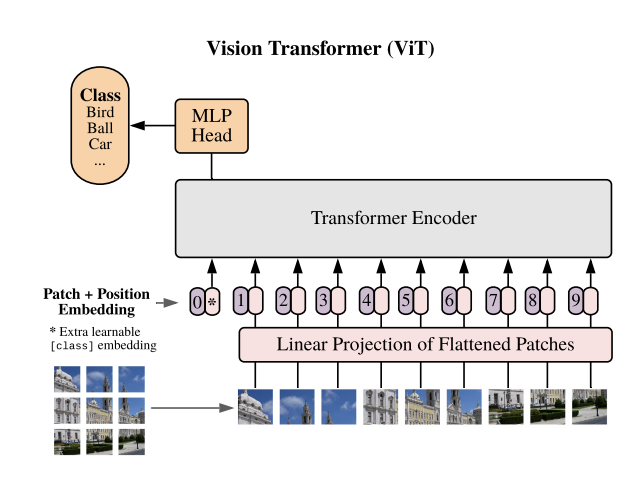
Het kernidee achter ViTs is verrassend eenvoudig: een afbeelding wordt behandeld als een reeks patches, vergelijkbaar met hoe een zin wordt opgedeeld in woorden/tokens.
De stappen zijn als volgt:
Patch-creatie: De invoer-afbeelding wordt opgedeeld in kleine, vierkante patches (bijvoorbeeld 16×16 pixels). Elke patch wordt vervolgens “platgemaakt” tot een eendimensionale vector.
Lineaire embedding: Elke patch-vector wordt door een lineaire laag geprojecteerd naar een hogerdimensionale ruimte, waardoor een reeks embeddings ontstaat.
Positie-informatie: Omdat transformers niet automatisch de volgorde van patches kennen, worden positionele coderingen toegevoegd aan elke embedding. Dit behoudt informatie over de ruimtelijke positie van elke patch in de oorspronkelijke afbeelding. Dit komt overeen met positionele encoding van tokens bij NLP transformers.
Classificatie-token: Om een eengemaakte representatie van de input te bekomen, wordt een speciaal learnable token (het [CLS] token) aan het begin van de reeks patch embeddings toegevoegd. Na verwerking door het transformer netwerk wordt deze token gebruikt voor classificatietaken.
De reeks patch embeddings wordt verwerkt door een transformer encoder, die bestaat uit meerdere lagen met drie hoofdcomponenten:
Self-attention mechanisme: Dit is het hart van de transformer architectuur. Het stelt het model in staat om dynamisch het belang van elke patch te wegen ten opzichte van alle andere patches. Hierdoor kan het model zowel lokale als globale afhankelijkheden in de afbeelding herkennen.
Multi-head attention: In plaats van één enkel attention-mechanisme, gebruikt het model meerdere “attention heads” parallel. Elke head kan zich richten op verschillende aspecten of regio’s van de afbeelding.
Feed-forward netwerken: Na de attention-lagen worden de embeddings verder verwerkt door feed-forward neurale netwerken, die complexere patronen kunnen leren.
Parameters¶
Er zijn veel meer verschillende soorten parameters dan bij CNNs:
Q, K, V matrices (Query, Key, Value): Drie grote gewichtsmatrices per attention head die bepalen hoe patches naar elkaar “kijken”
Multi-head attention projecties: Matrices om outputs van meerdere heads te combineren
Patch embedding matrix: Transformeert raw patches naar embeddings
Positionele embeddings: Coderen de positie van elke patch (kunnen geleerd worden)
Feed-forward gewichten: Volledig verbonden lagen na attention
[CLS] token: Leerbare classificatie-token
Taken¶
Er is geen verschil ten opzichte van CNNs qua type taken. Wel is het zo dat ViTs van nature erg geschikt zijn om via self-supervision getraind te worden (zoals Language Transformers).
🌍 DINOv3
Het DINOv3 model van Meta is een krachtig embedding-model gebaseerd op de ViT architectuur en volledig via self-supervision getraind. Het produceert zeer rijke features die zelfs voor zeer geavanceerde taken zoals keypoint matching gebruikt kunnen worden.
Voordelen¶
Globaal begrip: ViTs kunnen relaties tussen verafgelegen delen van een afbeelding vastleggen vanaf de vroegste lagen, wat nuttig is voor taken die een holistisch begrip vereisen. Dit wijkt af van traditionele CNNs waar de hiërarchische structuur impliceert dat systematische relaties tussen verafgelegen delen enkel op hogere niveaus geleerd kunnen worden.
Flexibiliteit: Het ontbreken van sterke architecturale beperkingen maakt ViTs aanpasbaar voor diverse (geavanceerde) taken en modaliteiten.
Schaalbaarheid: Prestaties verbeteren consistent wanneer modellen groter worden en meer data beschikbaar is.
Nadelen¶
Data-intensief: ViTs hebben vaak enorm grote datasets nodig (miljoenen afbeeldingen) om goed te presteren.
Rekenintensief: Het self-attention mechanisme heeft kwadratische complexiteit, wat leidt tot hoge geheugen- en rekenvereisten, vooral bij hoge resoluties.
Interpreteerbaarheid: Het analyseren van het gedrag is nog moeilijker dan bij CNNs omdat er ook geen feature maps aan te pas komen.
Gevoeligheid voor transformaties: ViTs kunnen minder robuust zijn voor ruimtelijke transformaties (rotatie, spiegeling) tenzij expliciet getraind op dergelijke variaties.
Zie cursus Mathematical Foundations.
- Zech, J. R., Badgeley, M. A., Liu, M., Costa, A. B., Titano, J. J., & Oermann, E. K. (2018). Variable generalization performance of a deep learning model to detect pneumonia in chest radiographs: A cross-sectional study. PLOS Medicine, 15(11), e1002683. 10.1371/journal.pmed.1002683