In dit onderdeel bekijken we de machine learning concepten in de context van gestructureerde data. Gestructureerde data is data die een gestandaardiseerd formaat heeft dat wordt gedefinieerd door een schema. Deze data wordt doorgaans opgeslagen in een tabelformaat met rijen en kolommen, wat het gemakkelijk maakt om te doorzoeken en te analyseren.
Decision Tree modellen¶
Patroonherkenning in gestructureerde (en in bepaalde gevallen ook semi-gestructureerde) data is vaak zeer succesvol met zogenaamde decision tree modellen en voornamelijk de ensemble learning varianten hiervan (zie random forests en gradient boosted trees verder in deze sectie).
Een decision tree model bestaat uit een boomstructuur waarbij iedere vertakking voor een bepaalde feature staat die opgesplitst wordt.
Source
import dtreeviz
import matplotlib
import pandas as pd
from sklearn import tree
from sklearn.datasets import load_iris
from ml_courses.utils import display_dtreeviz
matplotlib.set_loglevel("ERROR")Source
iris = load_iris()
X, y = iris.data, iris.target
clf = tree.DecisionTreeClassifier(random_state=123)
clf = clf.fit(X, y)
viz_model = dtreeviz.model(
clf,
X_train=X,
y_train=y,
feature_names=iris.feature_names,
target_name="Iris type",
class_names=iris.target_names,
)
display_dtreeviz(viz_model.view(orientation="LR", fontname="DejaVu Sans Mono", scale=1.5))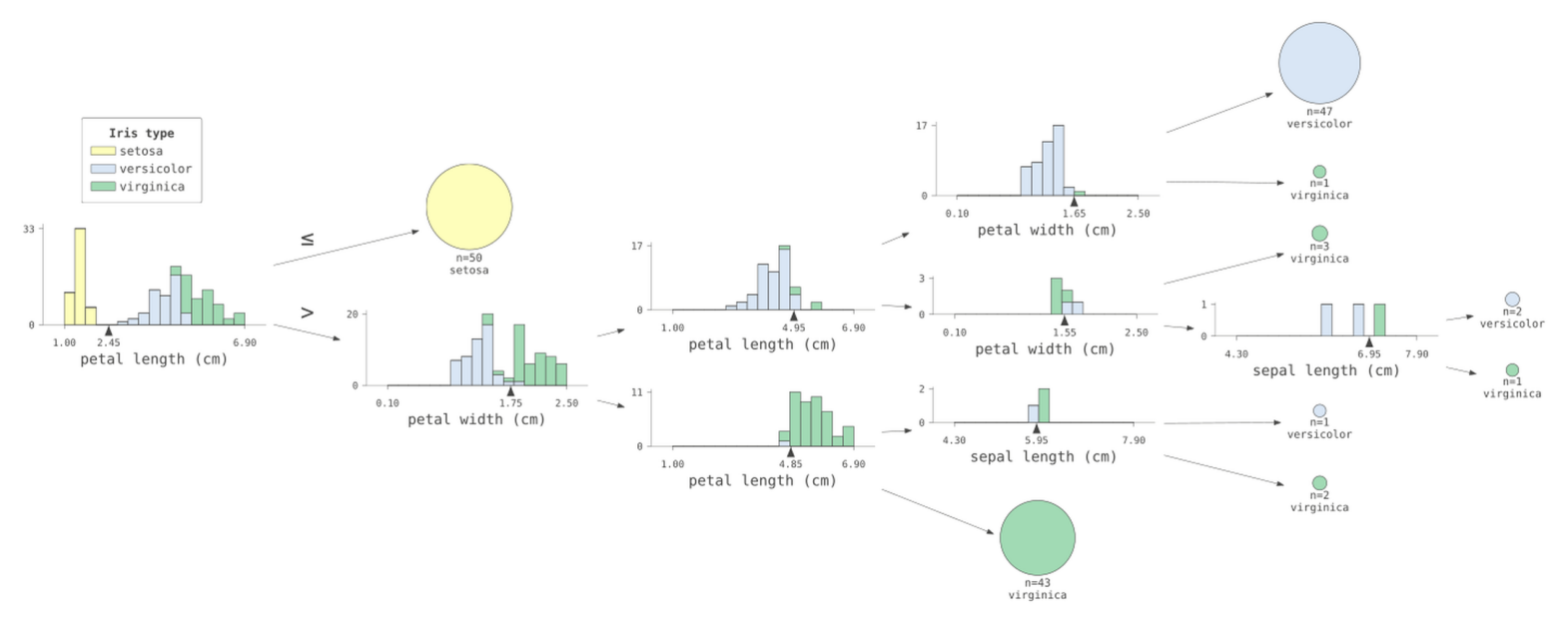
🌍 Iris data
We moeten de boomstructuur als volgt “lezen”:
if petal_length <= 2.45:
return "Setosa"
else:
if petal_width <= 1.75:
if petal_length <= 4.95:
if petal_width <= 1.65:
return "Versicolor"
else:
return "Virginica"
else:
if petal_width <= 1.55:
return "Virginica"
else:
if sepal_length <= 6.95:
return "Versicolor"
else:
return "Virginica"
else:
if petal_length <= 4.85:
if sepal_length <= 5.95:
return "Versicolor"
else:
return "Virginica"
else:
return "Virginica"Parameters¶
De volledige conditionele structuur, zoals hierboven geïllustreerd, vormt de parameters van het model. We weten met andere woorden niet op voorhand met hoeveel parameters we zullen eindigen - of hoe complex het model uiteindelijk zal zijn. Dat heeft het voordeel dat we een heel flexibel model hebben, maar het nadeel dat we goed moeten opletten voor over-complexiteit en over-fitting. Er zijn wel verschillende hyper parameters zoals de maximum diepte van de vertakkingen, het minimum aantal voorbeelden in een vertakking, enz, maar dat verandert niets aan het feit dat we de model complexiteit niet rechtstreeks in de hand hebben.
Features¶
Decision tree modellen kunnen algemeen gesproken flexibel om met veel en heterogene features, wat een typische eigenschap is van gestructureerde data. Ze hebben ook een natuurlijke manier om belangrijke van minder belangrijke features te onderscheiden. Op iedere niveau worden alle features in overweging genomen, maar enkel de meest informatieve wordt gebruikt. Daardoor komen minder informatieve features automatisch naar diepere vertakkingen geduwd en worden niet-informatieve features automatisch geweerd uit het model. Er is dus een natuurlijke feature selectie.
Doordat feature-schalen simpelweg opgedeeld worden binnen de boomstructuur, zijn decision trees ook heel geschikt om niet-lineaire verbanden te herkennen - zonder dat er veel feature engineering aan te pas moet komen.
Tenslotte kunnen decision trees ook vrij gemakkelijk omgaan met missing values. De vaakst gebruikte strategie zijn surrogate splits. Hierbij wordt voor iedere vertakkingsconditie (bv. petal_length <= 2.45) een back-up regel of back-up regels voorzien.
Leeralgoritme¶
Om de optimale vertakkingen te vinden wordt sequentieel gezocht naar de best mogelijke split op een van de features. Er worden bij iedere stap volgens bepaalde (deels random) principes een reeks kandidaat splits opgemaakt. Die kandidaten worden geëvalueerd met betrekking tot de kwaliteit van de predicties op het volgende niveau. Bij classificatie wordt die kwaliteit uitgedrukt in termen van de zuiverheid zijn de predicties met betrekking tot de target categorieën. Bij regressie is het de bedoeling dat een split tot kleinere predictiefouten (gekwadrateerde of absolute verschillen) op het volgende niveau leiden. Er is dus geen sprake van een algemene loss functie, maar wel een lokale loss functie op het niveau van individuele splits. Het leeralgoritme bij decision trees wordt daarom greedy genoemd: er wordt bij iedere tussenstap een optimale keuze gemaakt, maar niet noodzakelijk op een globaal niveau.
Taken¶
Naast klassificatie kunnen decision trees ook voor regressie gebruikt worden
Source
dataset_url = "https://raw.githubusercontent.com/parrt/dtreeviz/master/data/cars.csv"
df = pd.read_csv(dataset_url)
X = df.drop("MPG", axis=1)
y = df["MPG"]
features = list(X.columns)
reg = tree.DecisionTreeRegressor(max_depth=3, criterion="absolute_error")
reg.fit(X.values, y.values)
viz_rmodel = dtreeviz.model(reg, X, y, feature_names=features, target_name="MPG")
viz_rmodel.rtree_feature_space(features=["WGT"])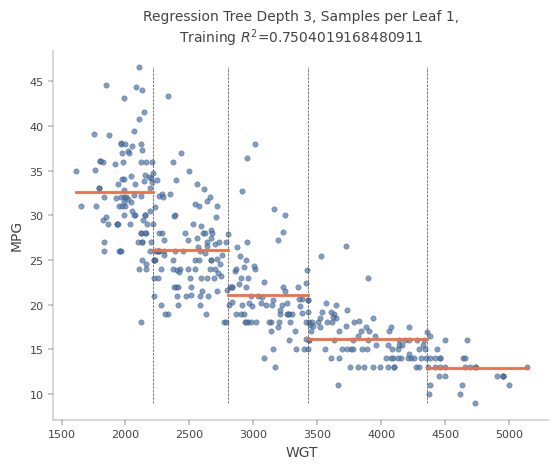
Source
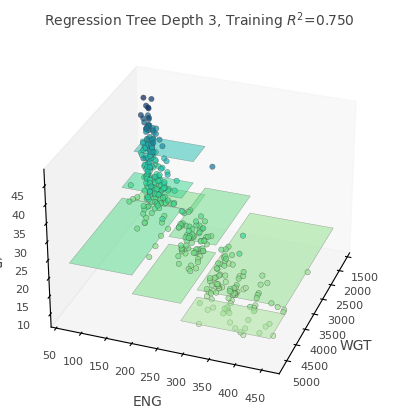
viz_rmodel.rtree_feature_space3D(
features=["WGT", "ENG"],
fontsize=10,
elev=30,
azim=20,
show={"splits", "title"},
colors={"tessellation_alpha": 0.5},
)
Ervaring¶
Het gaat bij decision trees altijd over supervised learning.
Evaluatie¶
Om de performantie van decision trees te evalueren wordt in de eerste plaats gekeken naar de scoring metrics die ook de training sturen (Gini impurity/Entropy/Misclassification rate/MSE/MAR/R²/etc.). Omdat er een reëel gevaar bestaat voor over fitting wordt veel belang gehecht aan de performantie bij ongeziene test data.
Voordelen¶
Interpreteerbaarheid: Iedere vertakking heeft een duidelijke betekenis
Flexibiliteit (oa. ook geschikt voor multi-output problemen)
Computationele efficiëntie omdat er geen globale optimalisatie gebeurt (greedy optimisatie)
Nadelen¶
Greedy optimalisatie geeft geen garantie op een globaal optimale boomstructuur
Onstabiliteit: kleine aanpassingen aan de data kunnen een groot verschil geven in de boomstructuur
Moeite met lineaire relaties: hoewel ze heel goed om kunnen met niet-lineariteit, moeten ze (te) veel splits maken om een niet-lineair verband te leren
Moeite met extrapolatie: ze kunnen enkel splits en predicties maken in de range van de trainingsdata
Over fitting: het aantal parameters kan ongecontroleerd groeien waardoor er over fitting optreedt
Random Forests¶
Het concept van random forests is om verschillende decision trees (een forest) te trainen op verschillende subsets van de data en de output van de individuele modellen te aggregeren in een finale predictie. Het behoort daarom tot de klasse van zogenoemde ensemble leeralgoritmes. Algemeen gesproken, worden bij ensemble technieken predicties van verschillende modellen gecombineerd om tot een betere performantie te komen.
De naam random forests verwijst ook naar het feit dat de methode gebaseerd is op random bootstrap sampling[1]. Voor iedere nieuwe decision tree, wordt een nieuwe dataset gecreëerd door random samples te nemen uit de training data (mét teruglegging zodanig dat er telkens een even grote dataset wordt bekomen als bij de originele trainingsdata). Er wordt doorgaans ook een verschillende subset van de features gebruikt bij elke nieuwe decision tree.
Voordelen¶
Consistentie: Predicties zijn veel beter bestand tegen kleine aanpassingen in de data
Bestand tegen overfitting
Ingebouwde missing value handling
Krachtige off-the-shelve oplossing voor veel complexe predictieproblemen
Parallellisatie: verschillende decision trees kunnen onafhankelijk van elkaar getraind worden (zie bv. SparkMLlib)
Nadelen¶
Verlies van interpreteerbaarheid
Trage inference: alle individuele trees moeten eerst een predictie maken.
Grote opslag/geheugen nodig
Trage training
Complexere hyper parameter tuning
Source
from sklearn import ensemble
X, y = iris.data, iris.target
clf = ensemble.RandomForestClassifier(
n_estimators=50, # Number of trees in the forest
max_depth=5, # Maximum depth of the trees
random_state=42, # Seed for reproducibility
)
clf = clf.fit(X, y)Source
clf.estimators_[:10][DecisionTreeClassifier(max_depth=5, max_features='sqrt',
random_state=1608637542),
DecisionTreeClassifier(max_depth=5, max_features='sqrt',
random_state=1273642419),
DecisionTreeClassifier(max_depth=5, max_features='sqrt',
random_state=1935803228),
DecisionTreeClassifier(max_depth=5, max_features='sqrt', random_state=787846414),
DecisionTreeClassifier(max_depth=5, max_features='sqrt', random_state=996406378),
DecisionTreeClassifier(max_depth=5, max_features='sqrt',
random_state=1201263687),
DecisionTreeClassifier(max_depth=5, max_features='sqrt', random_state=423734972),
DecisionTreeClassifier(max_depth=5, max_features='sqrt', random_state=415968276),
DecisionTreeClassifier(max_depth=5, max_features='sqrt', random_state=670094950),
DecisionTreeClassifier(max_depth=5, max_features='sqrt',
random_state=1914837113)]Gradient Boosted trees¶
Boosting is een algemene ensemble-techniek waarbij de modellen in het ensemble niet onafhankelijk van elkaar (in parallel) gebouwd worden, maar sequentieel. Elk nieuw model in de reeks wordt getraind om de fouten van het voorafgaande model te corrigeren. Dit iteratieve proces stelt het globale ensemble-model in staat om zijn nauwkeurigheid te verbeteren door te focussen op moeilijk te voorspellen voorbeelden. Er bestaan verschillende varianten, maar Gradient Boosting levert tegenwoordig vaak de beste resultaten op. Bij deze techniek starten we met een eenvoudig initieel model (bv. het gemiddelde van de target bij regressie). Dan wordt iteratief telkens in 3 stappen gewerkt:
De gradiënt van de loss functie wordt berekend naar iedere input. Bij een regressieprobleem met een loss komt dit neer op de negatieve residuals: .
Die gradiënt vormt de target voor een volgend nieuw model.
De predicties van het nieuwe model worden bij de predicties in de vorige stap geteld (gewogen met een learning rate hyper parameter). Op deze manier worden de predictiefouten stelselmatig kleiner en kleiner.
Voordelen¶
Accuraatheid: Gradient Boosting is algemeen gesproken één van de meest accurate algoritmes voor (semi-)gestructureerde data. Het doet het vaak beter dan random forests omdat bij die laatste, onafhankelijke decision trees worden getraind. Iedere individuele tree is dan onderhevig aan dezelfde predictiefouten, terwijl bij gradient boosting iedere tree leert uit de fouten van de voorgaande trees.
Gebalanceerd leren: Trees richten zich op de moeilijk te voorspellen gevallen. Wanneer dit samenhangt met imbalances in de data, resulteert dit in een natuurlijke beveiliging tegen bias.
Flexibiliteit: Kan met eender welke loss functie werken zolang die differentieerbaar is.
Efficiënt: Resulteert vaak in kleinere ensembles
Source
from xgboost import XGBClassifier
clf = XGBClassifier()
clf = clf.fit(X, y)
print(f"\nNumber of boosted rounds: {clf.get_booster().num_boosted_rounds()}")
print(f"Number of features: {clf.n_features_in_}")
print(f"Classes: {clf.classes_}")
print("\nFeature importance (gain):")
importance_dict = clf.get_booster().get_score(importance_type="gain")
for feature, importance in sorted(importance_dict.items(), key=lambda x: x[1], reverse=True):
print(f" {feature}: {importance:.4f}")
Number of boosted rounds: 100
Number of features: 4
Classes: [0 1 2]
Feature importance (gain):
f2: 2.9918
f3: 1.3149
f1: 0.0727
f0: 0.0424
Bootstrapping is een algemenere statistische techniek om de distributie van schatters, zoals het gemiddelde, via sampling (meestal met teruglegging) te empirisch bepalen.